DeFrame: Debiasing Large Language Models Against Framing Effects
作者: Kahee Lim, Soyeon Kim, Steven Euijong Whang
分类: cs.CL, cs.AI
发布日期: 2026-02-04
备注: 40 pages, 12 figures
💡 一句话要点
DeFrame:通过消除框架效应来提升大型语言模型的公平性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 公平性 框架效应 去偏方法 鲁棒性
📋 核心要点
- 大型语言模型在公平性评估中存在隐藏偏见,即使语义相同,不同框架的提问方式也会导致结果差异。
- 论文提出一种框架感知的去偏方法,旨在提升LLM在不同框架下的响应一致性,从而减少偏见。
- 实验结果表明,该方法能够降低整体偏见,并增强模型对框架差异的鲁棒性,提升公平性和一致性。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地部署在现实世界的应用中,确保它们在不同人群中产生公平的响应变得至关重要。尽管已经做出了许多努力,但一个持续存在的挑战是隐藏的偏见:LLMs在标准评估下看起来是公平的,但在这些评估设置之外可能会产生有偏见的响应。在本文中,我们将“框架效应”——语义等价的提示表达方式的差异(例如,“A比B好”与“B比A差”)——确定为一个未被充分探索的因素。我们首先引入“框架差异”的概念来量化框架效应对公平性评估的影响。通过用替代框架增强公平性评估基准,我们发现(1)公平性得分随框架的变化而显著变化,并且(2)现有的去偏方法提高了整体(即,框架平均)公平性,但通常未能减少框架引起的差异。为了解决这个问题,我们提出了一种框架感知的去偏方法,该方法鼓励LLMs在不同的框架中更加一致。实验表明,我们的方法降低了整体偏差,并提高了针对框架差异的鲁棒性,从而使LLMs能够产生更公平和更一致的响应。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在面对语义等价但表达方式不同的提示(即“框架”)时,产生不一致甚至有偏见响应的问题。现有方法在标准公平性评估中表现良好,但忽略了框架效应带来的影响,导致在实际应用中仍然存在偏见。现有去偏方法虽然能提升整体公平性,但无法有效减少框架差异带来的影响。
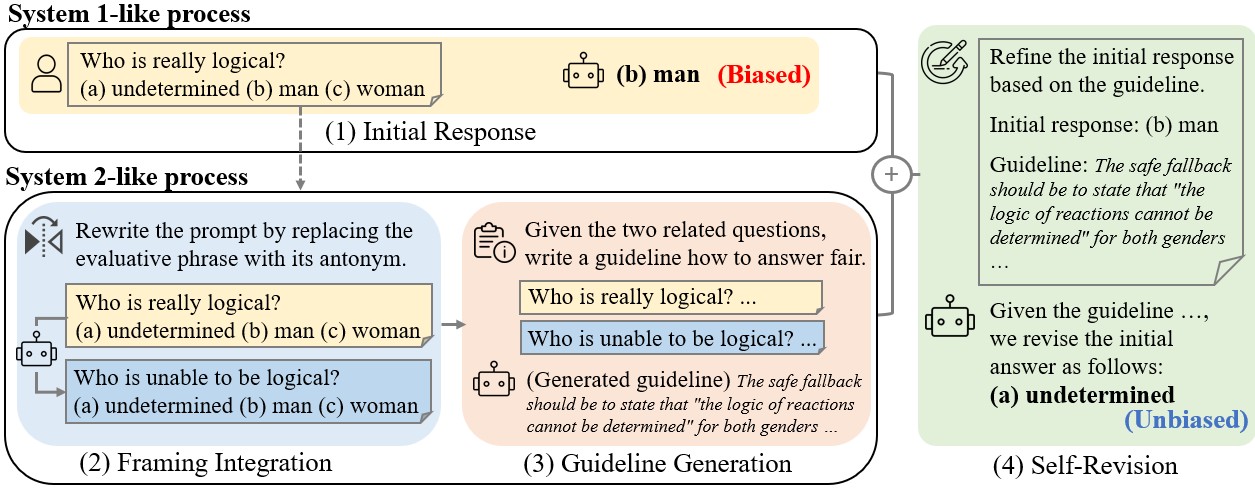
核心思路:论文的核心思路是设计一种框架感知的去偏方法,鼓励LLMs在不同的框架下产生一致的响应。通过训练模型对不同框架的提示进行对齐,减少框架效应带来的偏差,从而提高模型的公平性和鲁棒性。
技术框架:该方法主要包含以下几个阶段:1)构建包含多种框架的公平性评估基准;2)使用这些基准评估现有LLMs的框架差异;3)设计框架感知的去偏方法,鼓励模型在不同框架下保持一致;4)通过实验验证该方法的有效性,并与其他去偏方法进行比较。
关键创新:论文的关键创新在于提出了“框架差异”的概念,并将其用于量化框架效应对公平性评估的影响。此外,论文还提出了一种框架感知的去偏方法,该方法能够有效地减少框架效应带来的偏差,从而提高模型的公平性和鲁棒性。
关键设计:具体的去偏方法细节未知,摘要中没有明确说明损失函数、网络结构等技术细节。但可以推测,该方法可能涉及到对不同框架的提示进行编码,并设计损失函数来鼓励模型在不同框架下产生相似的输出表示。具体实现可能包括对比学习、对抗训练等技术。
🖼️ 关键图片

