Can Large Language Models Generalize Procedures Across Representations?
作者: Fangru Lin, Valentin Hofmann, Xingchen Wan, Weixing Wang, Zifeng Ding, Anthony G. Cohn, Janet B. Pierrehumbert
分类: cs.CL, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出两阶段数据课程学习方法,提升LLM在代码、图和自然语言表示之间的程序泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 跨表示泛化 数据课程学习 自然语言处理 代码生成 图表示 程序规划
📋 核心要点
- 现有LLM在符号表示(代码、图)上表现良好,但在泛化到自然语言描述的任务时存在困难。
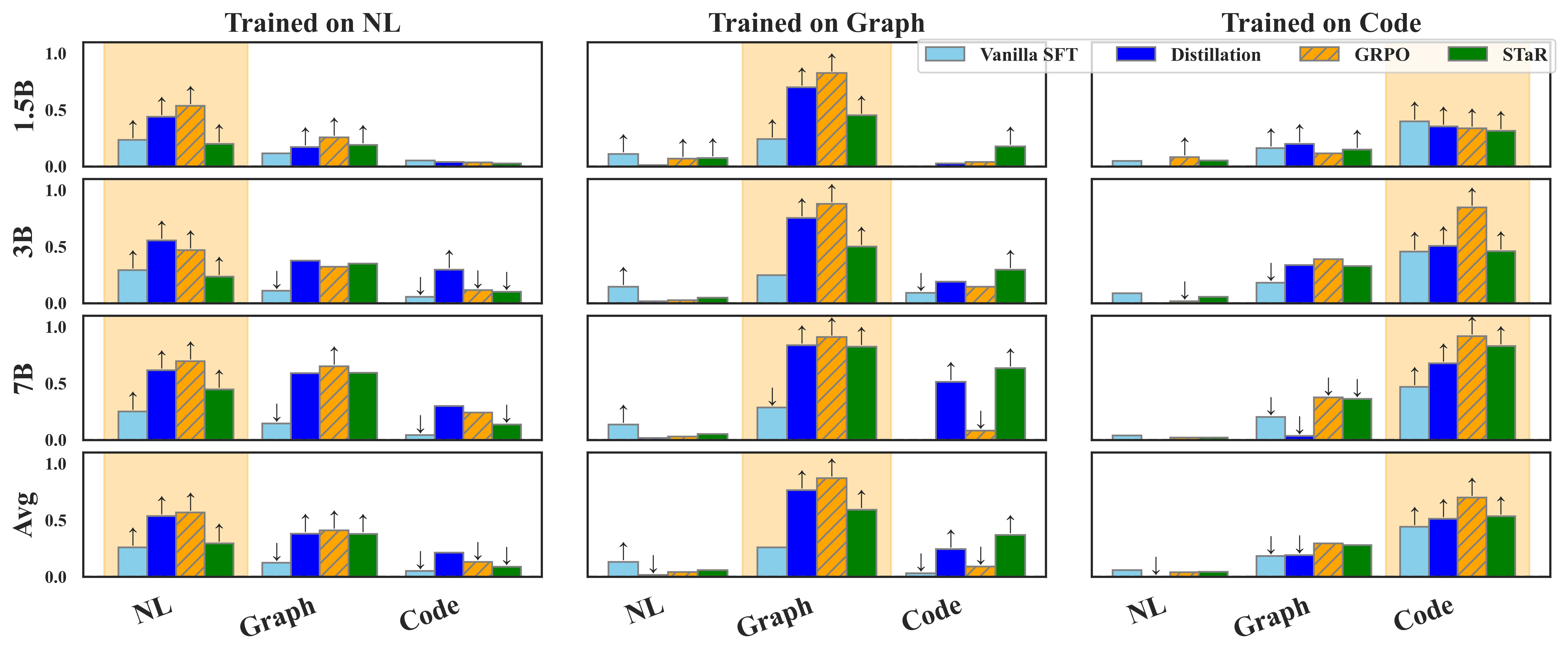
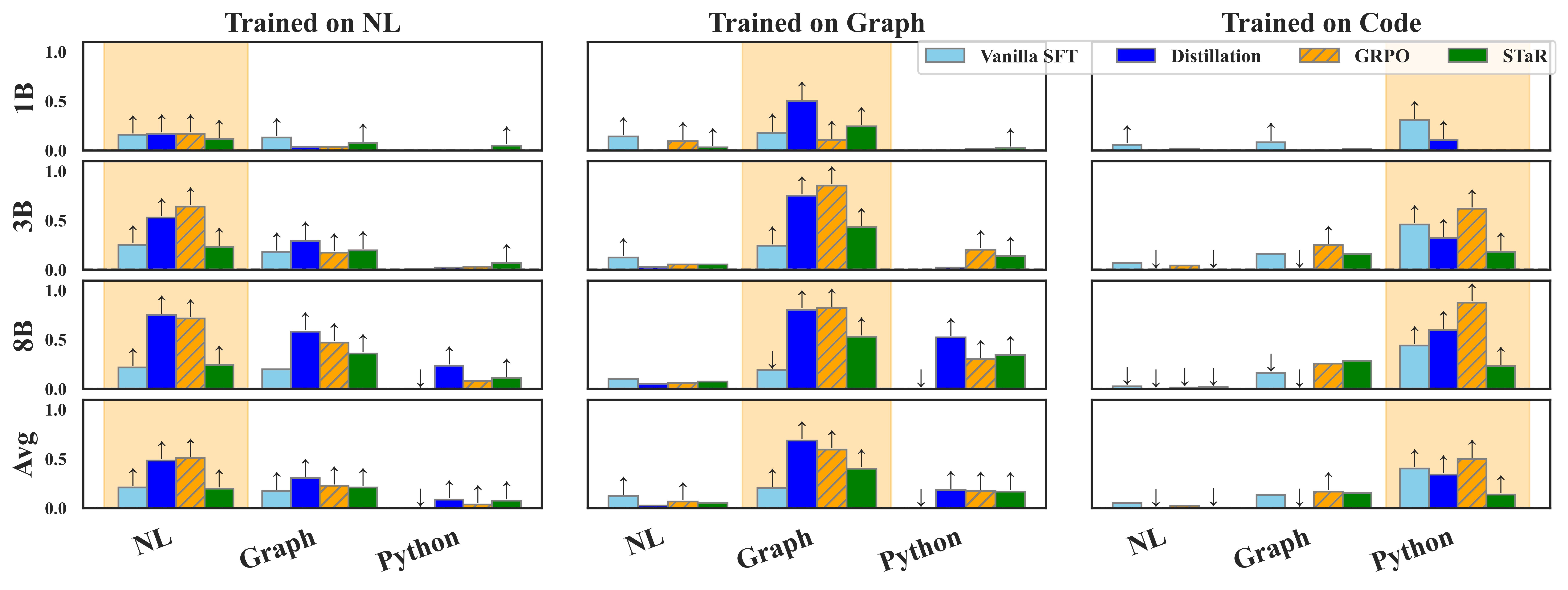
- 论文提出一种两阶段数据课程学习方法,先在符号数据上训练,再在自然语言数据上训练,提升泛化能力。
- 实验表明,该方法显著提升了模型在跨表示任务上的性能,甚至使小模型能媲美GPT-4o。
📝 摘要(中文)
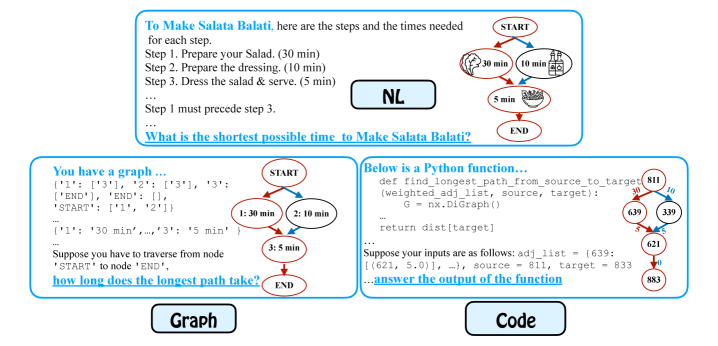
大型语言模型(LLM)在代码和图等符号表示上进行了广泛的训练和测试,但现实世界的用户任务通常以自然语言指定。LLM在这些表示之间泛化的程度如何?本文通过研究涉及以代码、图和自然语言表示的同构任务(例如,规划中的调度步骤)来探讨这个问题。研究发现,仅使用图或代码数据训练LLM并不能可靠地泛化到相应的自然语言任务,而仅使用自然语言进行训练可能导致低效的性能提升。为了解决这个差距,我们提出了一种两阶段数据课程,首先在符号数据上训练,然后在自然语言数据上训练。该课程显著提高了模型在不同模型系列和任务中的性能。值得注意的是,通过我们的方法训练的15亿参数的Qwen模型可以在自然规划中与zero-shot GPT-4o相媲美。最后,我们的分析表明,成功的跨表示泛化可以解释为一种生成类比,而我们的课程有效地鼓励了这种类比。
🔬 方法详解
问题定义:现有的大型语言模型在代码和图等符号表示上表现出色,但在处理现实世界中以自然语言描述的任务时,其泛化能力受到限制。直接在自然语言数据上训练虽然可行,但效率较低,难以充分利用模型在符号表示上已经学习到的知识。因此,如何使LLM能够有效地在不同表示形式(代码、图、自然语言)之间进行程序泛化是一个关键问题。
