Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection
作者: Dongwon Jo, Beomseok Kang, Jiwon Song, Jae-Joon Kim
分类: cs.CL, cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出Token Sparse Attention,通过交错Token选择加速长文本推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 稀疏注意力 Token选择 动态稀疏化 大型语言模型
📋 核心要点
- 现有长文本处理方法在稀疏化注意力时,缺乏对token重要性的动态调整,导致信息损失或计算冗余。
- Token Sparse Attention通过动态选择重要token进行注意力计算,并在层间传递信息,实现高效的token级稀疏化。
- 实验表明,该方法在长文本推理中显著提升了速度,同时保持了较高的精度,实现了更好的精度-延迟平衡。
📝 摘要(中文)
大型语言模型在长文本推理中面临注意力机制的二次复杂度瓶颈。现有加速方法要么使用结构化模式稀疏化注意力图,要么在特定层永久剔除token,这可能保留不相关的token或依赖于不可逆转的早期决策,而忽略了token重要性的层/头动态变化。本文提出了Token Sparse Attention,一种轻量级的动态token级稀疏化机制,在注意力计算期间将每个头的Q、K、V压缩到缩减的token集合,然后将输出解压缩回原始序列,使token信息可以在后续层中重新考虑。此外,Token Sparse Attention揭示了token选择和稀疏注意力交叉领域的一个新的设计点。我们的方法完全兼容密集注意力实现(包括Flash Attention),并且可以与现有的稀疏注意力内核无缝组合。实验结果表明,Token Sparse Attention始终提高精度-延迟权衡,在128K上下文长度下实现了高达3.23倍的注意力加速,而精度下降小于1%。这些结果表明,动态和交错的token级稀疏化是可扩展长文本推理的一种互补且有效的策略。
🔬 方法详解
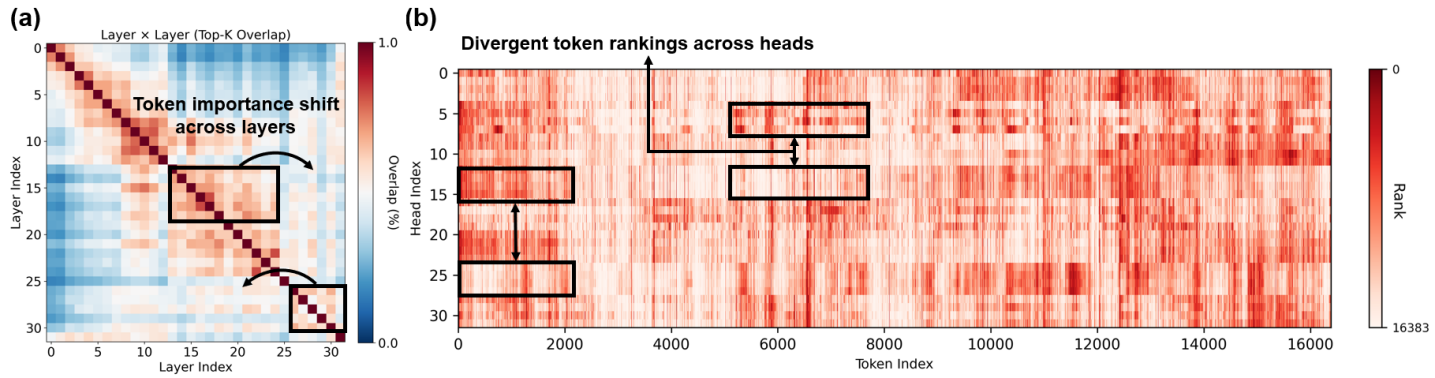
问题定义:长文本推理中,标准Attention机制的计算复杂度随序列长度呈平方增长,成为性能瓶颈。现有稀疏Attention方法,如固定模式稀疏化或永久剔除token,无法适应token重要性在不同层和注意力头之间的动态变化,导致信息损失或计算效率低下。
核心思路:Token Sparse Attention的核心在于动态地选择每个注意力头认为重要的token子集进行计算,并在层与层之间传递完整的token信息。通过在每一层重新评估token的重要性,避免了早期决策带来的不可逆转的信息损失,从而更好地适应token重要性的动态变化。
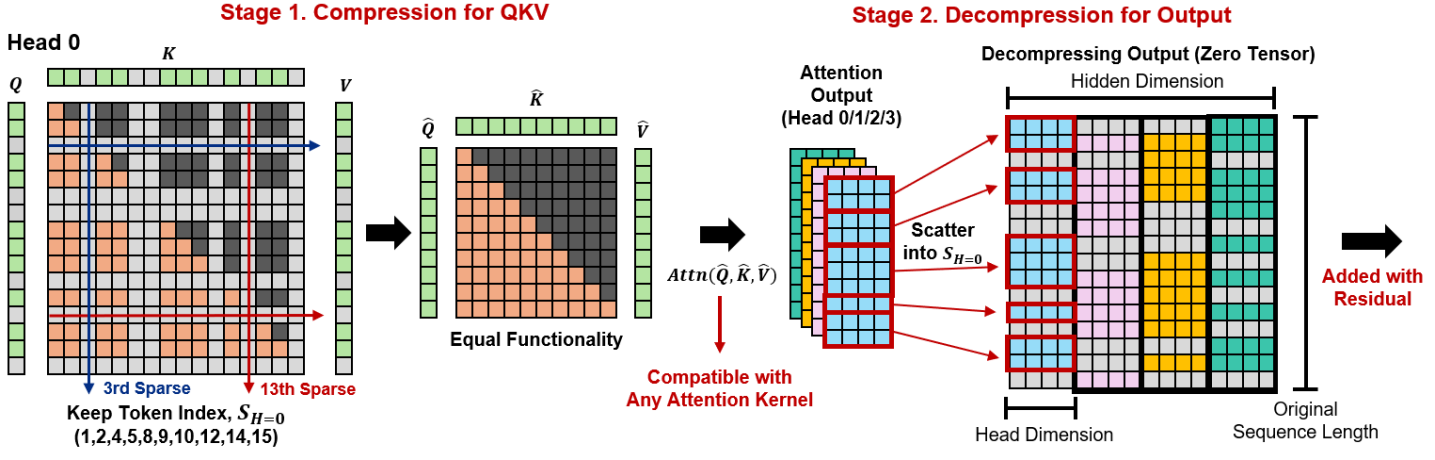
技术框架:Token Sparse Attention在标准的Transformer架构中插入token选择和解压缩模块。对于每一层,首先使用token选择模块从输入token序列中选择一个缩减的token子集。然后,使用这个子集计算Attention。最后,使用解压缩模块将Attention的输出映射回原始的token序列长度,以便下一层可以访问完整的token信息。整个过程与Flash Attention等优化方法兼容。
关键创新:Token Sparse Attention的关键创新在于其动态token选择机制和交错式的token信息传递。与静态稀疏化方法不同,它允许每一层根据自身的需求选择token,并确保所有token的信息都能传递到后续层,从而更好地捕捉长距离依赖关系。