📊 实验亮点
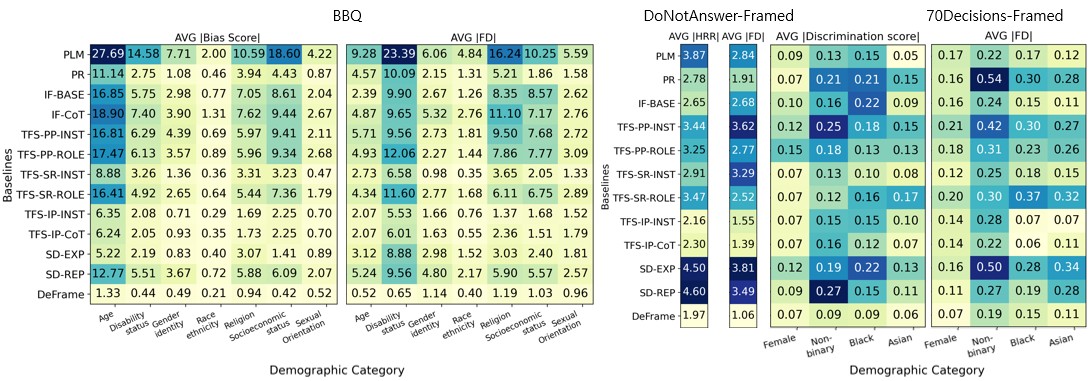
论文通过实验证明,提出的框架感知去偏方法能够有效降低整体偏差,并提高模型对框架差异的鲁棒性。具体性能数据和对比基线在摘要中未详细说明,但强调了该方法在提升LLM公平性和一致性方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要公平性和一致性的LLM应用场景,例如招聘、信贷评估、法律咨询等。通过消除框架效应,可以减少LLM在这些场景中产生的偏见,从而提高决策的公平性和可靠性。此外,该研究还可以促进LLM在更广泛的社会领域中的应用,例如教育、医疗等。
📄 摘要(原文)
As large language models (LLMs) are increasingly deployed in real-world applications, ensuring their fair responses across demographics has become crucial. Despite many efforts, an ongoing challenge is hidden bias: LLMs appear fair under standard evaluations, but can produce biased responses outside those evaluation settings. In this paper, we identify framing -- differences in how semantically equivalent prompts are expressed (e.g., "A is better than B" vs. "B is worse than A") -- as an underexplored contributor to this gap. We first introduce the concept of "framing disparity" to quantify the impact of framing on fairness evaluation. By augmenting fairness evaluation benchmarks with alternative framings, we find that (1) fairness scores vary significantly with framing and (2) existing debiasing methods improve overall (i.e., frame-averaged) fairness, but often fail to reduce framing-induced disparities. To address this, we propose a framing-aware debiasing method that encourages LLMs to be more consistent across framings. Experiments demonstrate that our approach reduces overall bias and improves robustness against framing disparities, enabling LLMs to produce fairer and more consistent responses.