POP: Prefill-Only Pruning for Efficient Large Model Inference
作者: Junhui He, Zhihui Fu, Jun Wang, Qingan Li
分类: cs.CL, cs.AI, cs.CV
发布日期: 2026-02-03
💡 一句话要点
提出POP:一种预填充阶段剪枝方法,提升大模型推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 推理加速 阶段感知 预填充阶段
📋 核心要点
- 现有结构化剪枝方法在加速大模型推理时,忽略了预填充和解码阶段的不同需求,导致精度显著下降。
- POP方法通过分析各层在预填充和解码阶段的重要性差异,在预填充阶段安全地剪枝深层,从而加速推理。
- 实验表明,POP方法在多种模型和模态上实现了预填充延迟的显著加速,同时保持了较高的模型精度。
📝 摘要(中文)
大型语言模型(LLMs)和视觉语言模型(VLMs)展现了卓越的能力。然而,它们的部署受到巨大计算成本的阻碍。现有的结构化剪枝方法虽然在硬件上高效,但通常会遭受显著的精度下降。本文认为,这种失败源于一种阶段无关的剪枝方法,忽略了预填充(prefill)和解码(decode)阶段之间的不对称作用。通过引入虚拟门机制,我们的重要性分析表明,深层对于下一个token预测(解码)至关重要,但对于上下文编码(预填充)在很大程度上是冗余的。基于这一洞察,我们提出了预填充阶段剪枝(POP),一种阶段感知的推理策略,在计算密集型的预填充阶段安全地省略深层,同时为敏感的解码阶段保留完整的模型。为了实现阶段之间的过渡,我们引入了独立的键值(KV)投影来维持缓存完整性,以及边界处理策略来确保第一个生成token的准确性。在Llama-3.1、Qwen3-VL和Gemma-3等多种模态上的大量实验表明,POP在预填充延迟方面实现了高达1.37倍的加速,且性能损失极小,有效地克服了现有结构化剪枝方法的精度-效率权衡限制。
🔬 方法详解
问题定义:现有的大型语言模型和视觉语言模型推理成本高昂,结构化剪枝方法虽然可以加速推理,但通常会造成明显的精度损失。现有的剪枝方法没有区分预填充阶段和解码阶段的不同需求,对所有阶段采用相同的剪枝策略,导致了次优的结果。
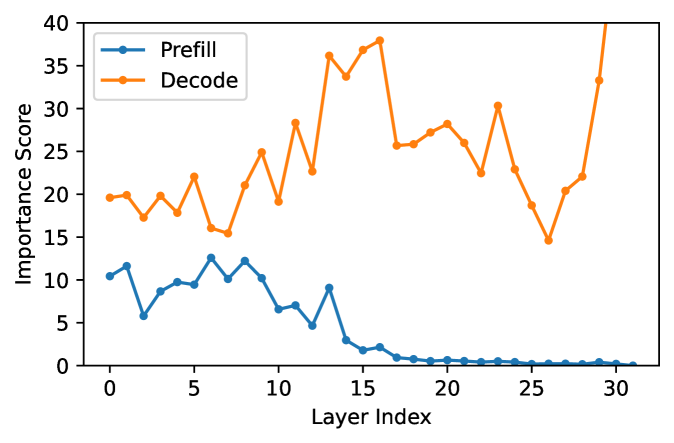
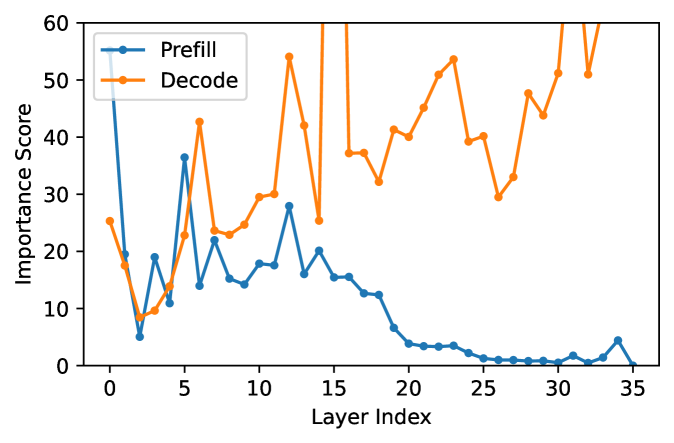
核心思路:论文的核心思路是观察到模型深层在预填充阶段和解码阶段的作用不同。深层对于解码阶段的下一个token预测至关重要,但在预填充阶段对上下文编码的贡献相对较小。因此,可以在预填充阶段安全地剪枝深层,从而降低计算成本,同时保持解码阶段的精度。
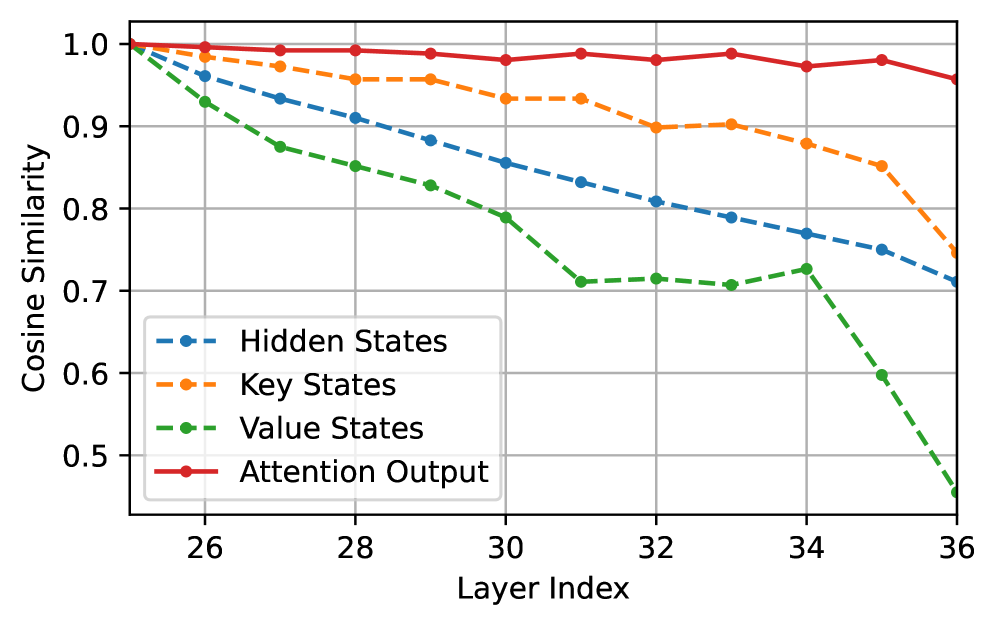
技术框架:POP方法包含以下几个主要组成部分:1) 虚拟门机制:用于分析模型各层在预填充和解码阶段的重要性。2) 阶段感知的剪枝策略:在预填充阶段剪枝深层,在解码阶段保留完整模型。3) 独立的键值(KV)投影:用于维持预填充阶段和解码阶段之间KV缓存的完整性。4) 边界处理策略:用于确保第一个生成token的准确性。整体流程是,输入序列首先经过剪枝后的模型进行预填充,然后切换到完整模型进行解码,最终生成输出序列。
关键创新:POP方法的关键创新在于其阶段感知的剪枝策略。与现有的阶段无关的剪枝方法不同,POP方法根据模型各层在不同阶段的重要性差异,采用不同的剪枝策略,从而在加速推理的同时保持了较高的模型精度。此外,独立的KV投影和边界处理策略也保证了阶段切换的平滑性和输出的准确性。
关键设计:虚拟门机制通过引入可学习的门控参数来衡量每一层的重要性。独立的KV投影使用额外的线性层来将预填充阶段的KV缓存映射到解码阶段的KV缓存。边界处理策略通过对第一个token的预测进行特殊处理,以减少剪枝带来的误差。具体的参数设置和损失函数细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
