$V_0$: A Generalist Value Model for Any Policy at State Zero
作者: Yi-Kai Zhang, Zhiyuan Yao, Hongyan Hao, Yueqing Sun, Qi Gu, Hui Su, Xunliang Cai, De-Chuan Zhan, Han-Jia Ye
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出V0通用价值模型,无需更新参数即可评估任意策略在初始状态的性能,用于LLM训练和部署。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 价值模型 大型语言模型 策略梯度 Actor-Critic 强化学习 资源调度 模型路由
📋 核心要点
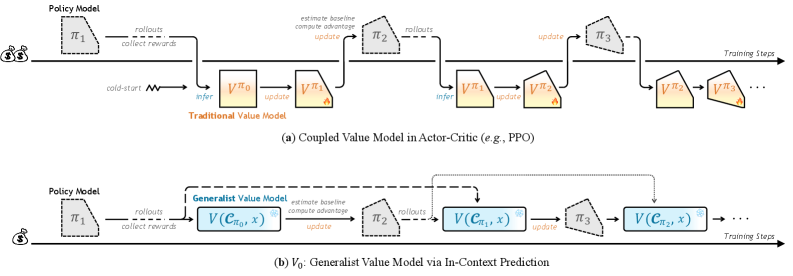
- 传统Actor-Critic方法训练LLM时,价值模型需同步更新以追踪策略变化,开销巨大。
- V0模型将策略动态能力视为上下文输入,通过历史指令-性能对动态分析模型,无需参数更新。
- 实验表明V0在GRPO训练中能有效分配采样预算,部署时能实现LLM路由的性能与成本帕累托最优。
📝 摘要(中文)
策略梯度方法依赖于基线来衡量动作的相对优势,确保模型强化优于当前平均水平的行为。在使用Actor-Critic方法(如PPO)训练大型语言模型(LLM)时,该基线通常由一个价值模型(Critic)估计,其大小通常与策略模型本身一样大。然而,随着策略的不断演变,价值模型需要昂贵的、同步的增量训练,以准确跟踪策略不断变化的能力。为了避免这种开销,Group Relative Policy Optimization (GRPO) 通过使用一组rollout的平均奖励作为基线来消除耦合的价值模型;然而,这种方法需要大量的采样来维持估计的稳定性。在本文中,我们提出了$V_0$,一种通用的价值模型,能够在不需要参数更新的情况下,估计任何模型在未见过的提示上的预期性能。我们通过将策略的动态能力视为显式上下文输入来重新构建价值估计;具体来说,我们利用指令-性能对的历史来动态地分析模型,从而脱离了依赖参数拟合来感知能力变化的传统范式。我们的模型专注于在状态零(即初始提示,因此为$V_0$)进行价值估计,可以作为一个关键的资源调度器。在GRPO训练期间,$V_0$在rollout之前预测成功率,从而可以有效地分配采样预算;在部署期间,它充当路由器,将指令分派给最具成本效益和最合适的模型。实验结果表明,$V_0$显著优于启发式预算分配,并在LLM路由任务中实现了性能和成本之间的帕累托最优权衡。
🔬 方法详解
问题定义:现有Actor-Critic方法在训练大型语言模型时,需要一个与策略模型同等规模的价值模型(Critic)来估计基线,用于衡量动作的相对优势。然而,随着策略模型的不断演进,价值模型需要进行昂贵的同步增量训练,以准确跟踪策略模型的能力变化。这导致了巨大的计算开销和训练复杂性。此外,GRPO方法虽然避免了耦合的价值模型,但需要大量的采样来保证估计的稳定性。
核心思路:本文的核心思路是将价值估计问题重新定义为基于上下文的预测问题。不再依赖于参数拟合来感知策略模型的能力变化,而是将策略模型的动态能力视为显式的上下文输入。具体来说,通过利用历史的指令-性能对,动态地对模型进行画像,从而实现对任意策略在初始状态下的性能进行估计,而无需进行参数更新。这种方法的核心在于将价值估计从一个需要不断拟合参数的过程,转变为一个基于历史数据的预测过程。
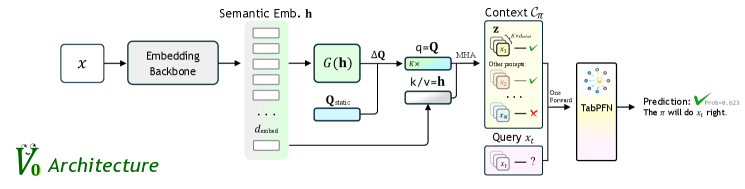
技术框架:V0模型的技术框架主要包含以下几个阶段:1. 数据收集:收集历史的指令-性能对,作为模型的训练数据。2. 上下文编码:对输入的指令和策略模型的性能进行编码,形成上下文向量。3. 价值预测:使用编码后的上下文向量,预测策略模型在初始状态下的预期性能。4. 应用:在GRPO训练中,V0模型用于预测成功率,从而进行采样预算的分配;在部署阶段,V0模型作为路由器,将指令分派给最合适的模型。
关键创新:最重要的技术创新点在于将价值估计问题从传统的参数拟合范式,转变为基于上下文的预测范式。与现有方法相比,V0模型不需要进行参数更新,即可对任意策略模型的性能进行估计。这极大地降低了计算开销和训练复杂性。此外,V0模型专注于在初始状态(State Zero)进行价值估计,使其能够作为一个关键的资源调度器。
关键设计:V0模型的关键设计包括:1. 指令-性能对的表示:如何有效地表示指令和策略模型的性能,以便模型能够学习到它们之间的关系。2. 上下文编码器的设计:如何设计一个能够有效地编码上下文信息的编码器,以便模型能够准确地预测价值。3. 损失函数的设计:如何设计一个合适的损失函数,以便模型能够学习到准确的价值估计。具体的网络结构和参数设置在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
