Instruction Anchors: Dissecting the Causal Dynamics of Modality Arbitration
作者: Yu Zhang, Mufan Xu, Xuefeng Bai, Kehai chen, Pengfei Zhang, Yang Xiang, Min Zhang
分类: cs.CL
发布日期: 2026-02-03
备注: Modality Following
💡 一句话要点
提出指令锚点理论,揭示多模态大语言模型中模态仲裁的因果机制。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 模态仲裁 指令锚点 因果干预 信息流分析
📋 核心要点
- 多模态大语言模型(MLLM)的模态跟随能力至关重要,但其决策机制尚不明确,阻碍了模型安全性和可靠性的提升。
- 该论文提出“指令锚点”理论,认为指令token在浅层作为信息缓冲区,深层注意力层基于指令意图解决模态竞争。
- 通过因果干预实验,发现仅需操纵5%的关键注意力头,即可显著改变模态跟随率,验证了理论的有效性。
📝 摘要(中文)
模态跟随是多模态大语言模型(MLLM)根据用户指令选择性地利用多模态上下文的能力。这对于确保实际部署中的安全性和可靠性至关重要。然而,控制这种决策过程的潜在机制仍然知之甚少。本文从信息流的角度研究了其工作机制。我们的研究结果表明,指令token充当模态仲裁的结构锚点:浅层注意力层执行非选择性的信息传递,将多模态线索路由到这些锚点作为潜在缓冲区;模态竞争在指令意图指导下的深层注意力层中解决,而MLP层表现出语义惯性,充当对抗力量。此外,我们识别出一组稀疏的专用注意力头,它们驱动这种仲裁。因果干预表明,通过阻断或有针对性地放大失败样本,操纵仅5%的这些关键头可以将模态跟随率降低60%或提高60%。我们的工作为模型透明性迈出了重要一步,并为MLLM中多模态信息的编排提供了一个原则性框架。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)中模态仲裁机制不透明的问题。现有的MLLM在处理多模态输入时,如何根据指令选择性地利用不同模态的信息,其内在决策过程是一个黑盒,这限制了模型的可控性和可靠性,尤其是在安全攸关的应用场景中。
核心思路:论文的核心思路是将指令token视为“指令锚点”,认为它们在模态仲裁中起着关键作用。浅层注意力层负责将来自不同模态的信息汇聚到这些锚点,形成一个潜在的信息缓冲区。深层注意力层则根据指令的意图,在这些锚点上进行模态竞争的决策。MLP层则表现出一定的语义惯性,对模态仲裁产生干扰。
技术框架:该研究采用信息流分析的方法,通过分析不同层、不同注意力头之间的信息传递模式,来揭示模态仲裁的机制。具体来说,研究人员首先识别出对模态仲裁起关键作用的注意力头,然后通过因果干预(如阻断或放大这些注意力头)来验证其作用。
关键创新:该论文最重要的技术创新在于提出了“指令锚点”的概念,并揭示了不同网络层在模态仲裁中的不同作用。这为理解MLLM的内部工作机制提供了一个新的视角,也为控制和优化MLLM的模态跟随能力提供了新的思路。
关键设计:论文的关键设计包括:1) 通过信息流分析识别关键注意力头;2) 设计因果干预实验,通过操纵这些关键注意力头来验证其作用;3) 分析不同网络层(浅层注意力层、深层注意力层、MLP层)在模态仲裁中的不同行为。
🖼️ 关键图片


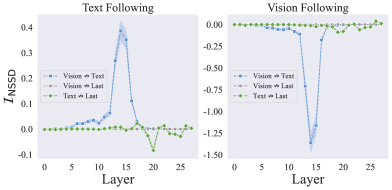
📊 实验亮点
实验结果表明,通过阻断或有针对性地放大仅占总数5%的关键注意力头,可以将模态跟随率降低或提高60%。这一结果有力地证明了“指令锚点”理论的有效性,并揭示了少量关键注意力头在模态仲裁中的重要作用。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型的安全性和可靠性,例如在医疗诊断、自动驾驶等领域,确保模型能够根据指令正确地利用多模态信息,避免产生错误或危险的决策。此外,该研究也为开发更可控、更透明的多模态模型提供了理论基础。
📄 摘要(原文)
Modality following serves as the capacity of multimodal large language models (MLLMs) to selectively utilize multimodal contexts based on user instructions. It is fundamental to ensuring safety and reliability in real-world deployments. However, the underlying mechanisms governing this decision-making process remain poorly understood. In this paper, we investigate its working mechanism through an information flow lens. Our findings reveal that instruction tokens function as structural anchors for modality arbitration: Shallow attention layers perform non-selective information transfer, routing multimodal cues to these anchors as a latent buffer; Modality competition is resolved within deep attention layers guided by the instruction intent, while MLP layers exhibit semantic inertia, acting as an adversarial force. Furthermore, we identify a sparse set of specialized attention heads that drive this arbitration. Causal interventions demonstrate that manipulating a mere $5\%$ of these critical heads can decrease the modality-following ratio by $60\%$ through blocking, or increase it by $60\%$ through targeted amplification of failed samples. Our work provides a substantial step toward model transparency and offers a principled framework for the orchestration of multimodal information in MLLMs.