在Llama-3.1、Qwen3-VL和Gemma-3等模型上进行的实验表明,POP方法在预填充延迟方面实现了高达1.37倍的加速,同时性能损失极小。与现有的结构化剪枝方法相比,POP方法在相同的加速比下,能够保持更高的模型精度,有效地克服了精度-效率权衡的限制。
🎯 应用场景
POP方法可以应用于各种需要高效大模型推理的场景,例如移动设备上的本地部署、边缘计算环境下的实时推理、以及对延迟敏感的在线服务。通过降低计算成本,POP方法可以使大模型更容易部署和使用,从而推动人工智能技术的普及。
📄 摘要(原文)
Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated remarkable capabilities. However, their deployment is hindered by significant computational costs. Existing structured pruning methods, while hardware-efficient, often suffer from significant accuracy degradation. In this paper, we argue that this failure stems from a stage-agnostic pruning approach that overlooks the asymmetric roles between the prefill and decode stages. By introducing a virtual gate mechanism, our importance analysis reveals that deep layers are critical for next-token prediction (decode) but largely redundant for context encoding (prefill). Leveraging this insight, we propose Prefill-Only Pruning (POP), a stage-aware inference strategy that safely omits deep layers during the computationally intensive prefill stage while retaining the full model for the sensitive decode stage. To enable the transition between stages, we introduce independent Key-Value (KV) projections to maintain cache integrity, and a boundary handling strategy to ensure the accuracy of the first generated token. Extensive experiments on Llama-3.1, Qwen3-VL, and Gemma-3 across diverse modalities demonstrate that POP achieves up to 1.37$\times$ speedup in prefill latency with minimal performance loss, effectively overcoming the accuracy-efficiency trade-off limitations of existing structured pruning methods.