They Said Memes Were Harmless-We Found the Ones That Hurt: Decoding Jokes, Symbols, and Cultural References
作者: Sahil Tripathi, Gautam Siddharth Kashyap, Mehwish Nasim, Jian Yang, Jiechao Gao, Usman Naseem
分类: cs.CL
发布日期: 2026-02-03
备注: Accepted at the The Web Conference 2026 (Research Track)
💡 一句话要点
提出CROSS-ALIGN+框架,解决基于Meme的社交恶意滥用检测中文化盲区和可解释性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Meme检测 社交媒体滥用 多模态学习 知识图谱 可解释性AI
📋 核心要点
- 现有基于Meme的恶意滥用检测方法在文化符号理解、讽刺与滥用区分以及模型可解释性方面存在不足。
- CROSS-ALIGN+框架通过融入结构化知识、使用LoRA适配器和生成级联解释,系统地解决了上述问题。
- 实验结果表明,CROSS-ALIGN+在多个基准数据集上显著优于现有方法,并提供了决策的可解释性。
📝 摘要(中文)
基于Meme的社交恶意滥用检测极具挑战性,因为有害意图通常依赖于隐式的文化符号和微妙的跨模态不协调。现有的方法,从基于融合的方法到使用大型视觉语言模型(LVLMs)的上下文学习,取得了一些进展,但仍然受到三个因素的限制:i)文化盲区(缺少符号背景);ii)边界模糊(讽刺与滥用混淆);iii)缺乏可解释性(模型推理不透明)。我们引入了CROSS-ALIGN+,这是一个三阶段框架,系统地解决了这些限制:(1)第一阶段通过使用ConceptNet、Wikidata和Hatebase中的结构化知识来丰富多模态表示,从而减轻文化盲区;(2)第二阶段通过参数高效的LoRA适配器来锐化决策边界,从而减少边界模糊;(3)第三阶段通过生成级联解释来增强可解释性。在五个基准数据集和八个LVLM上的大量实验表明,CROSS-ALIGN+始终优于最先进的方法,实现了高达17%的相对F1提升,同时为每个决策提供了可解释的理由。
🔬 方法详解
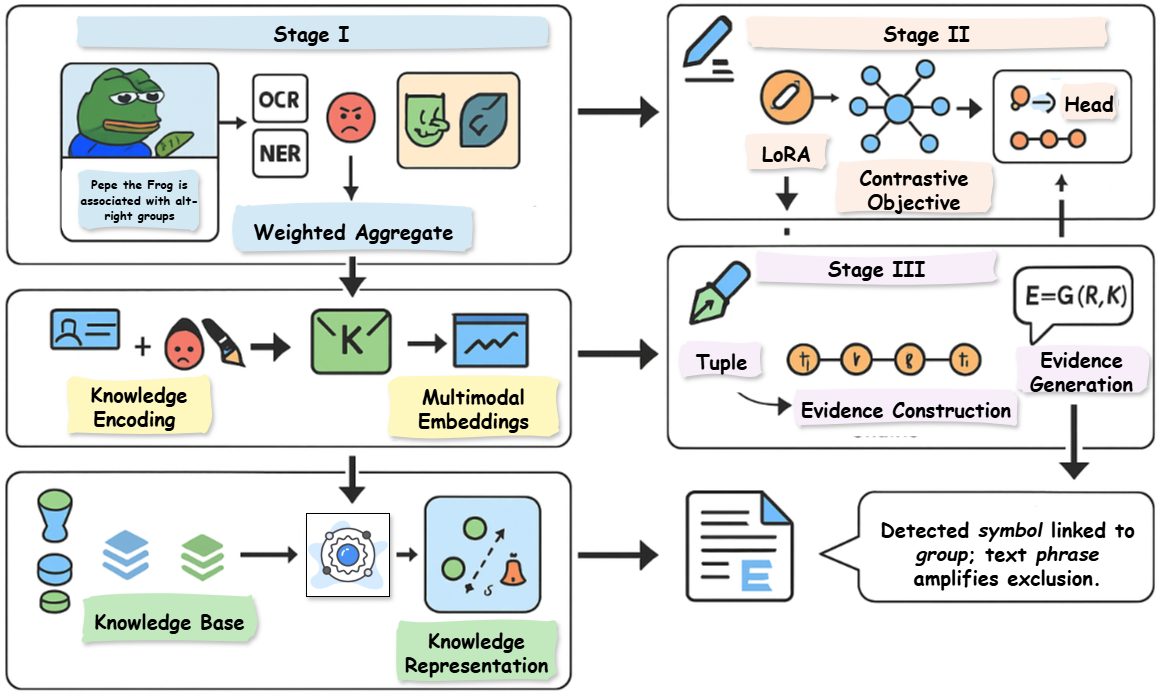
问题定义:论文旨在解决基于Meme的社交媒体恶意滥用检测问题。现有方法,包括基于融合的方法和使用大型视觉语言模型(LVLMs)的上下文学习,在处理Meme中常见的文化符号、区分讽刺与滥用以及提供可解释的决策依据方面存在局限性。现有方法的痛点在于文化盲区、边界模糊和缺乏可解释性。
核心思路:论文的核心思路是通过引入外部知识库来弥补模型的文化盲区,利用参数高效的LoRA适配器来锐化决策边界,并通过生成级联解释来提高模型的可解释性。这种设计旨在使模型能够更好地理解Meme中的隐式含义,区分讽刺与滥用,并为每个决策提供合理的解释。
技术框架:CROSS-ALIGN+框架包含三个主要阶段:(1)文化知识增强阶段:利用ConceptNet、Wikidata和Hatebase等知识库,将结构化知识融入多模态表示中,以弥补文化盲区。(2)决策边界锐化阶段:使用参数高效的LoRA适配器,微调模型参数,从而更清晰地区分讽刺与滥用。(3)可解释性增强阶段:生成级联解释,为每个决策提供可解释的理由,提高模型的可信度。
关键创新:该论文的关键创新在于将外部知识库、参数高效微调和可解释性生成相结合,形成一个完整的框架,从而有效地解决了基于Meme的社交媒体恶意滥用检测中的文化盲区、边界模糊和缺乏可解释性问题。与现有方法相比,CROSS-ALIGN+能够更好地理解Meme中的隐式含义,区分讽刺与滥用,并为每个决策提供合理的解释。
