Use Graph When It Needs: Efficiently and Adaptively Integrating Retrieval-Augmented Generation with Graphs
作者: Su Dong, Qinggang Zhang, Yilin Xiao, Shengyuan Chen, Chuang Zhou, Xiao Huang
分类: cs.CL, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出EA-GraphRAG,通过语法感知复杂度分析自适应融合RAG与图增强RAG,提升知识密集型任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 知识图谱 问答系统 复杂度分析 自适应学习 自然语言处理 信息检索
📋 核心要点
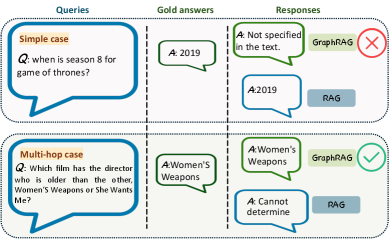
- 现有GraphRAG方法对所有查询一视同仁,忽略了查询复杂度的差异,导致在简单查询上性能下降,且计算开销大。
- EA-GraphRAG通过语法分析提取查询复杂度特征,并据此动态选择RAG或GraphRAG,实现效率与准确率的平衡。
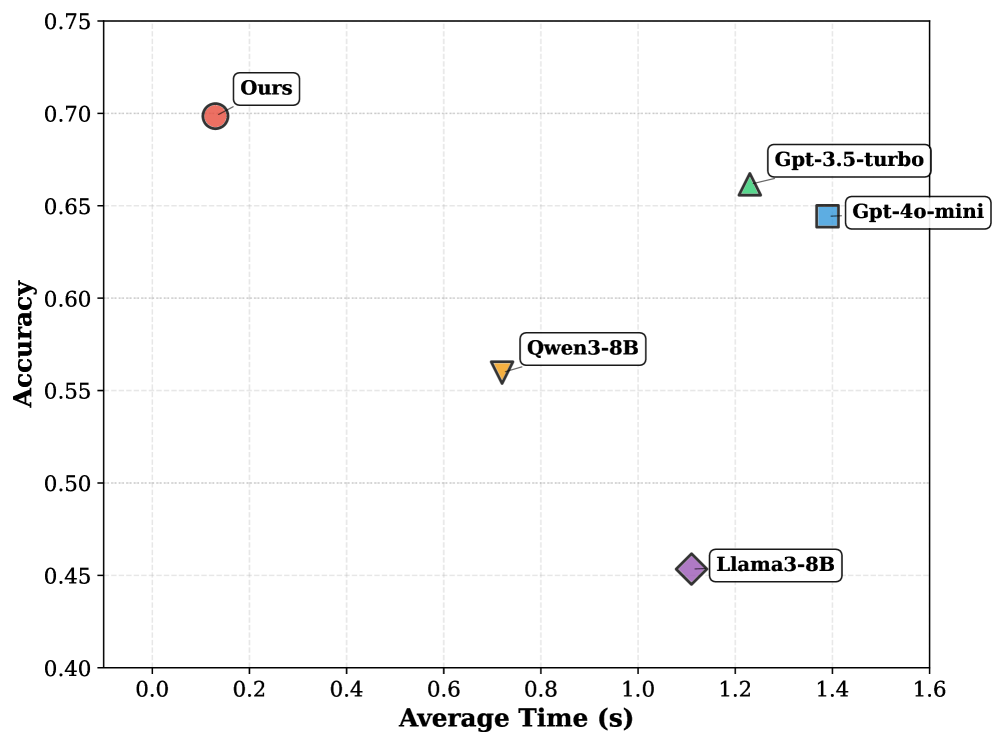
- 实验表明,EA-GraphRAG在混合查询场景中显著提升了准确率,降低了延迟,达到了state-of-the-art的性能。
📝 摘要(中文)
大型语言模型(LLMs)由于幻觉和过时的参数化知识,在知识密集型任务中表现不佳。检索增强生成(RAG)通过整合外部语料库来解决这个问题,但其有效性受到非结构化领域文档中碎片化信息的限制。图增强RAG(GraphRAG)通过结构化知识图谱增强上下文推理,但矛盾的是,在实际场景中表现不如普通RAG,尽管在复杂查询上有所提升,但准确率显著下降且延迟过高。我们认为,无论查询复杂度如何,都僵化地应用GraphRAG是根本原因。为了解决这个问题,我们提出了一个高效且自适应的GraphRAG框架,称为EA-GraphRAG,它通过语法感知复杂度分析动态地整合RAG和GraphRAG范式。我们的方法引入了:(i)一个语法特征构造器,用于解析每个查询并提取一组结构特征;(ii)一个轻量级的复杂度评分器,用于将这些特征映射到连续的复杂度分数;以及(iii)一个分数驱动的路由策略,该策略为低分查询选择密集RAG,为高分查询调用基于图的检索,并应用复杂度感知的倒数排名融合来处理边界情况。在包含两个单跳和两个多跳QA基准的综合基准上进行的大量实验表明,我们的EA-GraphRAG显著提高了准确率,降低了延迟,并在处理涉及简单和复杂查询的混合场景中实现了最先进的性能。
🔬 方法详解
问题定义:现有检索增强生成(RAG)方法在处理知识密集型任务时,面临着非结构化文档信息碎片化的问题。图增强RAG(GraphRAG)旨在通过知识图谱增强上下文推理,但实际应用中,对所有查询都采用GraphRAG导致简单查询性能下降,计算成本增加。因此,需要一种方法能够自适应地选择合适的检索方式,以兼顾准确率和效率。
核心思路:论文的核心思路是根据查询的复杂度动态地选择RAG或GraphRAG。对于简单的查询,使用传统的RAG方法,以避免引入不必要的图结构检索开销;对于复杂的查询,则使用GraphRAG方法,利用知识图谱进行更深入的推理。通过这种自适应的方式,可以提高整体的性能和效率。
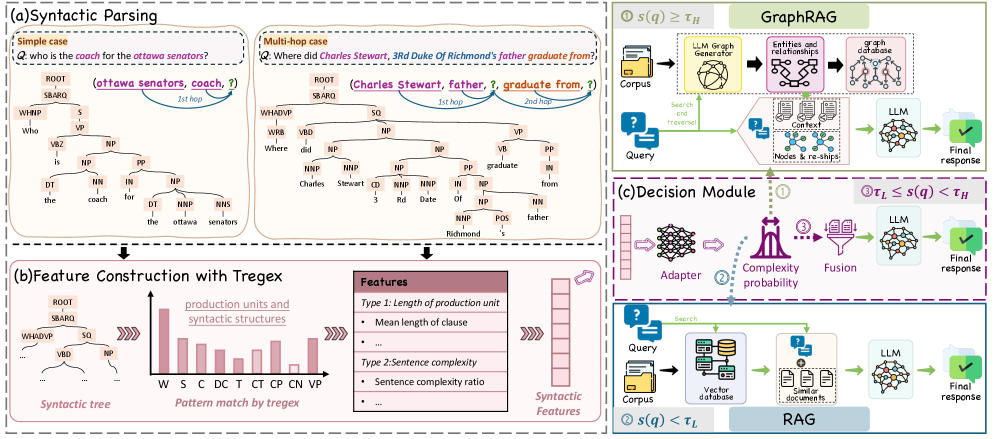
技术框架:EA-GraphRAG框架包含三个主要模块:(1) 语法特征构造器:解析查询语句,提取语法结构特征,例如依存关系、词性等。(2) 复杂度评分器:将提取的语法特征映射为一个连续的复杂度分数,用于衡量查询的复杂程度。(3) 分数驱动的路由策略:根据复杂度分数,选择合适的检索方式。低分查询使用密集RAG,高分查询使用GraphRAG,对于介于两者之间的查询,使用复杂度感知的倒数排名融合(Reciprocal Rank Fusion)策略。
关键创新:该方法最重要的创新点在于提出了一个自适应的RAG框架,能够根据查询的复杂度动态地选择RAG或GraphRAG。与现有方法相比,EA-GraphRAG避免了对所有查询都使用GraphRAG的僵化做法,从而提高了整体的性能和效率。通过语法特征构造器和复杂度评分器,实现了对查询复杂度的有效评估。
