One Model, All Roles: Multi-Turn, Multi-Agent Self-Play Reinforcement Learning for Conversational Social Intelligence
作者: Bowen Jiang, Taiwei Shi, Ryo Kamoi, Yuan Yuan, Camillo J. Taylor, Longqi Yang, Pei Zhou, Sihao Chen
分类: cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出OMAR:基于多智能体自博弈强化学习的通用对话社交智能模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 自博弈 社交智能 对话系统 Transformer
📋 核心要点
- 现有方法难以让AI在动态社交互动中学习长期目标和复杂的社会规范。
- OMAR框架让单个模型扮演对话中的所有角色,通过自博弈学习社交智能。
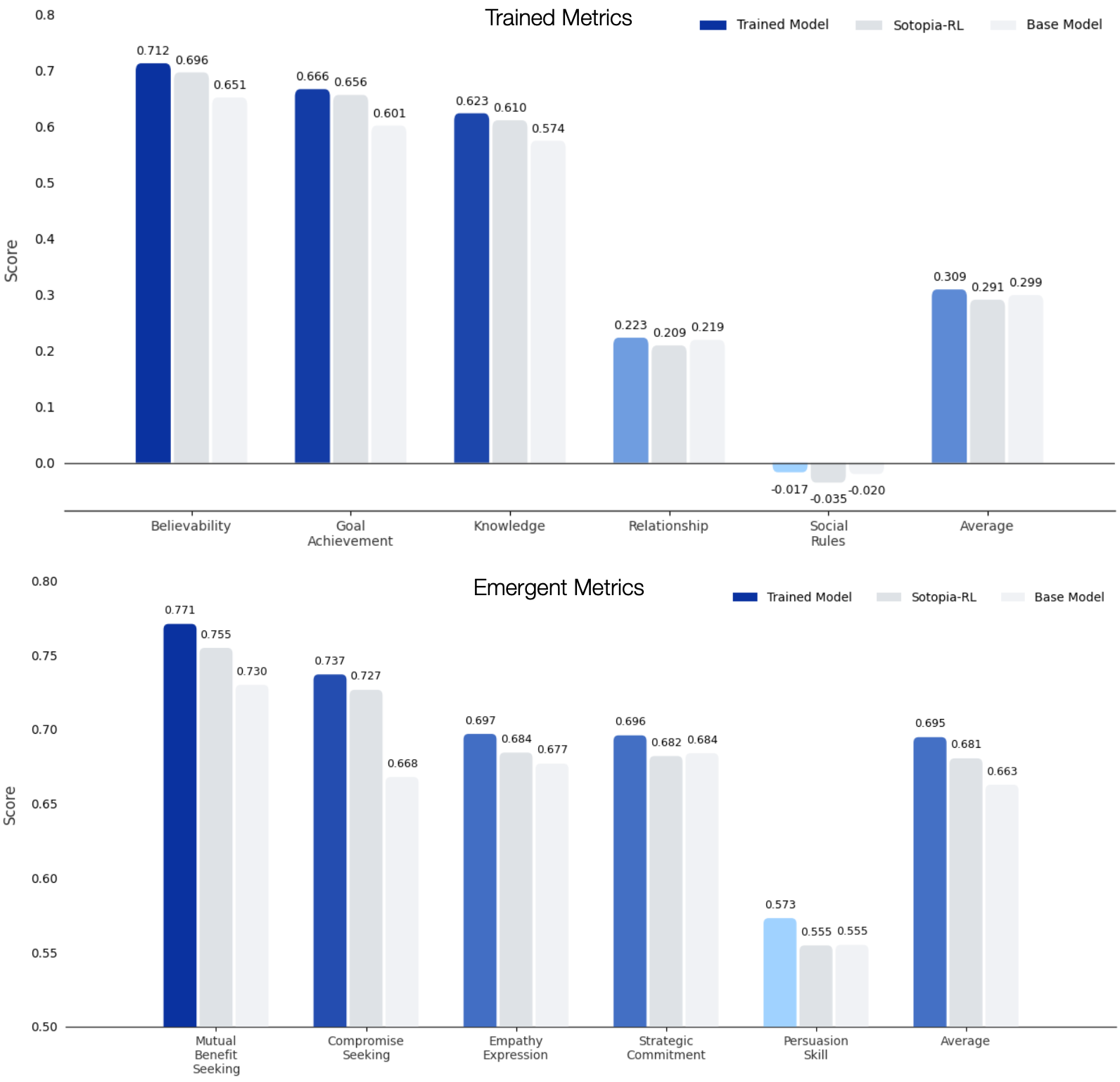
- 实验表明,OMAR模型展现出同理心、说服力和寻求妥协等涌现的社交智能。