核心思路:论文的核心思路是采用一种两阶段的数据课程学习方法。首先,利用代码和图等符号表示的数据训练LLM,使其掌握程序的基本结构和逻辑。然后,再使用自然语言数据进行微调,使模型能够将这些结构和逻辑与自然语言描述联系起来,从而实现跨表示的泛化。这种方法借鉴了人类学习的模式,即先学习抽象概念,再将其应用于具体实例。
技术框架:该方法主要包含两个阶段:第一阶段是符号表示训练阶段,使用代码或图数据对LLM进行训练,目标是让模型学习到程序的基本结构和逻辑。第二阶段是自然语言训练阶段,使用自然语言描述的任务数据对模型进行微调,目标是让模型能够将符号表示的知识迁移到自然语言表示上。整个框架的关键在于数据课程的设计,即如何选择和组织不同阶段的数据,以及如何控制训练的顺序和比例。
关键创新:该方法最重要的创新点在于提出了两阶段数据课程学习策略,有效地解决了LLM在不同表示形式之间泛化能力不足的问题。与传统的单阶段训练方法相比,该方法能够更好地利用模型在符号表示上已经学习到的知识,从而提高了训练效率和泛化性能。此外,该研究还发现,成功的跨表示泛化可以解释为一种生成类比,而所提出的课程有效地鼓励了这种类比。
关键设计:在数据课程的设计上,需要仔细选择和组织不同阶段的数据。例如,在符号表示训练阶段,可以使用大量的代码或图数据,以确保模型能够充分学习到程序的基本结构和逻辑。在自然语言训练阶段,可以使用少量但高质量的自然语言描述的任务数据,以确保模型能够将符号表示的知识有效地迁移到自然语言表示上。此外,还需要控制两个阶段的训练比例和顺序,以避免模型过度拟合符号表示或自然语言表示。
🖼️ 关键图片
📊 实验亮点
实验结果表明,所提出的两阶段数据课程学习方法能够显著提高LLM在跨表示任务上的性能。例如,使用该方法训练的15亿参数的Qwen模型在自然规划任务中可以与zero-shot GPT-4o相媲美。此外,实验还验证了该方法在不同模型系列和任务中的有效性,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于智能助手、自动化规划、代码生成等领域。例如,可以训练一个能够理解自然语言指令并将其转化为代码或图表示的智能助手,从而实现更灵活和高效的任务执行。此外,该方法还可以用于自动化规划,根据自然语言描述的任务目标自动生成规划方案。未来,该研究有望推动LLM在更广泛的实际应用中发挥作用。
📄 摘要(原文)
Large language models (LLMs) are trained and tested extensively on symbolic representations such as code and graphs, yet real-world user tasks are often specified in natural language. To what extent can LLMs generalize across these representations? Here, we approach this question by studying isomorphic tasks involving procedures represented in code, graphs, and natural language (e.g., scheduling steps in planning). We find that training LLMs with popular post-training methods on graphs or code data alone does not reliably generalize to corresponding natural language tasks, while training solely on natural language can lead to inefficient performance gains. To address this gap, we propose a two-stage data curriculum that first trains on symbolic, then natural language data. The curriculum substantially improves model performance across model families and tasks. Remarkably, a 1.5B Qwen model trained by our method can closely match zero-shot GPT-4o in naturalistic planning. Finally, our analysis suggests that successful cross-representation generalization can be interpreted as a form of generative analogy, which our curriculum effectively encourages.