Verified Critical Step Optimization for LLM Agents
作者: Mukai Li, Qingcheng Zeng, Tianqing Fang, Zhenwen Liang, Linfeng Song, Qi Liu, Haitao Mi, Dong Yu
分类: cs.CL
发布日期: 2026-02-03
备注: Working in progress
💡 一句话要点
提出关键步骤优化(CSO)方法,提升LLM Agent在复杂任务中的表现
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 后训练 强化学习 关键步骤优化 偏好学习
📋 核心要点
- 现有LLM Agent后训练方法在奖励分配、噪声控制和计算成本方面存在不足,难以有效提升复杂任务性能。
- CSO方法通过识别并验证关键步骤,利用专家模型提供高质量替代方案,实现细粒度、可验证的监督学习。
- 实验表明,CSO在GAIA-Text-103和XBench-DeepSearch上显著优于SFT基线和其他后训练方法,且监督成本较低。
📝 摘要(中文)
大型语言模型Agent在处理日益复杂的长程任务时,有效的后训练至关重要。先前的工作面临根本性挑战:仅凭结果的奖励无法准确地将功劳归于中间步骤,估计的步骤级奖励会引入系统性噪声,以及用于步骤奖励估计的蒙特卡洛抽样方法会产生过高的计算成本。受到只有一小部分高熵token驱动有效推理强化学习的发现的启发,我们提出了关键步骤优化(CSO),它专注于对已验证的关键步骤进行偏好学习,这些决策点上的替代行动可以显著地将任务结果从失败转为成功。至关重要的是,我们的方法从失败的策略轨迹而不是专家演示开始,直接针对策略模型的弱点。我们使用过程奖励模型(PRM)来识别候选关键步骤,利用专家模型来提出高质量的替代方案,然后使用策略模型本身从这些替代方案继续执行直到任务完成。只有策略成功执行以纠正结果的替代方案才会被验证并用作DPO训练数据,从而确保质量和策略可达性。这在关键决策中产生细粒度的、可验证的监督,同时避免了轨迹级别的粗糙性和步骤级别的噪声。在GAIA-Text-103和XBench-DeepSearch上的实验表明,CSO相对于SFT基线实现了37%和26%的相对改进,并且大大优于其他后训练方法,同时仅需要在16%的轨迹步骤上进行监督。这证明了基于选择性验证的学习对于Agent后训练的有效性。
🔬 方法详解
问题定义:现有的大语言模型Agent在处理复杂长程任务时,后训练方法面临挑战。基于结果的奖励信号稀疏且难以准确归因到中间步骤,导致学习效率低下。而步骤级别的奖励估计又容易引入噪声,影响学习的稳定性。此外,蒙特卡洛采样等方法计算成本高昂,难以应用到复杂任务中。
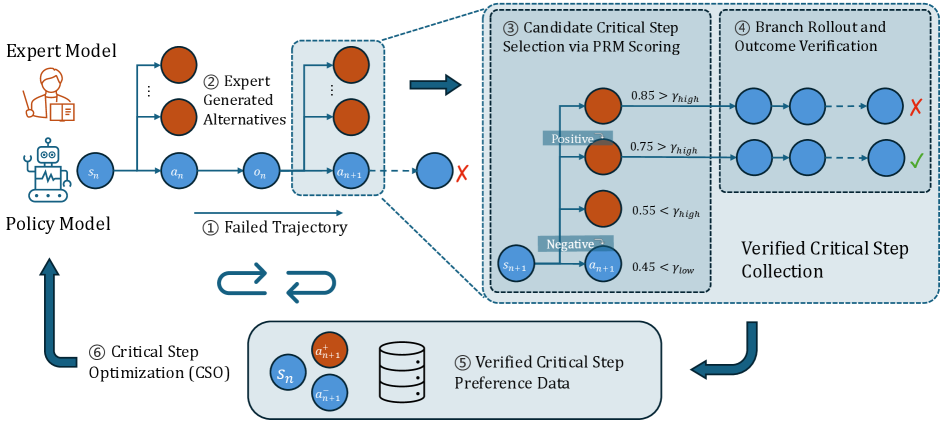
核心思路:论文的核心思路是聚焦于“关键步骤”的优化。关键步骤是指那些能够显著影响任务结果的决策点,即采取不同的行动会导致任务从失败转向成功。通过对这些关键步骤进行精确的监督和优化,可以更有效地提升Agent的整体性能。这种方法避免了对整个轨迹进行粗粒度的监督,也避免了对所有步骤进行细粒度的监督,从而在效率和效果之间取得了平衡。
技术框架:CSO方法包含以下几个主要阶段:1) 从失败的策略轨迹开始,直接针对策略模型的弱点。2) 使用过程奖励模型(PRM)识别候选的关键步骤。3) 利用专家模型为这些关键步骤提出高质量的替代行动。4) 从这些替代行动开始,使用策略模型继续执行任务,直到完成。5) 只有那些能够成功纠正任务结果的替代行动才会被验证,并用于DPO训练。
关键创新:CSO方法的关键创新在于其选择性验证的学习策略。它不是盲目地对所有步骤进行监督,而是只关注那些经过验证的关键步骤。这种方法确保了监督信号的质量和相关性,避免了噪声的干扰。此外,CSO方法从失败的轨迹开始,直接针对策略模型的弱点进行学习,这与传统的从专家演示中学习的方法不同,更具有针对性和效率。
关键设计:CSO方法使用过程奖励模型(PRM)来识别候选关键步骤。PRM可以学习预测每个步骤对最终任务结果的贡献。专家模型用于生成高质量的替代行动,这些替代行动需要足够好,能够纠正任务结果。DPO(Direct Preference Optimization)被用作训练方法,利用验证过的关键步骤数据来优化策略模型。关键步骤的选择比例和专家模型的质量是影响CSO性能的重要参数。
🖼️ 关键图片

📊 实验亮点
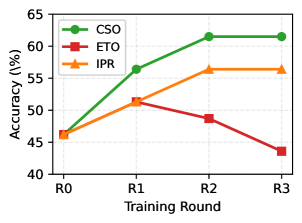