关键设计:语法特征构造器使用依存句法分析工具提取查询的结构特征,例如主谓宾关系、修饰关系等。复杂度评分器可以使用一个轻量级的机器学习模型(例如线性回归)将语法特征映射到复杂度分数。分数驱动的路由策略可以使用一个阈值来区分简单查询和复杂查询,并根据复杂度分数选择RAG或GraphRAG。倒数排名融合策略用于融合RAG和GraphRAG的结果,提高检索的准确率。
🖼️ 关键图片
📊 实验亮点
在包含单跳和多跳QA基准的综合实验中,EA-GraphRAG显著提高了准确率,降低了延迟,并在处理混合场景中达到了state-of-the-art的性能。具体数据未在摘要中给出,但强调了其在复杂度和效率上的平衡。
🎯 应用场景
EA-GraphRAG可应用于各种知识密集型问答系统、智能客服、信息检索等领域。通过自适应地选择RAG或GraphRAG,可以提高系统的准确率和效率,改善用户体验。该方法尤其适用于需要处理混合查询场景的应用,例如同时包含简单的事实性问题和复杂的推理问题的场景。
📄 摘要(原文)
Large language models (LLMs) often struggle with knowledge-intensive tasks due to hallucinations and outdated parametric knowledge. While Retrieval-Augmented Generation (RAG) addresses this by integrating external corpora, its effectiveness is limited by fragmented information in unstructured domain documents. Graph-augmented RAG (GraphRAG) emerged to enhance contextual reasoning through structured knowledge graphs, yet paradoxically underperforms vanilla RAG in real-world scenarios, exhibiting significant accuracy drops and prohibitive latency despite gains on complex queries. We identify the rigid application of GraphRAG to all queries, regardless of complexity, as the root cause. To resolve this, we propose an efficient and adaptive GraphRAG framework called EA-GraphRAG that dynamically integrates RAG and GraphRAG paradigms through syntax-aware complexity analysis. Our approach introduces: (i) a syntactic feature constructor that parses each query and extracts a set of structural features; (ii) a lightweight complexity scorer that maps these features to a continuous complexity score; and (iii) a score-driven routing policy that selects dense RAG for low-score queries, invokes graph-based retrieval for high-score queries, and applies complexity-aware reciprocal rank fusion to handle borderline cases. Extensive experiments on a comprehensive benchmark, consisting of two single-hop and two multi-hop QA benchmarks, demonstrate that our EA-GraphRAG significantly improves accuracy, reduces latency, and achieves state-of-the-art performance in handling mixed scenarios involving both simple and complex queries.