Revisiting Prompt Sensitivity in Large Language Models for Text Classification: The Role of Prompt Underspecification
作者: Branislav Pecher, Michal Spiegel, Robert Belanec, Jan Cegin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-04
💡 一句话要点
研究表明,大语言模型文本分类中Prompt敏感性部分源于Prompt欠规范问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 Prompt工程 Prompt敏感性 文本分类 Prompt欠规范 线性探测 Logit分析
📋 核心要点
- 现有研究表明,大语言模型对Prompt变化敏感,但许多研究使用欠规范Prompt,导致结论可能存在偏差。
- 该研究对比了欠规范Prompt和指令明确Prompt的敏感性,认为Prompt欠规范是造成Prompt敏感性的重要原因。
- 实验结果表明,欠规范Prompt性能方差更高,logit值更低,但对模型内部表示影响较小,主要影响最终层。
📝 摘要(中文)
大型语言模型(LLMs)被广泛用作零样本和少样本分类器,其任务行为主要通过Prompt控制。越来越多的研究表明,LLMs对Prompt的变化非常敏感,微小的变化可能导致性能的巨大差异。然而,在许多情况下,对敏感性的研究是使用欠规范的Prompt进行的,这些Prompt提供的任务指令最少,并且对模型的输出空间约束很弱。本文认为,观察到的Prompt敏感性的很大一部分可以归因于Prompt的欠规范性。我们系统地研究和比较了欠规范Prompt和提供特定指令的Prompt的敏感性。通过性能分析、logit分析和线性探测,我们发现欠规范Prompt表现出更高的性能方差和更低的logit值,而指令Prompt则较少受到此类问题的影响。然而,线性探测分析表明,Prompt欠规范性的影响仅对内部LLM表示产生边际影响,而是在最终层中显现出来。总的来说,我们的发现强调了在研究和减轻Prompt敏感性时需要更加严谨。
🔬 方法详解
问题定义:论文旨在解决大语言模型在文本分类任务中,由于Prompt的微小变化导致性能大幅波动的问题,即Prompt敏感性。现有研究在评估Prompt敏感性时,常常使用信息不足、约束较弱的欠规范Prompt,这可能夸大了Prompt敏感性的影响,掩盖了问题的本质。
核心思路:论文的核心思路是区分Prompt的规范程度,比较欠规范Prompt和指令明确的Prompt在文本分类任务中的表现,从而探究Prompt欠规范性在Prompt敏感性问题中的作用。通过控制Prompt的规范程度,可以更准确地评估Prompt敏感性,并为缓解该问题提供更有效的策略。
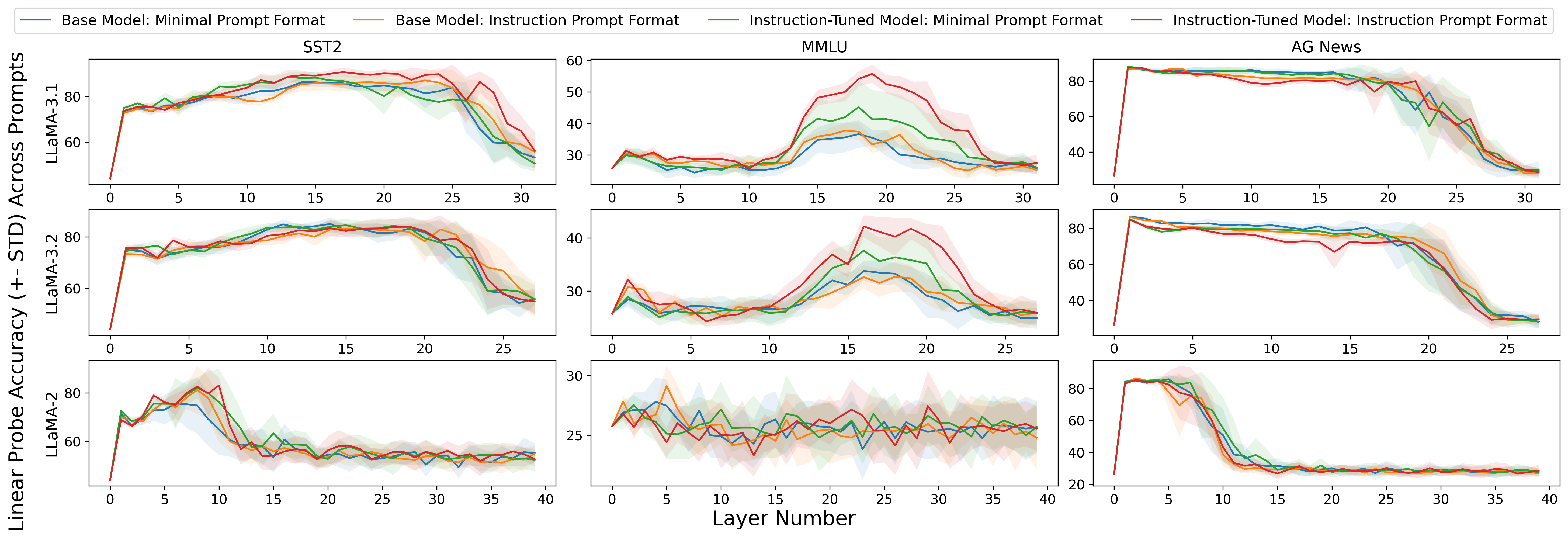
技术框架:论文的技术框架主要包括以下几个部分:1) 定义欠规范Prompt和指令明确Prompt;2) 在文本分类任务上,使用不同类型的Prompt进行实验;3) 通过性能分析、logit分析和线性探测等方法,分析不同Prompt的表现和对模型内部表示的影响。性能分析关注分类准确率的方差,logit分析关注模型对正确token的置信度,线性探测关注Prompt对模型内部表示的影响。
关键创新:论文的关键创新在于提出了Prompt欠规范性是Prompt敏感性的一个重要因素,并系统地研究了Prompt规范程度对模型性能的影响。与以往研究不同,该研究强调了Prompt设计的重要性,并为更准确地评估和缓解Prompt敏感性提供了新的视角。