📝 摘要(中文)
本文提出了一种名为OMAR(One Model, All Roles)的强化学习框架,旨在使AI通过多轮、多智能体对话自博弈来发展社交智能。与依赖于静态、单轮优化的传统范式不同,OMAR允许单个模型同时扮演对话中的所有参与者,直接从动态社交互动中学习实现长期目标和复杂的社会规范。为了确保长对话中的训练稳定性,我们实施了一种分层优势估计方法,计算turn级别和token级别的优势。在SOTOPIA社交环境和狼人杀策略游戏中的评估表明,我们训练的模型发展出了细粒度的、涌现的社交智能,例如同理心、说服力和寻求妥协,证明了即使在竞争场景下学习协作的有效性。虽然我们发现了诸如奖励黑客等实际挑战,但我们的结果表明,无需人工监督即可涌现丰富的社交智能。我们希望这项工作能够激励对群体对话中AI社交智能的进一步研究。
🔬 方法详解
问题定义:现有方法通常依赖于静态、单轮优化,无法使AI在动态社交互动中学习长期目标和复杂的社会规范。这些方法难以捕捉对话中复杂的依赖关系和策略,限制了AI在社交环境中的表现。论文旨在解决AI在多轮、多智能体对话中学习和应用社交智能的问题。
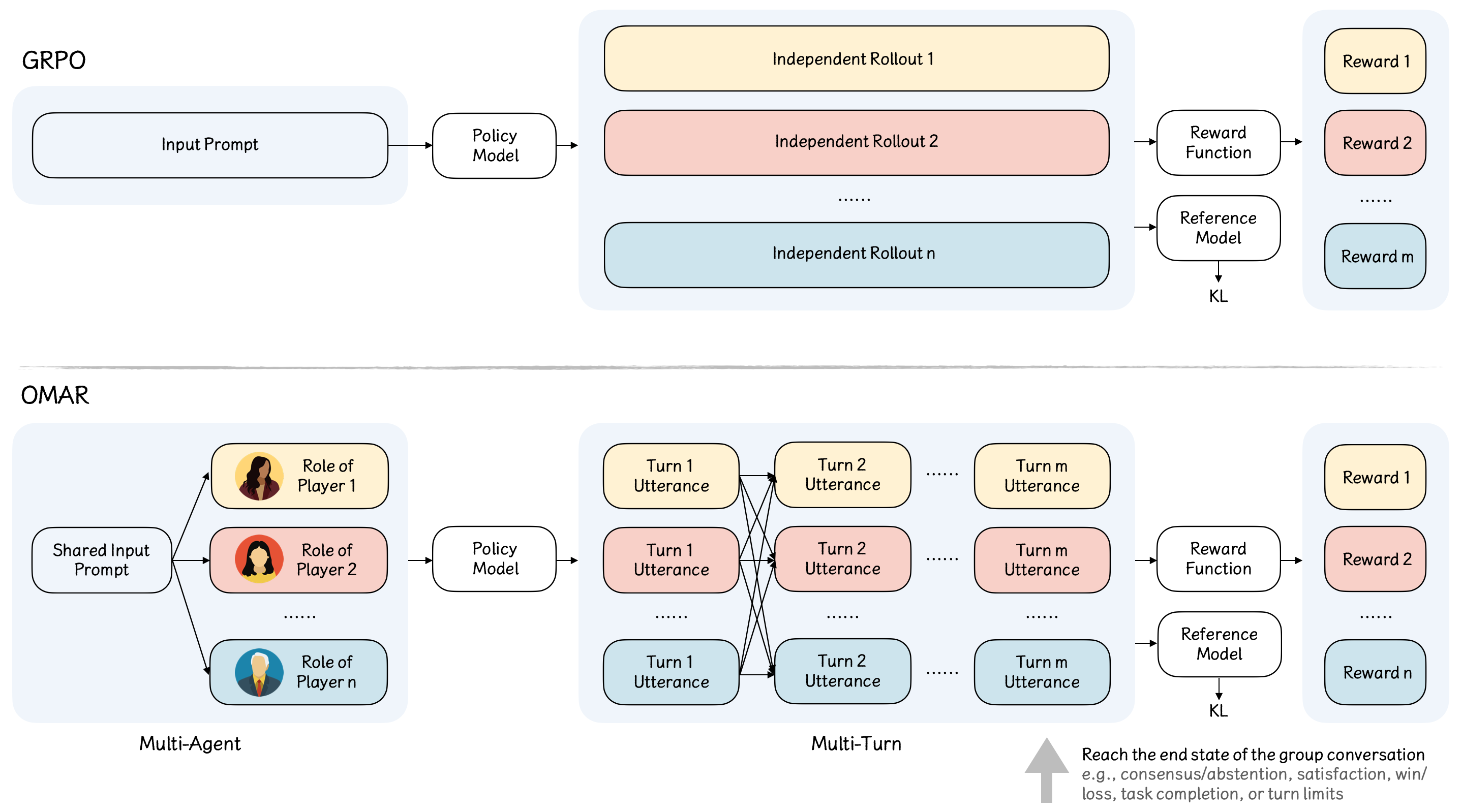
