ATACompressor: Adaptive Task-Aware Compression for Efficient Long-Context Processing in LLMs
作者: Xuancheng Li, Haitao Li, Yujia Zhou, Qingyao Ai, Yiqun Liu
分类: cs.CL, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出ATACompressor,通过自适应任务感知压缩提升LLM长文本处理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 上下文压缩 自适应压缩 任务感知 大型语言模型
📋 核心要点
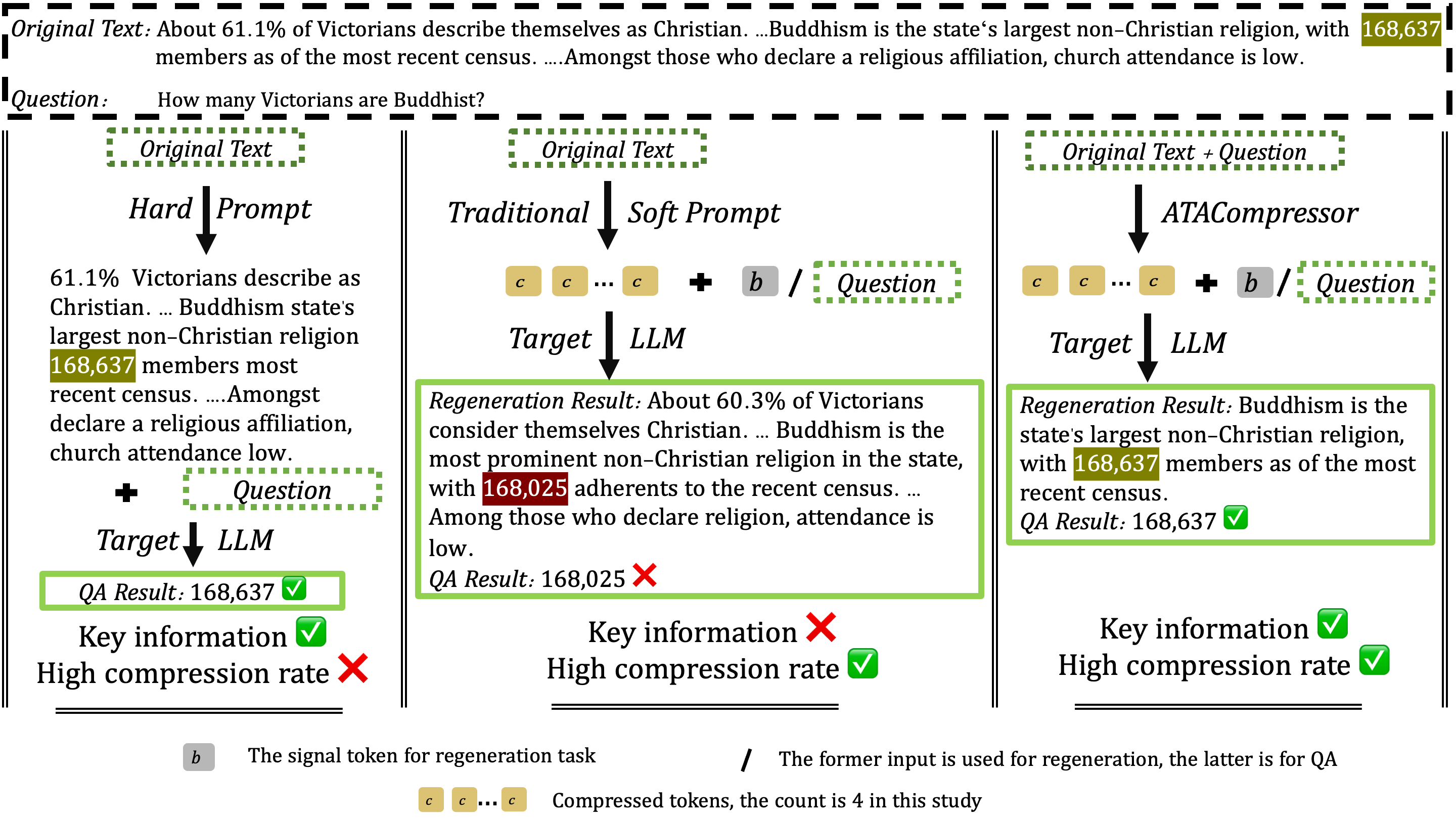
- 现有长文本处理方法在压缩时难以兼顾信息保留和压缩效率,导致关键信息丢失或资源浪费。
- ATACompressor的核心思想是根据任务需求自适应地压缩长文本,只保留与任务相关的关键信息。
- 实验表明,ATACompressor在QA任务上优于现有方法,实现了更高的压缩效率和任务性能。
📝 摘要(中文)
大型语言模型(LLM)中的长文本输入常常受到“中间迷失”问题的影响,关键信息因长度过长而被稀释或忽略。上下文压缩方法旨在通过减少输入大小来解决这个问题,但现有方法难以平衡信息保存和压缩效率。我们提出了自适应任务感知压缩器(ATACompressor),它根据任务的特定需求动态调整压缩。ATACompressor采用选择性编码器,仅压缩长文本中与任务相关的部分,确保关键信息得到保留,同时减少不必要的内容。其自适应分配控制器感知相关内容的长度,并相应地调整压缩率,从而优化资源利用率。我们在三个QA数据集HotpotQA、MSMARCO和SQUAD上评估了ATACompressor,结果表明它在压缩效率和任务性能方面均优于现有方法。我们的方法为LLM中的长文本处理提供了一个可扩展的解决方案。