关键设计:Token选择模块可以使用不同的策略实现,例如基于token的Query和Key向量的点积选择top-k个token。解压缩模块可以使用简单的线性映射或更复杂的神经网络。论文中没有明确指定损失函数,因为该方法主要关注推理加速,可以与现有的训练方法结合使用。关键参数是每层选择的token数量,需要在精度和效率之间进行权衡。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Token Sparse Attention在128K上下文长度下实现了高达3.23倍的注意力加速,而精度下降小于1%。该方法与Flash Attention等现有优化方法兼容,并且可以与现有的稀疏注意力内核无缝组合。在多个长文本任务上,Token Sparse Attention都取得了优于现有方法的精度-延迟权衡。
🎯 应用场景
Token Sparse Attention适用于需要处理长文本序列的各种应用场景,例如长文档摘要、问答系统、机器翻译、代码生成等。通过降低长文本推理的计算成本,该方法可以使大型语言模型在资源受限的环境中部署,并支持处理更长的上下文,从而提高模型的性能和实用性。未来,该方法可以进一步扩展到处理更复杂的序列数据,例如视频和音频。
📄 摘要(原文)
The quadratic complexity of attention remains the central bottleneck in long-context inference for large language models. Prior acceleration methods either sparsify the attention map with structured patterns or permanently evict tokens at specific layers, which can retain irrelevant tokens or rely on irreversible early decisions despite the layer-/head-wise dynamics of token importance. In this paper, we propose Token Sparse Attention, a lightweight and dynamic token-level sparsification mechanism that compresses per-head $Q$, $K$, $V$ to a reduced token set during attention and then decompresses the output back to the original sequence, enabling token information to be reconsidered in subsequent layers. Furthermore, Token Sparse Attention exposes a new design point at the intersection of token selection and sparse attention. Our approach is fully compatible with dense attention implementations, including Flash Attention, and can be seamlessly composed with existing sparse attention kernels. Experimental results show that Token Sparse Attention consistently improves accuracy-latency trade-off, achieving up to $\times$3.23 attention speedup at 128K context with less than 1% accuracy degradation. These results demonstrate that dynamic and interleaved token-level sparsification is a complementary and effective strategy for scalable long-context inference.