Learning to Reason Faithfully through Step-Level Faithfulness Maximization
作者: Runquan Gui, Yafu Li, Xiaoye Qu, Ziyan Liu, Yeqiu Cheng, Yu Cheng
分类: cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出FaithRL框架,通过最大化步骤级忠实度提升LLM推理能力,减少幻觉。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理 忠实度 幻觉 奖励设计 优势调制
📋 核心要点
- 现有基于可验证奖励的强化学习方法对中间步骤监督不足,导致LLM过度自信和虚假推理,增加了幻觉。
- FaithRL框架通过直接优化推理的忠实度来解决这一问题,形式化了忠实度最大化目标,并设计了几何奖励。
- 实验表明,FaithRL在降低幻觉率的同时,保持甚至提高了答案的正确性,并提升了逐步推理的忠实度。
📝 摘要(中文)
本文提出FaithRL,一个通用的强化学习框架,旨在直接优化推理的忠实度,以解决大型语言模型(LLM)在多步推理任务中过度自信和虚假推理的问题,这些问题会导致幻觉。FaithRL形式化了一个忠实度最大化的目标,并在理论上证明了优化该目标可以减轻过度自信。为了实现这一目标,本文引入了一种几何奖励设计和一个忠实度感知的优势调制机制,该机制通过惩罚不支持的步骤来分配步骤级的信用,同时保留有效的局部推导。在不同的backbone和benchmark上,FaithRL始终如一地降低了幻觉率,同时保持(并且通常提高)了答案的正确性。进一步的分析证实,FaithRL提高了逐步推理的忠实度,并具有强大的泛化能力。代码已开源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多步推理任务中存在的幻觉问题。现有方法,如基于可验证奖励的强化学习(RLVR),主要依赖于稀疏的结果导向奖励,缺乏对中间推理步骤的有效监督。这导致模型容易产生过度自信和虚假推理,最终生成不准确甚至错误的答案,即产生幻觉。
核心思路:FaithRL的核心思路是通过直接优化推理过程的忠实度来解决幻觉问题。论文认为,如果模型在每一步推理都能够提供可靠的证据支持,那么最终结果的准确性就能得到保证。因此,FaithRL的目标是最大化每一步推理的忠实度,鼓励模型进行有依据的推理,从而减少幻觉的产生。
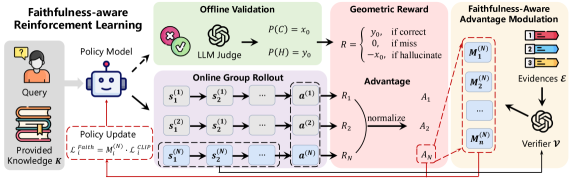
技术框架:FaithRL是一个通用的强化学习框架,其整体流程如下:首先,模型生成多步推理过程;然后,FaithRL评估每一步推理的忠实度,并基于此设计奖励信号;接着,利用强化学习算法优化模型,使其倾向于生成更忠实的推理过程。框架包含两个主要模块:几何奖励设计和忠实度感知的优势调制机制。几何奖励设计用于量化每一步推理的忠实度,而忠实度感知的优势调制机制则用于将忠实度信息融入到强化学习的训练过程中。
关键创新:FaithRL最重要的技术创新在于其直接优化推理忠实度的目标。与传统的RLVR方法不同,FaithRL不再仅仅关注最终结果的正确性,而是更加关注中间推理步骤的合理性和可靠性。通过引入几何奖励设计和忠实度感知的优势调制机制,FaithRL能够有效地引导模型进行有依据的推理,从而显著降低幻觉率。
关键设计:几何奖励设计是FaithRL的关键组成部分,它通过计算每一步推理与其支持证据之间的几何距离来量化忠实度。具体来说,如果某一步推理能够找到充分的证据支持,则给予较高的奖励;反之,如果找不到证据支持,则给予较低的奖励甚至惩罚。忠实度感知的优势调制机制则根据每一步推理的忠实度调整强化学习的优势函数,使得模型更加重视忠实的推理步骤,从而加速训练过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FaithRL在多个benchmark上都取得了显著的性能提升。例如,在某些数据集上,FaithRL将幻觉率降低了超过50%,同时保持甚至提高了答案的正确率。此外,实验还证明了FaithRL具有良好的泛化能力,能够在不同的backbone和数据集上稳定地工作。
🎯 应用场景
FaithRL框架具有广泛的应用前景,可用于提升LLM在需要复杂推理的各种任务中的性能,例如问答系统、知识图谱推理、代码生成等。通过降低幻觉率,FaithRL可以提高LLM的可靠性和可信度,使其更适用于对准确性要求较高的场景,例如医疗诊断、金融分析等。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has markedly improved the performance of Large Language Models (LLMs) on tasks requiring multi-step reasoning. However, most RLVR pipelines rely on sparse outcome-based rewards, providing little supervision over intermediate steps and thus encouraging over-confidence and spurious reasoning, which in turn increases hallucinations. To address this, we propose FaithRL, a general reinforcement learning framework that directly optimizes reasoning faithfulness. We formalize a faithfulness-maximization objective and theoretically show that optimizing it mitigates over-confidence. To instantiate this objective, we introduce a geometric reward design and a faithfulness-aware advantage modulation mechanism that assigns step-level credit by penalizing unsupported steps while preserving valid partial derivations. Across diverse backbones and benchmarks, FaithRL consistently reduces hallucination rates while maintaining (and often improving) answer correctness. Further analysis confirms that FaithRL increases step-wise reasoning faithfulness and generalizes robustly. Our code is available at https://github.com/aintdoin/FaithRL.