实验结果表明,CSO方法在GAIA-Text-103和XBench-DeepSearch两个数据集上,相对于SFT基线分别取得了37%和26%的相对改进。同时,CSO方法也显著优于其他后训练方法,例如ReAct和Dagger。值得注意的是,CSO方法仅需要在16%的轨迹步骤上进行监督,就能够取得如此显著的性能提升,证明了其高效性。
🎯 应用场景
CSO方法可以应用于各种需要复杂决策和长程规划的LLM Agent任务,例如机器人控制、游戏AI、自动驾驶、智能客服等。通过精确地优化关键决策步骤,可以显著提升Agent在这些任务中的表现,使其能够更有效地解决实际问题。该方法降低了对大量人工标注数据的依赖,具有很高的应用价值。
📄 摘要(原文)
As large language model agents tackle increasingly complex long-horizon tasks, effective post-training becomes critical. Prior work faces fundamental challenges: outcome-only rewards fail to precisely attribute credit to intermediate steps, estimated step-level rewards introduce systematic noise, and Monte Carlo sampling approaches for step reward estimation incur prohibitive computational cost. Inspired by findings that only a small fraction of high-entropy tokens drive effective RL for reasoning, we propose Critical Step Optimization (CSO), which focuses preference learning on verified critical steps, decision points where alternate actions demonstrably flip task outcomes from failure to success. Crucially, our method starts from failed policy trajectories rather than expert demonstrations, directly targeting the policy model's weaknesses. We use a process reward model (PRM) to identify candidate critical steps, leverage expert models to propose high-quality alternatives, then continue execution from these alternatives using the policy model itself until task completion. Only alternatives that the policy successfully executes to correct outcomes are verified and used as DPO training data, ensuring both quality and policy reachability. This yields fine-grained, verifiable supervision at critical decisions while avoiding trajectory-level coarseness and step-level noise. Experiments on GAIA-Text-103 and XBench-DeepSearch show that CSO achieves 37% and 26% relative improvement over the SFT baseline and substantially outperforms other post-training methods, while requiring supervision at only 16% of trajectory steps. This demonstrates the effectiveness of selective verification-based learning for agent post-training.