Assessing the Impact of Typological Features on Multilingual Machine Translation in the Age of Large Language Models
作者: Vitalii Hirak, Jaap Jumelet, Arianna Bisazza
分类: cs.CL
发布日期: 2026-02-03
备注: 19 pages, 11 figures, EACL 2026
💡 一句话要点
研究表明目标语言类型学特征显著影响大语言模型多语言翻译质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言机器翻译 语言类型学 大语言模型 翻译质量 NLLB-200 Tower+ FLORES+ MT
📋 核心要点
- 多语言翻译模型在不同语言间质量差异大,现有研究较少关注语言类型学特征的影响。
- 该研究分析了NLLB-200和Tower+两个先进模型,探究目标语言类型学与翻译质量的关系。
- 实验发现目标语言类型学显著影响翻译质量,特定类型语言受益于更广泛的搜索策略。
📝 摘要(中文)
尽管多语言建模取得了重大进展,但不同语言之间的翻译质量仍然存在巨大差异。除了训练资源不均的影响外,语言类型学特征也被认为是决定语言建模内在难度的因素。然而,现有的证据主要基于小型单语语言模型或从头开始训练的双语翻译模型。本文扩展了这项研究,分析了两个大型预训练多语言翻译模型NLLB-200和Tower+,它们分别是编码器-解码器和仅解码器机器翻译的代表。基于广泛的语言集合,我们发现目标语言类型学驱动着两种模型的翻译质量,即使在控制了诸如数据资源和书写脚本等更简单的因素之后也是如此。此外,具有某些类型学特征的语言可以从更广泛的输出空间搜索中获益,这表明这些语言可以从标准从左到右的集束搜索之外的替代解码策略中获利。为了促进该领域的进一步研究,我们发布了FLORES+ MT评估基准中212种语言的一组细粒度类型学属性。
🔬 方法详解
问题定义:论文旨在解决多语言机器翻译中,不同语言翻译质量差异显著的问题。现有研究主要集中在数据资源和模型架构上,忽略了语言本身固有的类型学特征对翻译难度的影响。现有方法难以解释和缓解由于语言类型学差异导致的翻译质量不平衡。
核心思路:论文的核心思路是研究目标语言的类型学特征与多语言翻译模型性能之间的关系。通过分析大型预训练模型在不同类型语言上的翻译表现,揭示语言类型学对翻译质量的影响,并探索针对特定类型语言的优化策略。
技术框架:论文使用两个代表性的多语言翻译模型:NLLB-200(编码器-解码器结构)和Tower+(仅解码器结构)。研究流程包括:1) 选择FLORES+ MT评估基准中的多种语言;2) 收集这些语言的细粒度类型学属性;3) 使用NLLB-200和Tower+进行翻译实验;4) 分析翻译质量(如BLEU得分)与语言类型学特征之间的相关性。
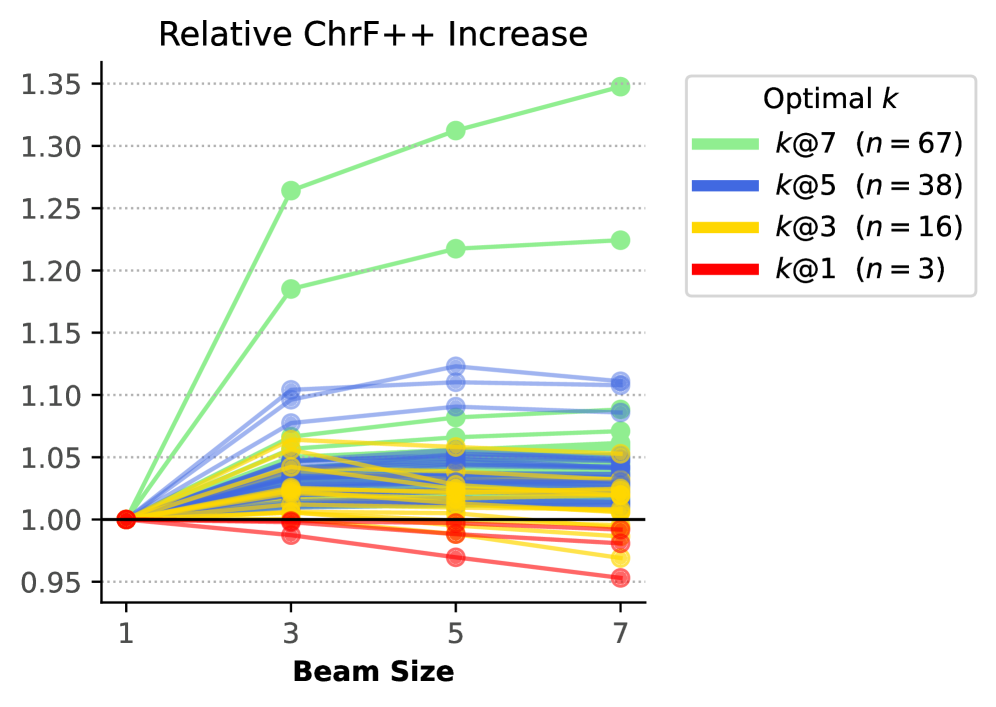
关键创新:论文的关键创新在于:1) 系统性地研究了语言类型学特征对大型预训练多语言翻译模型性能的影响,填补了该领域的研究空白;2) 揭示了目标语言类型学是影响翻译质量的重要因素,即使在控制了数据资源等因素后仍然显著;3) 提出了针对特定类型语言的优化思路,例如更广泛的输出空间搜索。
关键设计:论文的关键设计包括:1) 选择了具有代表性的编码器-解码器和仅解码器模型,以保证结论的普适性;2) 使用了FLORES+ MT评估基准,保证了实验结果的可比性;3) 收集了细粒度的语言类型学属性,为深入分析提供了数据基础;4) 考虑了数据资源和书写脚本等混淆因素,保证了研究结果的可靠性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,目标语言的类型学特征显著影响NLLB-200和Tower+的翻译质量,即使控制了数据资源和书写脚本等因素。特定类型学特征的语言,如具有复杂形态的语言,从更广泛的输出空间搜索中获益,BLEU得分有显著提升。该研究还发布了212种语言的细粒度类型学属性数据集。
🎯 应用场景
该研究成果可应用于改进多语言机器翻译系统,尤其是在资源匮乏语言的翻译质量提升方面。通过理解语言类型学对翻译的影响,可以设计更有效的模型架构和训练策略,实现更公平、高质量的多语言翻译服务。此外,该研究也为跨语言自然语言处理任务提供了新的视角。
📄 摘要(原文)
Despite major advances in multilingual modeling, large quality disparities persist across languages. Besides the obvious impact of uneven training resources, typological properties have also been proposed to determine the intrinsic difficulty of modeling a language. The existing evidence, however, is mostly based on small monolingual language models or bilingual translation models trained from scratch. We expand on this line of work by analyzing two large pre-trained multilingual translation models, NLLB-200 and Tower+, which are state-of-the-art representatives of encoder-decoder and decoder-only machine translation, respectively. Based on a broad set of languages, we find that target language typology drives translation quality of both models, even after controlling for more trivial factors, such as data resourcedness and writing script. Additionally, languages with certain typological properties benefit more from a wider search of the output space, suggesting that such languages could profit from alternative decoding strategies beyond the standard left-to-right beam search. To facilitate further research in this area, we release a set of fine-grained typological properties for 212 languages of the FLORES+ MT evaluation benchmark.