SEAD: Self-Evolving Agent for Multi-Turn Service Dialogue
作者: Yuqin Dai, Ning Gao, Wei Zhang, Jie Wang, Zichen Luo, Jinpeng Wang, Yujie Wang, Ruiyuan Wu, Chaozheng Wang
分类: cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出SEAD自进化Agent,解决服务对话中数据匮乏和用户行为模拟难题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 服务对话 自进化Agent 用户建模 强化学习 自然语言处理 人机交互 对话系统
📋 核心要点
- 现有服务对话模型依赖低质量人工数据,难以模拟真实用户行为,导致性能不佳。
- SEAD框架通过解耦用户建模,利用Profile Controller和User Role-play Model生成自适应训练场景。
- 实验表明,SEAD显著提升了任务完成率和对话效率,优于现有开源和闭源模型。
📝 摘要(中文)
大型语言模型在开放域对话中表现出卓越的能力。然而,当前方法在服务对话中表现欠佳,因为它们依赖于嘈杂、低质量的人工对话数据。这种局限性源于数据稀缺以及模拟真实、目标导向的用户行为的困难。为了解决这些问题,我们提出了SEAD(Self-Evolving Agent for Service Dialogue),该框架使智能体能够在没有大规模人工标注的情况下学习有效的策略。SEAD将用户建模解耦为两个组件:一个Profile Controller,用于生成多样化的用户状态以管理训练课程;以及一个User Role-play Model,专注于真实的角色扮演。这种设计确保环境提供自适应的训练场景,而不是充当不公平的对手。实验表明,SEAD显著优于开源基础模型和闭源商业模型,任务完成率提高了17.6%,对话效率提高了11.1%。代码可在https://github.com/Da1yuqin/SEAD获取。
🔬 方法详解
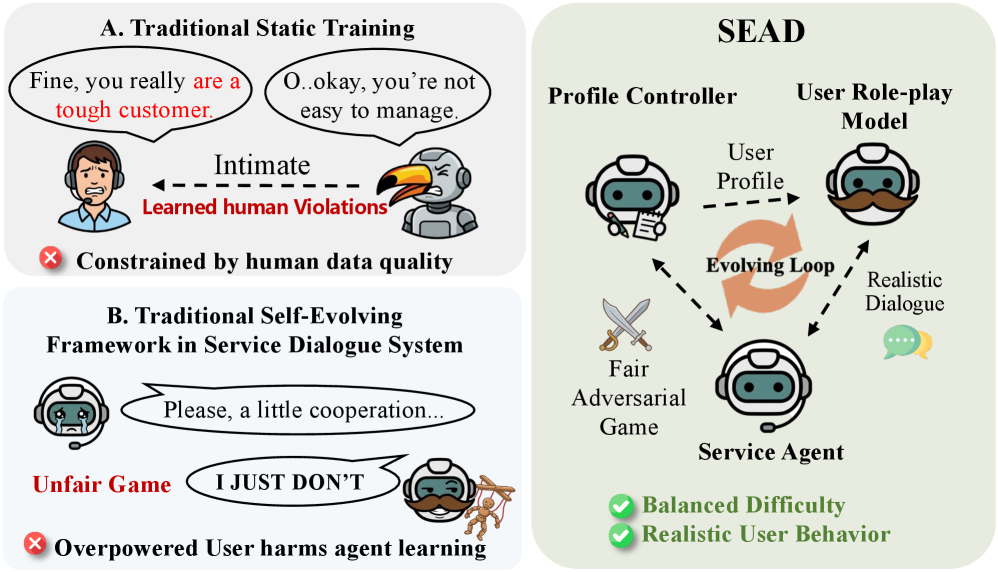
问题定义:论文旨在解决服务对话中数据稀缺和难以模拟真实用户行为的问题。现有方法依赖于人工标注的对话数据,但这些数据通常质量不高,且难以覆盖各种用户意图和行为模式。这导致模型在实际应用中表现不佳,无法有效地完成服务对话任务。
核心思路:论文的核心思路是利用自进化Agent来生成高质量的训练数据,从而避免对大规模人工标注数据的依赖。通过解耦用户建模,分别控制用户状态的多样性和角色扮演的真实性,使得Agent能够在一个自适应的环境中学习有效的对话策略。
技术框架:SEAD框架包含两个主要模块:Profile Controller和User Role-play Model。Profile Controller负责生成多样化的用户状态,用于管理训练课程,确保Agent能够接触到各种不同的用户意图和需求。User Role-play Model则专注于真实的角色扮演,模拟用户的对话行为,使得Agent能够学习如何与用户进行有效的交互。这两个模块共同构成了一个自适应的训练环境,Agent可以在其中不断学习和进化。
关键创新:SEAD的关键创新在于其自进化的训练方式和解耦的用户建模方法。与传统的监督学习方法不同,SEAD不需要大规模的人工标注数据,而是通过Agent自身与环境的交互来学习。同时,通过将用户建模解耦为Profile Controller和User Role-play Model,可以更好地控制训练数据的多样性和真实性,从而提高Agent的学习效率和泛化能力。
关键设计:Profile Controller的设计需要考虑如何生成多样化的用户状态,例如用户意图、偏好、知识水平等。User Role-play Model的设计需要考虑如何模拟用户的对话行为,例如用户的表达方式、语气、反应等。具体的参数设置、损失函数和网络结构需要根据具体的服务对话任务进行调整和优化。论文中可能使用了强化学习等方法来训练Agent,并设计了相应的奖励函数来引导Agent学习有效的对话策略。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SEAD框架在服务对话任务中显著优于现有的开源和闭源模型。具体而言,SEAD的任务完成率提高了17.6%,对话效率提高了11.1%。这些数据表明,SEAD在解决数据稀缺和服务对话难题方面具有显著优势。
🎯 应用场景
SEAD框架可应用于各种服务对话场景,例如智能客服、在线咨询、任务导向型对话系统等。通过自进化学习,该框架能够降低对人工标注数据的依赖,提高对话系统的智能化水平和服务质量。未来,SEAD有望在人机交互领域发挥重要作用,提升用户体验。
📄 摘要(原文)
Large Language Models have demonstrated remarkable capabilities in open-domain dialogues. However, current methods exhibit suboptimal performance in service dialogues, as they rely on noisy, low-quality human conversation data. This limitation arises from data scarcity and the difficulty of simulating authentic, goal-oriented user behaviors. To address these issues, we propose SEAD (Self-Evolving Agent for Service Dialogue), a framework that enables agents to learn effective strategies without large-scale human annotations. SEAD decouples user modeling into two components: a Profile Controller that generates diverse user states to manage training curriculum, and a User Role-play Model that focuses on realistic role-playing. This design ensures the environment provides adaptive training scenarios rather than acting as an unfair adversary. Experiments demonstrate that SEAD significantly outperforms Open-source Foundation Models and Closed-source Commercial Models, improving task completion rate by 17.6% and dialogue efficiency by 11.1%. Code is available at: https://github.com/Da1yuqin/SEAD.