关键设计:论文的关键设计包括:1) 欠规范Prompt的设计,例如仅提供任务名称,而不提供具体的指令;2) 指令明确Prompt的设计,例如提供详细的任务描述和输出格式要求;3) 使用不同的文本分类数据集进行实验,以验证结论的泛化性;4) 使用线性探测技术,分析Prompt对模型不同层的影响,从而了解Prompt敏感性的来源。
🖼️ 关键图片

📊 实验亮点
研究发现,欠规范Prompt比指令明确Prompt表现出更高的性能方差和更低的logit值,表明欠规范Prompt更容易受到Prompt变化的影响。线性探测分析表明,Prompt欠规范性的影响主要体现在模型的最终层,对内部表示的影响较小。这些结果强调了在研究Prompt敏感性时,需要更加关注Prompt的规范程度。
🎯 应用场景
该研究成果可应用于提升大语言模型在文本分类等任务中的稳定性和可靠性。通过优化Prompt设计,减少Prompt敏感性,可以提高模型在实际应用中的性能,例如情感分析、主题分类、垃圾邮件检测等。此外,该研究也为Prompt工程提供了新的思路,有助于开发更有效的Prompt设计方法。
📄 摘要(原文)
Large language models (LLMs) are widely used as zero-shot and few-shot classifiers, where task behaviour is largely controlled through prompting. A growing number of works have observed that LLMs are sensitive to prompt variations, with small changes leading to large changes in performance. However, in many cases, the investigation of sensitivity is performed using underspecified prompts that provide minimal task instructions and weakly constrain the model's output space. In this work, we argue that a significant portion of the observed prompt sensitivity can be attributed to prompt underspecification. We systematically study and compare the sensitivity of underspecified prompts and prompts that provide specific instructions. Utilising performance analysis, logit analysis, and linear probing, we find that underspecified prompts exhibit higher performance variance and lower logit values for relevant tokens, while instruction-prompts suffer less from such problems. However, linear probing analysis suggests that the effects of prompt underspecification have only a marginal impact on the internal LLM representations, instead emerging in the final layers. Overall, our findings highlight the need for more rigour when investigating and mitigating prompt sensitivity.