FASA: Frequency-aware Sparse Attention
作者: Yifei Wang, Yueqi Wang, Zhenrui Yue, Huimin Zeng, Yong Wang, Ismini Lourentzou, Zhengzhong Tu, Xiangxiang Chu, Julian McAuley
分类: cs.CL
发布日期: 2026-02-03
备注: Accepted by ICLR 2026
💡 一句话要点
FASA:提出频率感知稀疏注意力机制,解决长文本LLM的KV缓存瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 稀疏注意力 token剪枝 KV缓存 RoPE 频率感知 大型语言模型
📋 核心要点
- 现有token剪枝方法在处理长文本时,要么静态剪枝导致信息丢失,要么动态剪枝无法充分捕捉查询相关的token重要性。
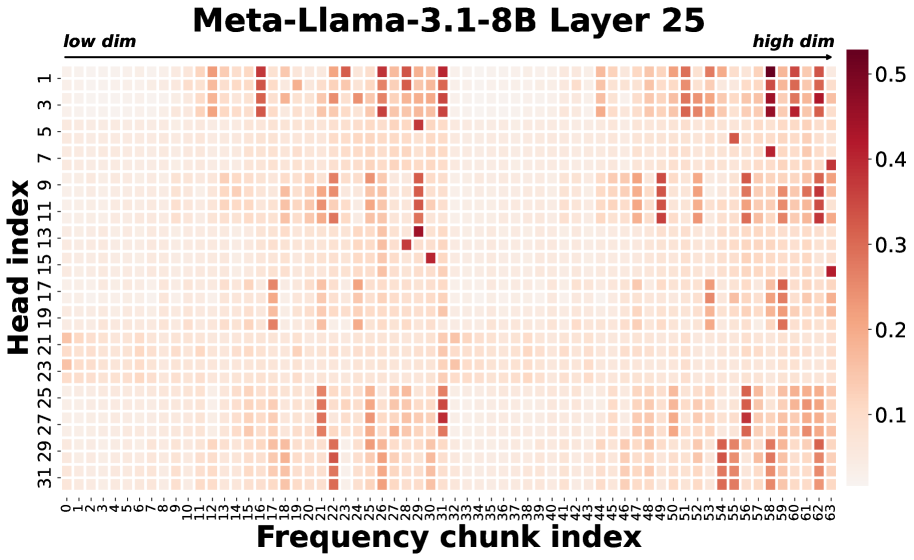
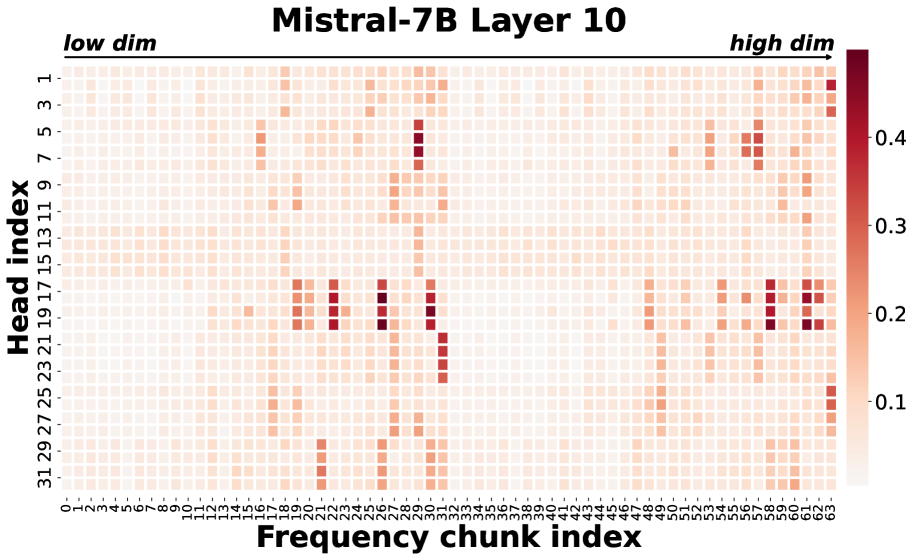
- FASA通过分析RoPE,发现频率块级别的功能稀疏性,利用“主导”频率块与完整注意力头的高度一致性来预测token重要性。
- 实验表明,FASA在长文本任务中优于现有token驱逐方法,在LongBench-V1上仅保留256个token时接近完整KV性能。
📝 摘要(中文)
大型语言模型(LLM)在处理长输入时面临一个关键瓶颈:Key Value(KV)缓存的巨大内存占用。为了解决这个瓶颈,token剪枝范式利用注意力稀疏性来选择性地保留一小部分关键token。然而,现有的方法存在不足,静态方法可能导致不可逆的信息丢失,而动态策略采用的启发式方法不足以捕捉token重要性的查询依赖性。我们提出了FASA,一种通过动态预测token重要性来实现查询感知token驱逐的新框架。FASA源于对RoPE的一种新颖见解:在频率块(FC)级别发现的功能稀疏性。我们的关键发现是,一小部分可识别的“主导”FC始终与完整注意力头表现出高度的上下文一致性。这为识别显著token提供了一个强大且计算免费的代理。基于此,FASA首先使用主导FC识别一组关键token,然后仅对这个剪枝后的子集执行集中的注意力计算。由于仅访问KV缓存的一小部分,FASA大大降低了内存带宽需求和计算成本。在一系列长上下文任务中,从序列建模到复杂的CoT推理,FASA始终优于所有token驱逐基线,并实现了接近oracle的准确性,即使在约束预算下也表现出卓越的鲁棒性。值得注意的是,在LongBench-V1上,当仅保留256个token时,FASA达到了接近100%的完整KV性能,并且在AIME24上仅使用18.9%的缓存即可实现2.56倍的加速。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本时,KV缓存的内存占用非常大,成为部署的瓶颈。现有的token剪枝方法,如静态剪枝和动态剪枝,都存在不足。静态剪枝可能会永久丢失重要信息,而动态剪枝则依赖于启发式方法,无法充分捕捉token重要性的查询依赖性。
核心思路:FASA的核心思路是利用RoPE中频率块级别的功能稀疏性来动态预测token的重要性。论文发现,一小部分“主导”频率块与完整的注意力头具有高度的上下文一致性,因此可以作为token重要性的有效代理。通过识别这些主导频率块,可以确定需要保留的关键token,从而减少KV缓存的内存占用。
技术框架:FASA的整体框架包括以下几个主要步骤: 1. 频率块分析:分析RoPE中的频率块,识别出“主导”频率块。 2. Token重要性预测:利用主导频率块与完整注意力头的一致性,预测每个token的重要性。 3. Token剪枝:根据token的重要性得分,选择性地保留一部分token,并丢弃其余token。 4. 注意力计算:仅对保留的token执行注意力计算,从而减少计算量和内存占用。
关键创新:FASA最关键的创新点在于发现了RoPE中频率块级别的功能稀疏性,并将其用于动态预测token的重要性。与现有方法相比,FASA能够更准确地捕捉token重要性的查询依赖性,从而实现更有效的token剪枝。此外,FASA利用主导频率块进行token重要性预测,计算成本较低。
关键设计:FASA的关键设计包括: 1. 主导频率块的识别方法:具体如何定义和识别“主导”频率块,可能涉及到阈值设定或其他选择策略。 2. Token重要性得分的计算方法:如何利用主导频率块与完整注意力头的一致性来计算token的重要性得分。 3. Token剪枝的策略:如何根据token的重要性得分来选择需要保留的token,例如设定一个阈值或者保留固定数量的token。
🖼️ 关键图片

📊 实验亮点
