TRE: Encouraging Exploration in the Trust Region
作者: Chao Huang, Yujing Lu, Quangang Li, Shenghe Wang, Yan Wang, Yueyang Zhang, Long Xia, Jiashu Zhao, Zhiyuan Sun, Daiting Shi, Tingwen Liu
分类: cs.CL, cs.LG
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出信任域熵(TRE)方法,解决LLM中探索失效问题,提升数学推理、组合搜索和偏好对齐任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 探索策略 熵正则化 信任域 数学推理 组合搜索
📋 核心要点
- 大型语言模型中,标准熵正则化探索方法由于词汇量大和生成范围长,导致累积尾部风险,探索效果不佳甚至降低性能。
- 提出信任域熵(TRE)方法,限制探索范围在模型信任域内,避免概率质量分散到大量无效token,保持推理连贯性。
- 在数学推理、组合搜索和偏好对齐任务上,TRE显著优于传统PPO、标准熵正则化等基线方法,验证了其有效性。
📝 摘要(中文)
熵正则化是强化学习中一种常用的增强探索的技术,但在大型语言模型(LLM)中,它要么效果不明显,要么甚至会降低性能。我们认为这种失败是由于LLM固有的累积尾部风险造成的,这种风险来自于LLM庞大的词汇表和较长的生成范围。在这种环境中,标准的全局熵最大化会不加区分地将概率质量稀释到无效token的巨大尾部,而不是集中在合理的候选token上,从而扰乱了连贯的推理。为了解决这个问题,我们提出了一种信任域熵(TRE)方法,该方法鼓励在模型的信任域内进行探索。在数学推理(MATH)、组合搜索(Countdown)和偏好对齐(HH)任务中的大量实验表明,TRE始终优于vanilla PPO、标准熵正则化和其他探索基线。我们的代码可在https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中,标准熵正则化方法在强化学习中探索失效的问题。现有方法的问题在于,LLM拥有庞大的词汇表和较长的生成序列,导致概率质量分散到大量无效的token上,从而干扰了模型的推理能力。这种现象被称为累积尾部风险,是现有方法无法有效探索的关键痛点。
核心思路:论文的核心思路是将探索限制在模型的“信任域”内。信任域是指模型认为合理的token集合,通过限制探索范围,避免将概率质量分散到无效token上,从而保持推理的连贯性。这种方法旨在更有效地利用熵正则化来促进有意义的探索。
技术框架:TRE方法基于现有的强化学习框架,如PPO。其主要流程包括:1)使用LLM生成token序列;2)计算每个token的概率分布;3)定义信任域,通常基于概率阈值或top-k选择;4)在信任域内进行熵正则化,鼓励探索;5)使用强化学习算法更新模型参数。
关键创新:TRE的关键创新在于将探索范围限制在模型的信任域内。与标准的全局熵最大化不同,TRE只鼓励在模型认为合理的token集合中进行探索。这种局部熵最大化能够更有效地利用熵正则化来促进有意义的探索,避免概率质量分散到无效token上。
关键设计:TRE的关键设计包括:1)信任域的定义方式,可以使用概率阈值或top-k选择;2)熵正则化的强度,需要根据具体任务进行调整;3)与现有强化学习算法的集成方式,例如PPO。具体实现细节可能包括对损失函数的修改,以鼓励在信任域内的探索。
🖼️ 关键图片


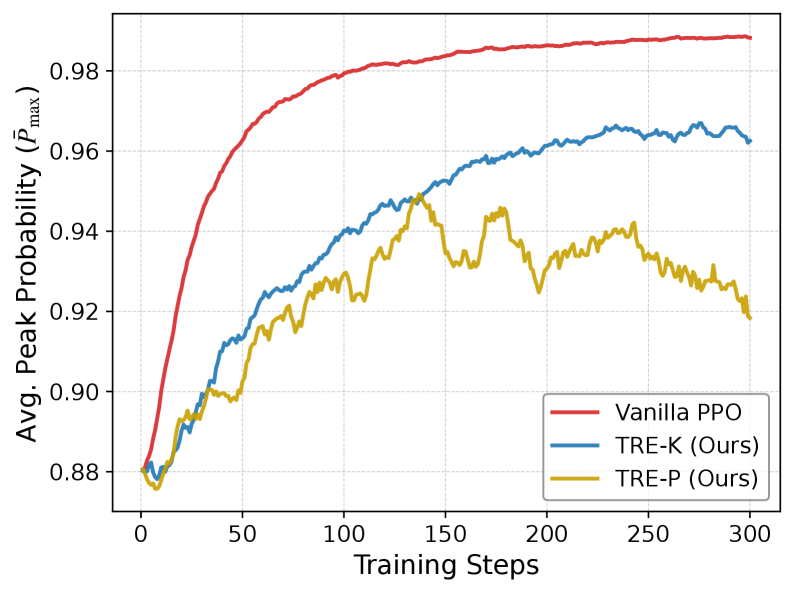
📊 实验亮点
实验结果表明,TRE在数学推理(MATH)、组合搜索(Countdown)和偏好对齐(HH)任务中均优于vanilla PPO、标准熵正则化和其他探索基线。具体性能提升数据未在摘要中明确给出,但强调了TRE在多个任务上的一致性优越性,表明其具有较强的泛化能力和实用价值。
🎯 应用场景
该研究成果可应用于各种需要LLM进行探索和推理的任务,例如数学问题求解、代码生成、对话系统和机器人控制。通过提高LLM的探索效率和推理能力,可以提升这些应用场景的性能和用户体验。此外,该方法还可以用于提高LLM的鲁棒性和泛化能力,使其能够更好地适应不同的环境和任务。
📄 摘要(原文)
Entropy regularization is a standard technique in reinforcement learning (RL) to enhance exploration, yet it yields negligible effects or even degrades performance in Large Language Models (LLMs). We attribute this failure to the cumulative tail risk inherent to LLMs with massive vocabularies and long generation horizons. In such environments, standard global entropy maximization indiscriminately dilutes probability mass into the vast tail of invalid tokens rather than focusing on plausible candidates, thereby disrupting coherent reasoning. To address this, we propose Trust Region Entropy (TRE), a method that encourages exploration strictly within the model's trust region. Extensive experiments across mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) tasks demonstrate that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines. Our code is available at https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region.