SWE-World: Building Software Engineering Agents in Docker-Free Environments
作者: Shuang Sun, Huatong Song, Lisheng Huang, Jinhao Jiang, Ran Le, Zhihao Lv, Zongchao Chen, Yiwen Hu, Wenyang Luo, Wayne Xin Zhao, Yang Song, Hongteng Xu, Tao Zhang, Ji-Rong Wen
分类: cs.SE, cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出SWE-World,一个无Docker环境的软件工程Agent训练框架,提升代码修改任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件工程Agent 大型语言模型 代理环境 无Docker环境 代码修改 测试时扩展 强化学习 代码生成
📋 核心要点
- 现有软件工程Agent依赖容器化环境进行训练,资源消耗大,维护成本高,限制了Agent的训练和扩展。
- SWE-World通过学习一个LLM代理环境,预测执行结果和测试反馈,无需实际运行代码即可训练Agent。
- 实验表明,SWE-World显著提升了Agent在SWE-bench Verified上的性能,结合测试时扩展技术效果更佳。
📝 摘要(中文)
本文提出SWE-World,一个无需Docker的框架,用于训练和评估软件工程Agent。现有方法依赖容器化环境的执行反馈,需要完整的依赖设置和程序的物理执行与测试,资源密集且难以维护,严重阻碍了Agent的训练和可扩展性。SWE-World利用基于LLM的模型,该模型基于真实Agent-环境交互数据进行训练,以预测中间执行结果和最终测试反馈,从而使Agent无需与物理容器化环境交互即可学习。这种设计保留了标准的Agent-环境交互循环,同时消除了Agent优化和评估期间昂贵的环境构建和维护需求。此外,由于SWE-World可以在没有真实提交的情况下模拟候选轨迹的最终评估结果,因此它可以在多个测试时尝试中选择最佳解决方案,从而促进软件工程任务中有效的测试时扩展(TTS)。在SWE-bench Verified上的实验表明,通过无Docker的SFT,Qwen2.5-Coder-32B从6.2%提高到52.0%,通过无Docker的RL提高到55.0%,并通过进一步的TTS提高到68.2%。
🔬 方法详解
问题定义:现有软件工程Agent的训练和评估严重依赖于容器化的执行环境。这种方法需要构建和维护复杂的依赖关系,并且每次交互都需要实际执行代码和测试,导致资源消耗巨大,训练效率低下,难以扩展到更复杂的任务和更大的模型。现有方法的痛点在于对真实物理环境的过度依赖。
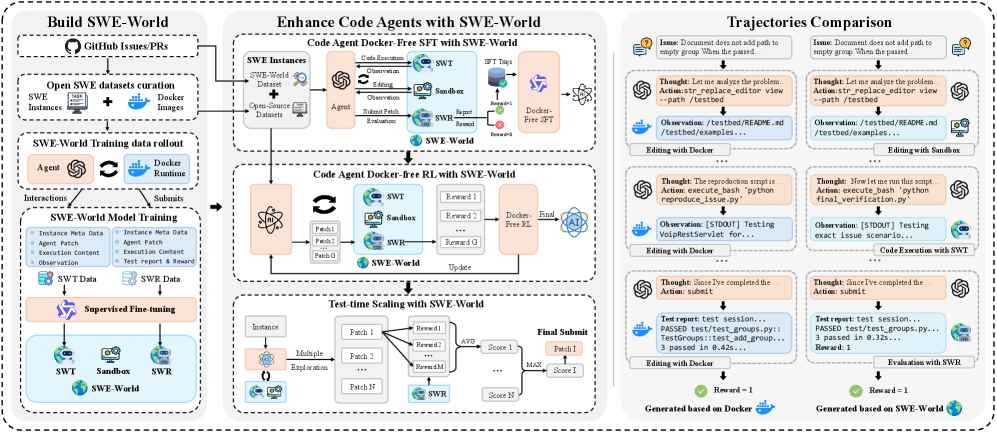
核心思路:SWE-World的核心思路是用一个学习到的代理环境(Learned Surrogate Environment)来替代真实的物理执行环境。这个代理环境基于LLM,通过学习大量的Agent-环境交互数据,能够预测代码执行的中间结果和最终的测试反馈。这样,Agent就可以在无需实际运行代码的情况下进行训练和评估,从而大大降低了资源消耗和维护成本。
技术框架:SWE-World的整体框架包括以下几个主要模块:1) 数据收集模块:收集真实Agent与环境交互的数据,包括Agent的动作、代码修改、执行结果和测试反馈。2) 代理环境训练模块:使用收集到的数据训练一个基于LLM的代理环境,使其能够预测给定Agent动作后的执行结果和测试反馈。3) Agent训练模块:使用代理环境训练软件工程Agent,Agent通过与代理环境交互来学习如何修改代码以通过测试。4) 测试时扩展模块:在测试阶段,Agent可以生成多个候选解决方案,并使用代理环境预测它们的最终评估结果,选择最佳解决方案。
关键创新:SWE-World最重要的技术创新点在于使用学习到的代理环境来替代真实的物理执行环境。这与现有方法依赖真实环境进行训练和评估形成了本质区别。通过这种方式,SWE-World可以显著降低资源消耗和维护成本,提高训练效率,并支持测试时扩展。
关键设计:SWE-World的关键设计包括:1) 使用LLM作为代理环境的基础模型,利用LLM强大的建模能力来预测代码执行结果。2) 使用真实Agent-环境交互数据来训练代理环境,保证代理环境的准确性和可靠性。3) 设计合适的损失函数来优化代理环境,使其能够准确预测中间执行结果和最终测试反馈。4) 实现测试时扩展,允许Agent生成多个候选解决方案,并选择最佳方案。
