Can Vision Replace Text in Working Memory? Evidence from Spatial n-Back in Vision-Language Models
作者: Sichu Liang, Hongyu Zhu, Wenwen Wang, Deyu Zhou
分类: cs.CL
发布日期: 2026-02-04
💡 一句话要点
探究视觉信息在视觉-语言模型工作记忆中的作用:基于空间n-back任务的证据
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 工作记忆 空间n-back任务 多模态学习 近因效应
📋 核心要点
- 现有研究缺乏对视觉-语言模型中视觉信息工作记忆能力的深入探究,特别是与文本信息相比。
- 该研究通过空间n-back任务,对比视觉和文本两种模态下,视觉-语言模型的工作记忆表现。
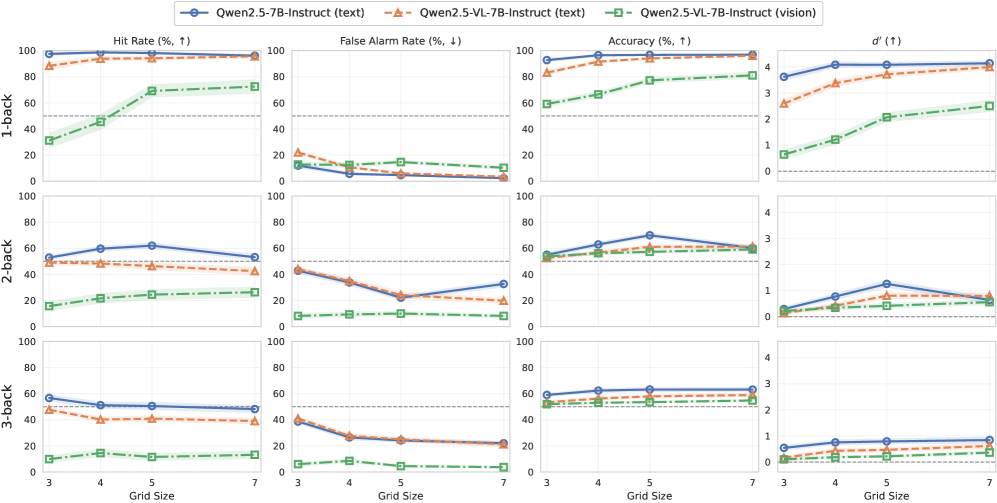
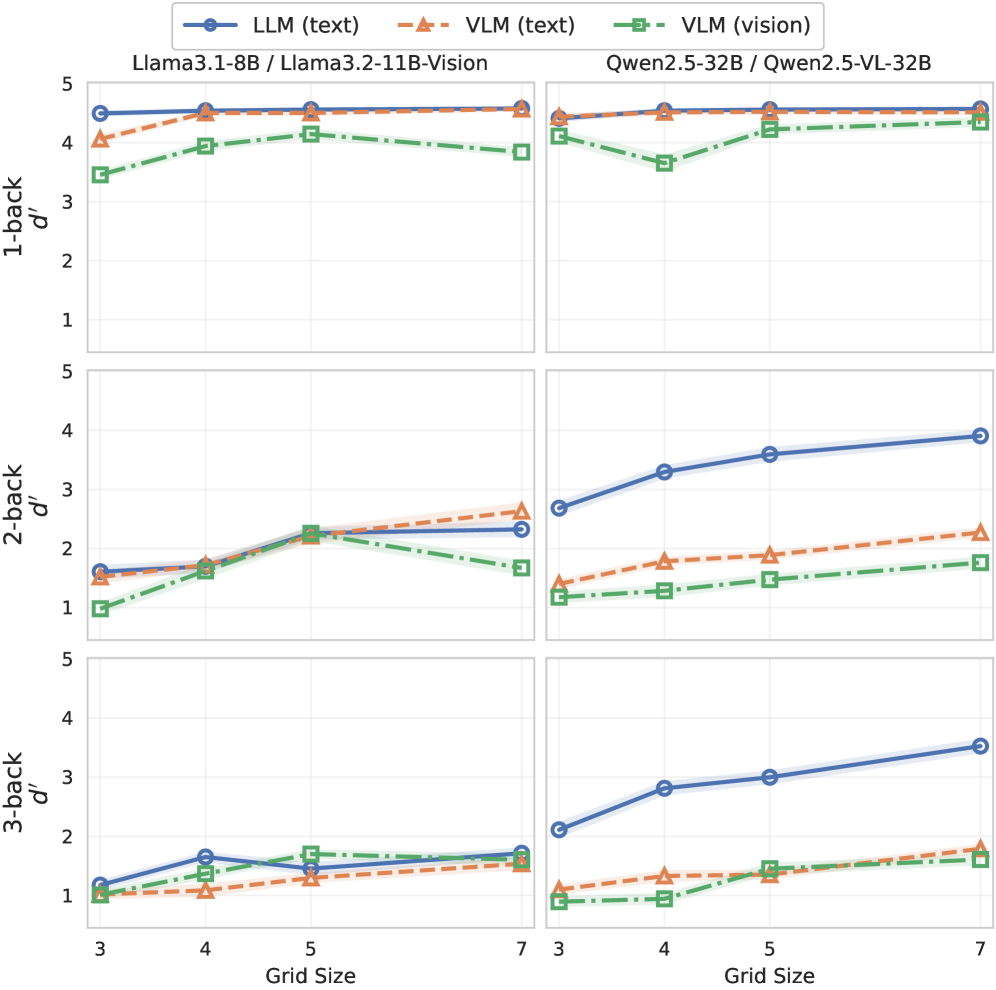
- 实验结果表明,模型在文本模态下的表现优于视觉模态,并揭示了近因效应和网格大小对模型行为的影响。
📝 摘要(中文)
工作记忆是智能行为的核心组成部分,它为维护和更新任务相关信息提供了一个动态的工作空间。最近的研究使用n-back任务来探测大型语言模型中类似工作记忆的行为,但尚不清楚在视觉-语言模型中,当信息以视觉而非文本代码呈现时,相同的探测是否会引发类似的计算。我们评估了Qwen2.5和Qwen2.5-VL在受控的空间n-back任务上的表现,该任务以匹配的文本渲染或图像渲染网格呈现。在所有条件下,模型在文本条件下的准确率和d'值都明显高于视觉条件。为了在过程层面解释这些差异,我们使用了逐次试验的对数概率证据,发现名义上的2/3-back任务常常未能反映所指示的滞后,而是与近因锁定的比较相一致。我们进一步表明,网格大小会改变刺激流中的最近重复结构,从而改变干扰和错误模式。这些结果促使我们对多模态工作记忆进行计算敏感的解释。
🔬 方法详解
问题定义:论文旨在研究视觉-语言模型在处理视觉信息时的工作记忆能力,并将其与处理文本信息时的能力进行比较。现有方法主要集中在语言模型的工作记忆研究,缺乏对视觉-语言模型中视觉信息处理的深入分析。现有方法难以区分模型是真正执行了n-back任务,还是仅仅依赖于近因效应等启发式策略。