此外,我们进行了一系列消融研究和分析实验,以更深入地了解ATACompressor的关键组成部分。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,由于上下文长度的限制,容易出现“中间迷失”现象,即模型难以关注到文本中间的关键信息。现有的上下文压缩方法虽然可以减少输入长度,但往往无法区分重要信息和冗余信息,导致关键信息丢失,影响模型性能。此外,固定压缩率的策略也无法适应不同任务和不同长度的输入,造成资源浪费或信息损失。
核心思路:ATACompressor的核心思路是根据任务的特定需求,自适应地压缩长文本。它通过选择性编码器提取与任务相关的关键信息,并利用自适应分配控制器动态调整压缩率,从而在保证信息完整性的同时,提高压缩效率。这种任务感知的压缩方式能够有效地缓解“中间迷失”问题,提升模型在长文本上的性能。
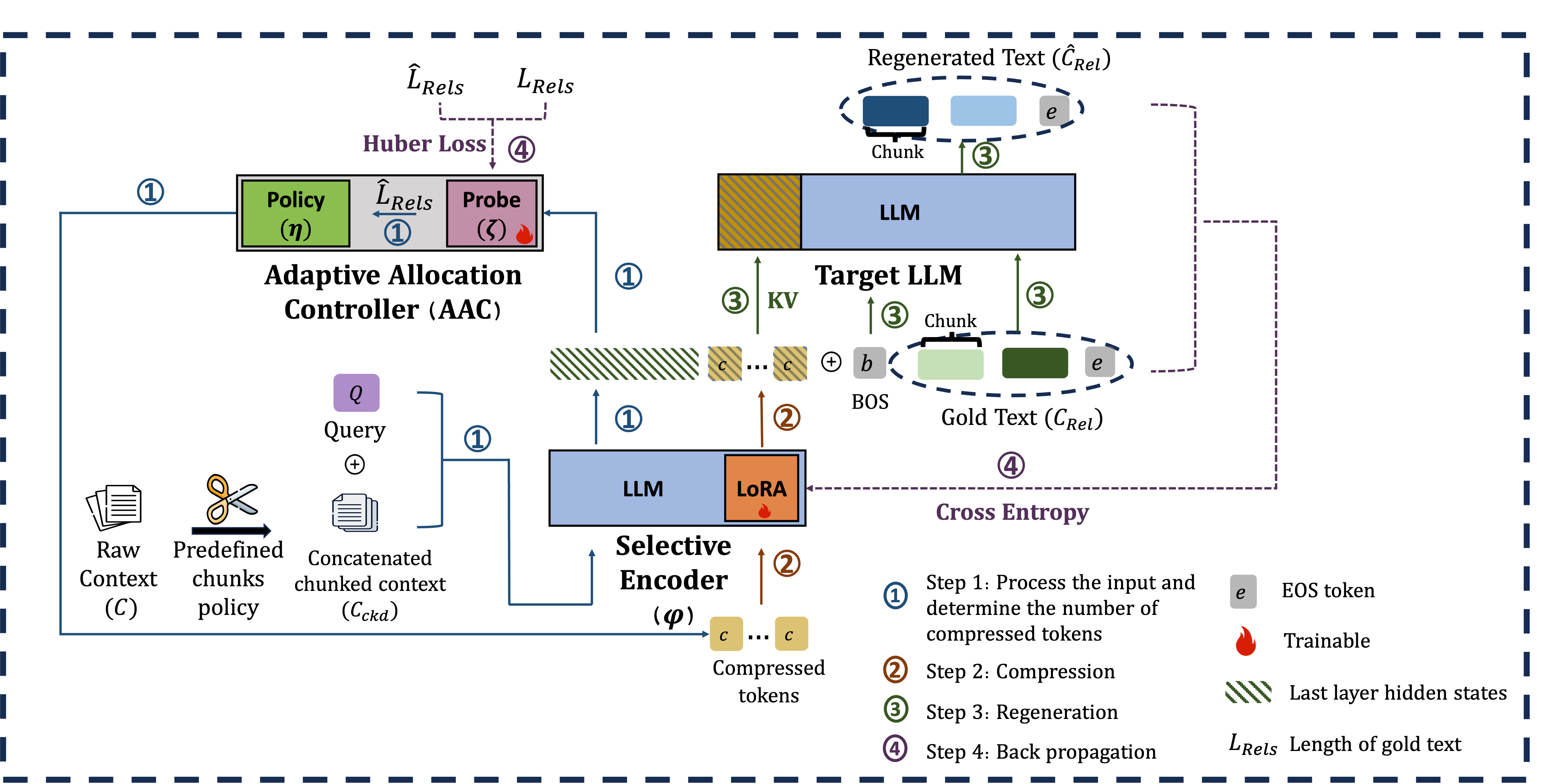
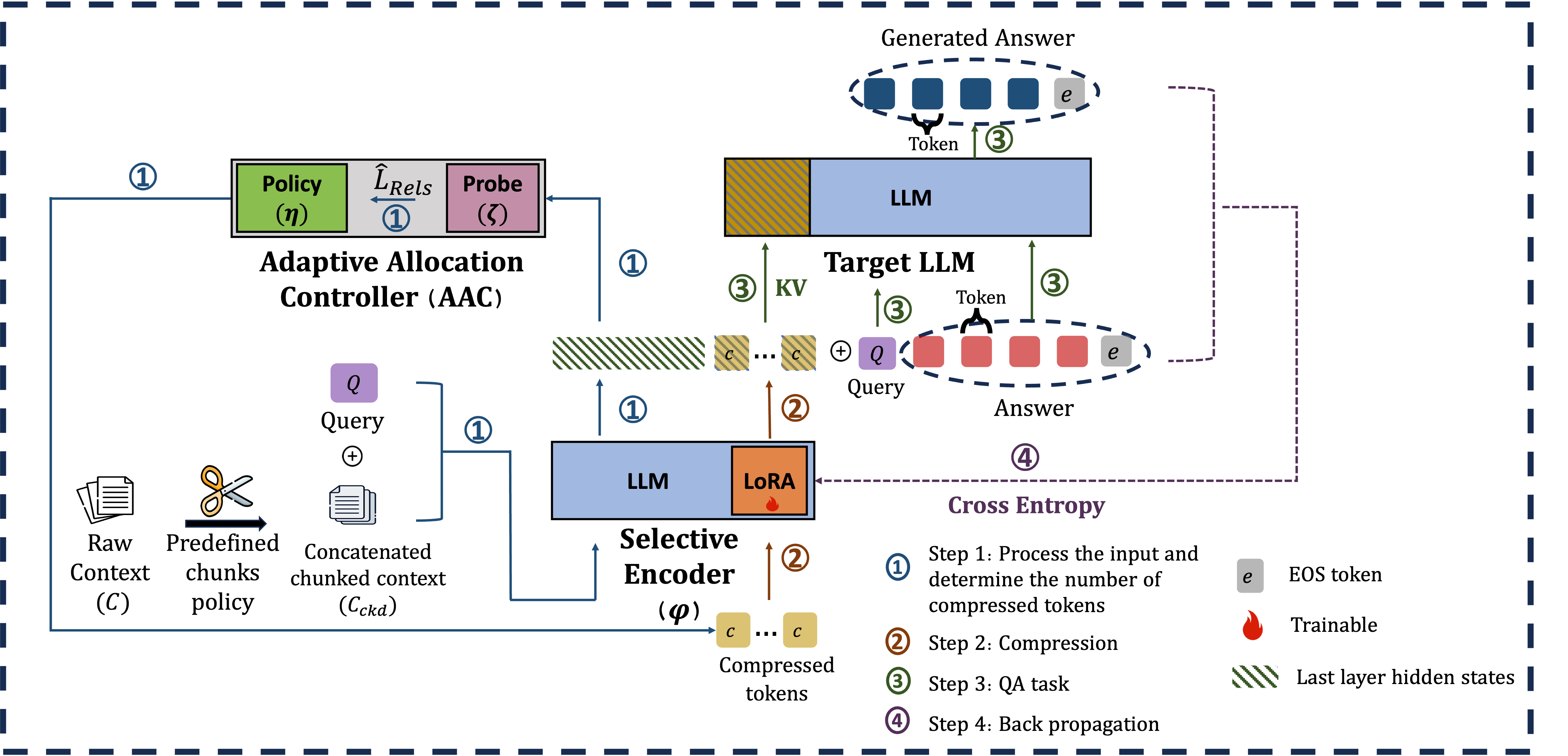
技术框架:ATACompressor主要包含两个模块:选择性编码器和自适应分配控制器。选择性编码器负责从长文本中提取与任务相关的关键信息,并将其压缩成低维表示。自适应分配控制器则根据提取的关键信息的长度,动态调整压缩率,以优化资源利用。整个流程可以概括为:输入长文本 -> 选择性编码器提取关键信息 -> 自适应分配控制器调整压缩率 -> 输出压缩后的文本表示。
关键创新:ATACompressor的关键创新在于其任务感知的自适应压缩策略。与传统的固定压缩率方法不同,ATACompressor能够根据任务需求动态调整压缩率,从而更好地平衡信息保留和压缩效率。选择性编码器的设计使得模型能够专注于与任务相关的关键信息,避免了冗余信息的干扰。自适应分配控制器的设计则使得模型能够根据输入文本的长度和复杂度,灵活地调整压缩率,从而优化资源利用。