🖼️ 关键图片

📊 实验亮点
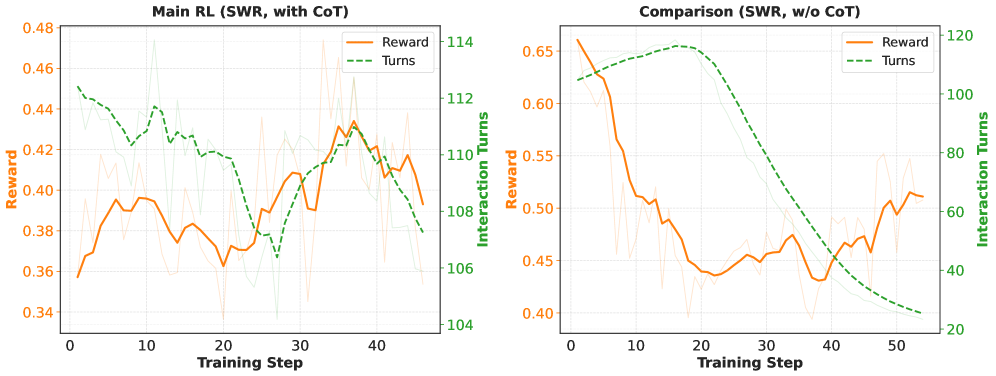
实验结果表明,SWE-World能够显著提升软件工程Agent的性能。例如,在SWE-bench Verified数据集上,使用Qwen2.5-Coder-32B模型,通过无Docker的SFT,性能从6.2%提升到52.0%,通过无Docker的RL提升到55.0%,进一步结合测试时扩展(TTS)技术,性能提升到68.2%。这些结果表明,SWE-World是一种有效的软件工程Agent训练框架。
🎯 应用场景
SWE-World具有广泛的应用前景,可用于训练和评估各种软件工程Agent,例如代码自动补全、代码修复、代码重构等。它还可以应用于软件工程教育,帮助学生在无需搭建复杂环境的情况下学习软件开发。此外,SWE-World还可以用于自动化软件测试,通过模拟不同的测试场景来发现潜在的软件缺陷。
📄 摘要(原文)
Recent advances in large language models (LLMs) have enabled software engineering agents to tackle complex code modification tasks. Most existing approaches rely on execution feedback from containerized environments, which require dependency-complete setup and physical execution of programs and tests. While effective, this paradigm is resource-intensive and difficult to maintain, substantially complicating agent training and limiting scalability. We propose SWE-World, a Docker-free framework that replaces physical execution environments with a learned surrogate for training and evaluating software engineering agents. SWE-World leverages LLM-based models trained on real agent-environment interaction data to predict intermediate execution outcomes and final test feedback, enabling agents to learn without interacting with physical containerized environments. This design preserves the standard agent-environment interaction loop while eliminating the need for costly environment construction and maintenance during agent optimization and evaluation. Furthermore, because SWE-World can simulate the final evaluation outcomes of candidate trajectories without real submission, it enables selecting the best solution among multiple test-time attempts, thereby facilitating effective test-time scaling (TTS) in software engineering tasks. Experiments on SWE-bench Verified demonstrate that SWE-World raises Qwen2.5-Coder-32B from 6.2\% to 52.0\% via Docker-free SFT, 55.0\% with Docker-free RL, and 68.2\% with further TTS. The code is available at https://github.com/RUCAIBox/SWE-World