Language Models Struggle to Use Representations Learned In-Context
作者: Michael A. Lepori, Tal Linzen, Ann Yuan, Katja Filippova
分类: cs.CL, cs.AI
发布日期: 2026-02-04
💡 一句话要点
大型语言模型难以有效利用上下文学习到的表征完成下游任务
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文学习 表征学习 自适应世界建模 下游任务 语义理解
📋 核心要点
- 现有大型语言模型在适应全新上下文方面存在不足,无法灵活运用上下文学习到的表征。
- 论文研究了开源及闭源LLM利用上下文表征完成下游任务的能力,着重考察其对新语义的理解和应用。
- 实验表明,即使是最先进的LLM也难以可靠地利用上下文呈现的新模式,需要进一步研究提升模型表征利用能力。
📝 摘要(中文)
尽管大型语言模型(LLMs)在各种任务中取得了巨大成功,但它们似乎未能实现人工智能研究的一个崇高目标:创建一个能够根据部署时遇到的全新上下文调整其行为的人工系统。实现这一目标的一个重要步骤是创建能够诱导上下文数据丰富表征的系统,然后灵活地部署这些表征以完成目标。最近,Park等人(2024)证明,当前的LLM确实能够从上下文中诱导这种表征(即,上下文表征学习)。本研究调查了LLM是否可以使用这些表征来完成简单的下游任务。我们首先评估了开源LLM是否可以使用上下文表征进行下一个token预测,然后使用一种新颖的任务——自适应世界建模来探测模型。在这两项任务中,我们都发现证据表明,开源LLM难以部署上下文中定义的新语义的表征,即使它们将这些语义编码在其潜在表征中。此外,我们评估了闭源、最先进的推理模型在自适应世界建模任务上的表现,表明即使是性能最佳的LLM也无法可靠地利用上下文中呈现的新模式。总的来说,这项工作旨在激发新的方法,以鼓励模型不仅编码上下文中呈现的信息,而且以支持灵活部署此信息的方式进行编码。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)是否能够有效地利用在上下文中学习到的表征来完成下游任务。现有的LLMs虽然在各种任务中表现出色,但它们在适应全新的上下文和灵活运用上下文信息方面仍然存在不足。具体来说,即使LLMs能够编码上下文信息,它们也可能难以将这些信息用于完成后续的任务,例如预测下一个token或进行自适应世界建模。
核心思路:论文的核心思路是设计实验来评估LLMs在利用上下文表征方面的能力。通过构建特定的任务,例如自适应世界建模,来考察LLMs是否能够理解并应用在上下文中定义的新语义。这种方法旨在揭示LLMs在表征学习和表征利用之间的差距,并为未来的研究提供方向。
技术框架:论文主要采用了两种任务来评估LLMs的上下文表征利用能力:一是下一个token预测任务,用于评估开源LLMs是否能够利用上下文表征进行token预测;二是自适应世界建模任务,用于评估开源和闭源LLMs是否能够理解并应用在上下文中定义的新模式。自适应世界建模任务涉及让模型根据上下文中的规则来预测后续的状态或事件。
关键创新:论文的关键创新在于提出了自适应世界建模任务,该任务能够有效地评估LLMs在利用上下文表征方面的能力。与传统的语言建模任务不同,自适应世界建模任务要求模型不仅要理解语言的结构,还要理解在上下文中定义的新规则和模式。此外,论文还对开源和闭源LLMs进行了对比评估,揭示了即使是最先进的LLMs也存在表征利用方面的不足。
关键设计:在自适应世界建模任务中,论文设计了一系列规则和模式,这些规则和模式在上下文中被明确地定义。模型需要根据这些规则来预测后续的状态或事件。论文还使用了不同的评估指标来衡量模型的性能,例如预测准确率和一致性。具体的参数设置和网络结构取决于所使用的LLM。
🖼️ 关键图片

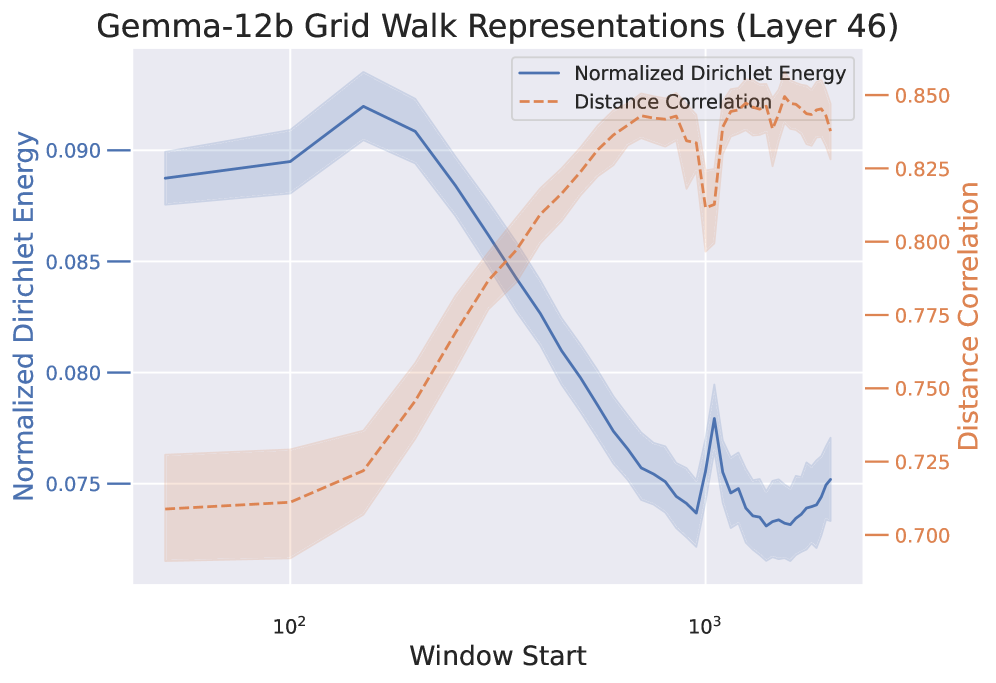

📊 实验亮点