关键设计:选择性编码器可以使用Transformer或其他序列模型实现,其关键在于设计一个有效的注意力机制,使得模型能够关注到与任务相关的关键信息。自适应分配控制器可以使用强化学习或其他优化算法实现,其目标是根据提取的关键信息的长度,动态调整压缩率,以最大化任务性能。损失函数可以包括任务相关的损失函数(如交叉熵损失)和压缩相关的损失函数(如KL散度损失),以平衡任务性能和压缩效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ATACompressor在HotpotQA、MSMARCO和SQUAD三个QA数据集上均优于现有方法。具体来说,ATACompressor在保持或提高任务性能的同时,能够显著减少输入长度,从而提高压缩效率。例如,在HotpotQA数据集上,ATACompressor在压缩率达到一定程度时,仍然能够保持与原始模型相当的性能,甚至略有提升。
🎯 应用场景
ATACompressor可广泛应用于需要处理长文本的自然语言处理任务,如问答系统、文档摘要、信息检索等。通过减少输入长度,可以降低计算成本,提高处理速度,并提升模型在长文本上的性能。该研究对于推动大型语言模型在实际应用中的部署具有重要意义,尤其是在资源受限的环境下。
📄 摘要(原文)
Long-context inputs in large language models (LLMs) often suffer from the "lost in the middle" problem, where critical information becomes diluted or ignored due to excessive length. Context compression methods aim to address this by reducing input size, but existing approaches struggle with balancing information preservation and compression efficiency. We propose Adaptive Task-Aware Compressor (ATACompressor), which dynamically adjusts compression based on the specific requirements of the task. ATACompressor employs a selective encoder that compresses only the task-relevant portions of long contexts, ensuring that essential information is preserved while reducing unnecessary content. Its adaptive allocation controller perceives the length of relevant content and adjusts the compression rate accordingly, optimizing resource utilization. We evaluate ATACompressor on three QA datasets: HotpotQA, MSMARCO, and SQUAD-showing that it outperforms existing methods in terms of both compression efficiency and task performance. Our approach provides a scalable solution for long-context processing in LLMs. Furthermore, we perform a range of ablation studies and analysis experiments to gain deeper insights into the key components of ATACompressor.