Towards Distillation-Resistant Large Language Models: An Information-Theoretic Perspective
作者: Hao Fang, Tianyi Zhang, Tianqu Zhuang, Jiawei Kong, Kuofeng Gao, Bin Chen, Leqi Liang, Shu-Tao Xia, Ke Xu
分类: cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出基于信息论的抗蒸馏大语言模型方法,防御Logit蒸馏攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识蒸馏 模型安全 信息论 条件互信息
📋 核心要点
- 现有防御方法主要关注文本蒸馏,忽略了更隐蔽、更有效的Logit蒸馏攻击。
- 论文提出基于条件互信息(CMI)最小化的防御策略,旨在移除输出中与蒸馏相关的信息。
- 实验证明,该方法在显著降低蒸馏性能的同时,保持了原始LLM的任务准确性。
📝 摘要(中文)
专有的大型语言模型(LLM)具有巨大的经济价值,通常仅以黑盒API的形式公开。然而,攻击者仍然可以利用它们的输出来提取知识,即知识蒸馏。现有的防御方法主要集中在基于文本的蒸馏上,而对重要的基于logits的蒸馏却鲜有研究。本文分析了这个问题,并从信息论的角度提出了一个有效的解决方案。我们使用教师logits和输入查询在给定真实标签下的条件互信息(CMI)来表征教师输出中与蒸馏相关的信息。这个量捕捉了有利于模型提取的上下文信息,从而促使我们通过最小化CMI来防御蒸馏。在理论分析的指导下,我们提出学习一个转换矩阵来净化原始输出,以增强抗蒸馏能力。我们进一步推导出一个受CMI启发的反蒸馏目标来优化这种转换,有效地移除与蒸馏相关的信息,同时保持输出的效用。在多个LLM和强大的蒸馏算法上进行的大量实验表明,该方法显著降低了蒸馏性能,同时保持了任务准确性,从而有效地保护了模型的知识产权。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)容易受到知识蒸馏攻击,攻击者可以通过分析LLM的输出来提取模型知识,威胁模型的知识产权。现有的防御方法主要集中在文本蒸馏上,忽略了基于logits的蒸馏,而后者通常更有效,也更难防御。因此,如何有效地防御基于logits的蒸馏攻击是一个重要的研究问题。
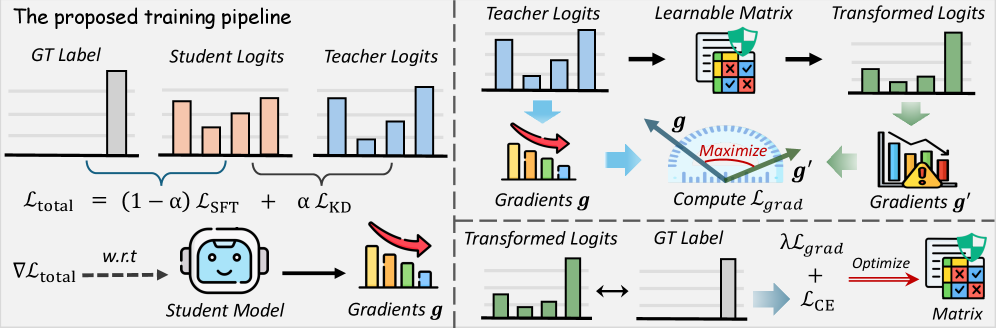
核心思路:论文的核心思路是,通过最小化教师模型输出logits中与蒸馏相关的信息来防御蒸馏攻击。具体来说,论文使用条件互信息(CMI)来量化logits中包含的、有利于学生模型学习的信息。通过学习一个转换矩阵,对教师模型的输出logits进行净化,移除其中与蒸馏相关的信息,从而降低学生模型的学习效果。
技术框架:该方法主要包含两个阶段:1) CMI分析阶段:使用条件互信息(CMI)来量化教师模型输出logits中包含的、有利于学生模型学习的信息。CMI越大,表示logits中包含的与蒸馏相关的信息越多。2) 抗蒸馏优化阶段:学习一个转换矩阵,对教师模型的输出logits进行净化,移除其中与蒸馏相关的信息,同时保持输出的效用。该阶段的目标是最小化CMI,同时最大化输出的效用。
关键创新:该论文的关键创新在于:1) 从信息论的角度分析了蒸馏攻击,并提出了使用条件互信息(CMI)来量化logits中包含的与蒸馏相关的信息。2) 提出了一种基于CMI最小化的抗蒸馏方法,通过学习一个转换矩阵来净化logits,移除其中与蒸馏相关的信息。与现有方法相比,该方法能够更有效地防御基于logits的蒸馏攻击。
关键设计:论文的关键设计包括:1) CMI的计算方法:使用蒙特卡洛方法来估计CMI。2) 转换矩阵的学习方法:使用梯度下降法来优化转换矩阵,目标是最小化CMI,同时最大化输出的效用。3) 损失函数的设计:损失函数包含两部分:CMI损失和效用损失。CMI损失用于最小化CMI,效用损失用于保持输出的效用。效用损失可以使用交叉熵损失或KL散度损失。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个LLM上显著降低了蒸馏性能,同时保持了任务准确性。例如,在某些实验中,蒸馏模型的准确率下降了超过20%,而原始LLM的准确率仅下降了不到1%。这表明该方法能够有效地防御蒸馏攻击,同时保持模型的可用性。
🎯 应用场景
该研究成果可应用于保护商业LLM的知识产权,防止竞争对手通过蒸馏技术窃取模型能力。通过部署该防御机制,LLM提供商可以更安全地开放API接口,同时降低模型被恶意提取的风险,从而促进LLM技术的更广泛应用。
📄 摘要(原文)
Proprietary large language models (LLMs) embody substantial economic value and are generally exposed only as black-box APIs, yet adversaries can still exploit their outputs to extract knowledge via distillation. Existing defenses focus exclusively on text-based distillation, leaving the important logit-based distillation largely unexplored. In this work, we analyze this problem and present an effective solution from an information-theoretic perspective. We characterize distillation-relevant information in teacher outputs using the conditional mutual information (CMI) between teacher logits and input queries conditioned on ground-truth labels. This quantity captures contextual information beneficial for model extraction, motivating us to defend distillation via CMI minimization. Guided by our theoretical analysis, we propose learning a transformation matrix that purifies the original outputs to enhance distillation resistance. We further derive a CMI-inspired anti-distillation objective to optimize this transformation, which effectively removes distillation-relevant information while preserving output utility. Extensive experiments across multiple LLMs and strong distillation algorithms demonstrate that the proposed method significantly degrades distillation performance while preserving task accuracy, effectively protecting models' intellectual property.