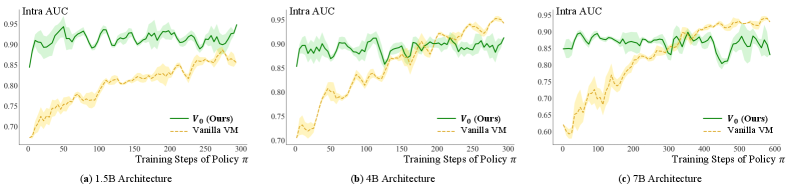
V0模型在实验中显著优于启发式预算分配方法,并在LLM路由任务中实现了性能和成本之间的帕累托最优权衡。具体性能数据和提升幅度在摘要中未给出,但强调了其在资源调度和成本效益方面的优势。
🎯 应用场景
V0模型可广泛应用于大型语言模型的训练和部署。在训练阶段,它可以作为GRPO等方法的辅助工具,提高采样效率。在部署阶段,它可以作为智能路由器,根据指令的特点和模型的性能,将指令分发给最合适的模型,实现性能和成本的优化。此外,V0模型还可以用于模型选择、模型评估等任务,具有广泛的应用前景。
📄 摘要(原文)
Policy gradient methods rely on a baseline to measure the relative advantage of an action, ensuring the model reinforces behaviors that outperform its current average capability. In the training of Large Language Models (LLMs) using Actor-Critic methods (e.g., PPO), this baseline is typically estimated by a Value Model (Critic) often as large as the policy model itself. However, as the policy continuously evolves, the value model requires expensive, synchronous incremental training to accurately track the shifting capabilities of the policy. To avoid this overhead, Group Relative Policy Optimization (GRPO) eliminates the coupled value model by using the average reward of a group of rollouts as the baseline; yet, this approach necessitates extensive sampling to maintain estimation stability. In this paper, we propose $V_0$, a Generalist Value Model capable of estimating the expected performance of any model on unseen prompts without requiring parameter updates. We reframe value estimation by treating the policy's dynamic capability as an explicit context input; specifically, we leverage a history of instruction-performance pairs to dynamically profile the model, departing from the traditional paradigm that relies on parameter fitting to perceive capability shifts. Focusing on value estimation at State Zero (i.e., the initial prompt, hence $V_0$), our model serves as a critical resource scheduler. During GRPO training, $V_0$ predicts success rates prior to rollout, allowing for efficient sampling budget allocation; during deployment, it functions as a router, dispatching instructions to the most cost-effective and suitable model. Empirical results demonstrate that $V_0$ significantly outperforms heuristic budget allocation and achieves a Pareto-optimal trade-off between performance and cost in LLM routing tasks.