关键设计:在文化知识增强阶段,论文可能采用了特定的知识图谱嵌入方法,将ConceptNet、Wikidata和Hatebase中的知识融入多模态表示中。在决策边界锐化阶段,LoRA适配器的具体参数设置(如秩的大小)以及微调策略可能对性能产生重要影响。在可解释性增强阶段,级联解释的生成方式(如使用特定的语言模型或规则)以及解释的质量是关键因素。具体的损失函数设计和网络结构细节未知。
🖼️ 关键图片


📊 实验亮点
CROSS-ALIGN+在五个基准数据集和八个LVLM上进行了广泛的实验,结果表明该方法始终优于最先进的方法,实现了高达17%的相对F1提升。此外,该方法还能够为每个决策提供可解释的理由,提高了模型的可信度。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,自动检测和过滤恶意Meme,减少网络暴力和仇恨言论的传播。此外,该方法还可用于提高AI模型的可解释性和可信度,促进人机协作,并为文化遗产保护提供技术支持。
📄 摘要(原文)
Meme-based social abuse detection is challenging because harmful intent often relies on implicit cultural symbolism and subtle cross-modal incongruence. Prior approaches, from fusion-based methods to in-context learning with Large Vision-Language Models (LVLMs), have made progress but remain limited by three factors: i) cultural blindness (missing symbolic context), ii) boundary ambiguity (satire vs. abuse confusion), and iii) lack of interpretability (opaque model reasoning). We introduce CROSS-ALIGN+, a three-stage framework that systematically addresses these limitations: (1) Stage I mitigates cultural blindness by enriching multimodal representations with structured knowledge from ConceptNet, Wikidata, and Hatebase; (2) Stage II reduces boundary ambiguity through parameter-efficient LoRA adapters that sharpen decision boundaries; and (3) Stage III enhances interpretability by generating cascaded explanations. Extensive experiments on five benchmarks and eight LVLMs demonstrate that CROSS-ALIGN+ consistently outperforms state-of-the-art methods, achieving up to 17% relative F1 improvement while providing interpretable justifications for each decision.