实验结果表明,即使是最先进的闭源LLM,在自适应世界建模任务中也难以可靠地利用上下文呈现的新模式。开源LLM在下一个token预测和自适应世界建模任务中均表现出对上下文表征利用的困难。这些发现突出了当前LLM在表征学习和表征利用之间的差距。
🎯 应用场景
该研究成果可应用于提升语言模型在复杂环境下的适应性和泛化能力,例如在机器人控制、对话系统和智能助手等领域。通过提高模型对上下文信息的利用效率,可以使AI系统更好地理解用户意图,并做出更准确的决策,从而提升用户体验。
📄 摘要(原文)
Though large language models (LLMs) have enabled great success across a wide variety of tasks, they still appear to fall short of one of the loftier goals of artificial intelligence research: creating an artificial system that can adapt its behavior to radically new contexts upon deployment. One important step towards this goal is to create systems that can induce rich representations of data that are seen in-context, and then flexibly deploy these representations to accomplish goals. Recently, Park et al. (2024) demonstrated that current LLMs are indeed capable of inducing such representation from context (i.e., in-context representation learning). The present study investigates whether LLMs can use these representations to complete simple downstream tasks. We first assess whether open-weights LLMs can use in-context representations for next-token prediction, and then probe models using a novel task, adaptive world modeling. In both tasks, we find evidence that open-weights LLMs struggle to deploy representations of novel semantics that are defined in-context, even if they encode these semantics in their latent representations. Furthermore, we assess closed-source, state-of-the-art reasoning models on the adaptive world modeling task, demonstrating that even the most performant LLMs cannot reliably leverage novel patterns presented in-context. Overall, this work seeks to inspire novel methods for encouraging models to not only encode information presented in-context, but to do so in a manner that supports flexible deployment of this information.