核心思路:论文的核心思路是通过设计一个空间n-back任务,分别以文本和图像两种形式呈现刺激,来比较视觉-语言模型在不同模态下的工作记忆表现。通过分析模型的准确率、d'值以及逐次试验的对数概率证据,来推断模型的工作记忆过程,并揭示模型可能存在的偏差和策略。
技术框架:整体框架包括以下几个步骤:1)设计空间n-back任务,其中刺激以文本或图像形式呈现;2)使用Qwen2.5和Qwen2.5-VL模型进行实验;3)评估模型的准确率和d'值;4)分析逐次试验的对数概率证据,以了解模型的决策过程;5)改变网格大小,观察其对模型表现的影响。
关键创新:论文的关键创新在于:1)首次将空间n-back任务应用于视觉-语言模型,以研究其视觉工作记忆能力;2)通过分析逐次试验的对数概率证据,揭示了模型可能存在的近因效应等偏差;3)研究了网格大小对模型表现的影响,表明刺激的结构会影响模型的工作记忆过程。
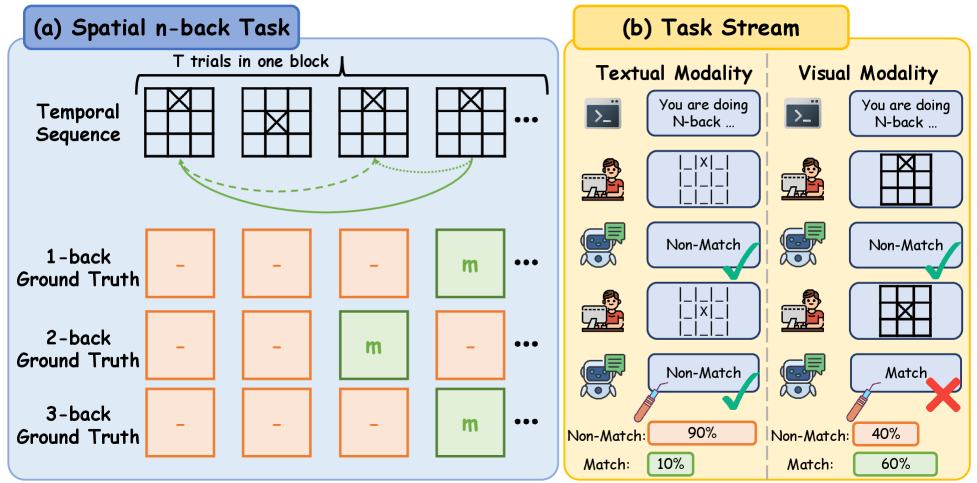
关键设计:空间n-back任务中,使用不同大小的网格(例如3x3、4x4)来呈现刺激。刺激可以是文本或图像,表示网格中的一个位置。模型需要判断当前刺激是否与n步之前的刺激相同。使用准确率和d'值作为评估指标。通过分析逐次试验的对数概率证据,来判断模型是否真正执行了n-back任务,还是仅仅依赖于近因效应。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Qwen2.5和Qwen2.5-VL模型在文本模态下的n-back任务中表现明显优于视觉模态,准确率和d'值均显著提高。对逐次试验的对数概率证据分析表明,模型在2/3-back任务中常常未能反映所指示的滞后,而是倾向于依赖近因效应。此外,改变网格大小会影响刺激流中的最近重复结构,从而改变模型的干扰和错误模式。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型在需要工作记忆的任务中的表现,例如视频理解、视觉导航和人机交互等领域。通过理解模型在处理视觉信息时的局限性,可以设计更有效的模型架构和训练方法,从而提高模型的泛化能力和鲁棒性。此外,该研究也为多模态工作记忆的研究提供了新的思路和方法。
📄 摘要(原文)
Working memory is a central component of intelligent behavior, providing a dynamic workspace for maintaining and updating task-relevant information. Recent work has used n-back tasks to probe working-memory-like behavior in large language models, but it is unclear whether the same probe elicits comparable computations when information is carried in a visual rather than textual code in vision-language models. We evaluate Qwen2.5 and Qwen2.5-VL on a controlled spatial n-back task presented as matched text-rendered or image-rendered grids. Across conditions, models show reliably higher accuracy and d' with text than with vision. To interpret these differences at the process level, we use trial-wise log-probability evidence and find that nominal 2/3-back often fails to reflect the instructed lag and instead aligns with a recency-locked comparison. We further show that grid size alters recent-repeat structure in the stimulus stream, thereby changing interference and error patterns. These results motivate computation-sensitive interpretations of multimodal working memory.