FASA在LongBench-V1上表现出色,仅保留256个token时,性能接近完整KV缓存。在AIME24任务上,FASA仅使用18.9%的缓存即可实现2.56倍的加速。这些结果表明,FASA能够有效地减少内存占用和计算成本,同时保持较高的性能。
🎯 应用场景
FASA可以应用于各种需要处理长文本的场景,例如长文档摘要、机器翻译、问答系统和代码生成等。通过减少KV缓存的内存占用,FASA可以使大型语言模型能够处理更长的输入序列,从而提高模型的性能和适用性。此外,FASA还可以降低模型的计算成本,使其更易于部署在资源受限的设备上。
📄 摘要(原文)
The deployment of Large Language Models (LLMs) faces a critical bottleneck when handling lengthy inputs: the prohibitive memory footprint of the Key Value (KV) cache. To address this bottleneck, the token pruning paradigm leverages attention sparsity to selectively retain a small, critical subset of tokens. However, existing approaches fall short, with static methods risking irreversible information loss and dynamic strategies employing heuristics that insufficiently capture the query-dependent nature of token importance. We propose FASA, a novel framework that achieves query-aware token eviction by dynamically predicting token importance. FASA stems from a novel insight into RoPE: the discovery of functional sparsity at the frequency-chunk (FC) level. Our key finding is that a small, identifiable subset of "dominant" FCs consistently exhibits high contextual agreement with the full attention head. This provides a robust and computationally free proxy for identifying salient tokens. %making them a powerful and efficient proxy for token importance. Building on this insight, FASA first identifies a critical set of tokens using dominant FCs, and then performs focused attention computation solely on this pruned subset. % Since accessing only a small fraction of the KV cache, FASA drastically lowers memory bandwidth requirements and computational cost. Across a spectrum of long-context tasks, from sequence modeling to complex CoT reasoning, FASA consistently outperforms all token-eviction baselines and achieves near-oracle accuracy, demonstrating remarkable robustness even under constraint budgets. Notably, on LongBench-V1, FASA reaches nearly 100\% of full-KV performance when only keeping 256 tokens, and achieves 2.56$\times$ speedup using just 18.9\% of the cache on AIME24.