核心思路:论文的核心思路是让一个模型扮演对话中的所有角色,通过多智能体自博弈的方式进行强化学习。这种方法允许模型直接从动态的社交互动中学习,从而更好地理解对话的长期目标和社会规范。通过让模型扮演不同的角色,可以促进其对不同观点的理解和学习,从而发展出更强的社交智能。
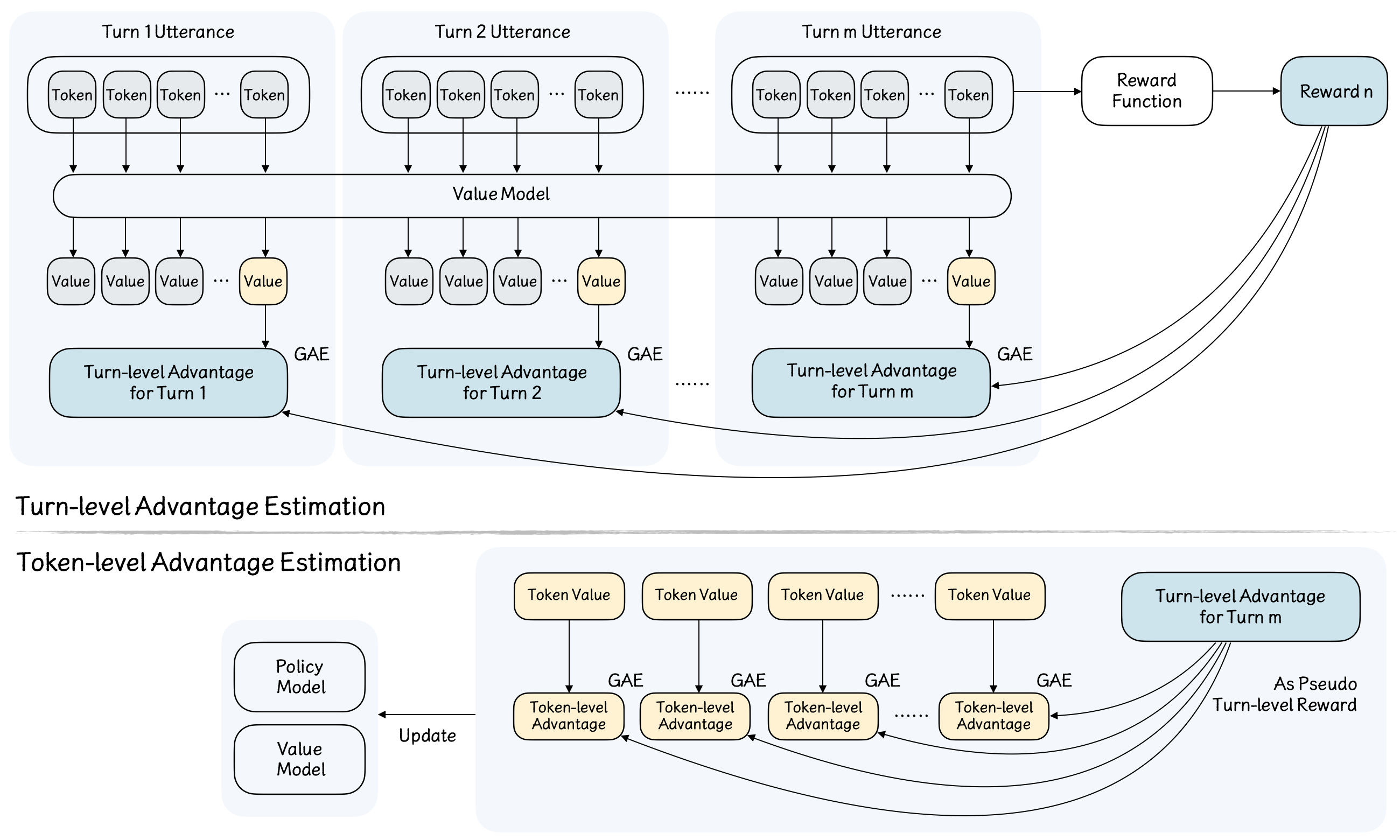
技术框架:OMAR框架的核心是一个对话模型,该模型可以扮演对话中的所有角色。训练过程采用多智能体强化学习,其中每个智能体代表一个对话参与者。整个训练流程包括以下几个步骤:1) 初始化对话环境;2) 模型根据当前状态选择动作(即生成对话);3) 环境根据动作更新状态;4) 计算奖励;5) 使用强化学习算法更新模型参数。为了保证训练的稳定性,论文采用了分层优势估计方法。
关键创新:最重要的技术创新点在于使用单个模型扮演所有角色,并通过多智能体自博弈进行强化学习。这种方法与传统的单智能体强化学习方法不同,它允许模型直接从动态的社交互动中学习,从而更好地理解对话的长期目标和社会规范。此外,分层优势估计方法也是一个关键创新,它可以有效地解决长对话中的信用分配问题。
关键设计:论文采用了Transformer作为对话模型的基础架构。奖励函数的设计至关重要,需要能够反映对话的长期目标和社会规范。为了解决长对话中的信用分配问题,论文采用了分层优势估计方法,分别计算turn级别和token级别的优势。具体来说,turn级别的优势用于评估整个turn的质量,而token级别的优势用于评估每个token的贡献。此外,论文还采用了多种训练技巧,例如经验回放和目标网络,以提高训练的稳定性和效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OMAR模型在SOTOPIA社交环境和狼人杀策略游戏中表现出色,展现出同理心、说服力和寻求妥协等涌现的社交智能。具体来说,OMAR模型在狼人杀游戏中能够更好地识别其他玩家的身份,并制定更有效的策略。此外,OMAR模型还能够根据其他玩家的情绪和反应调整自己的行为,从而提高对话的成功率。这些结果表明,OMAR框架能够有效地学习和应用社交智能。
🎯 应用场景
该研究成果可应用于多个领域,例如智能客服、社交机器人、在线教育和虚拟社交环境。通过学习社交智能,AI可以更好地理解人类的需求和情感,从而提供更个性化、更有效的服务。此外,该研究还可以促进人机协作,使AI能够更好地与人类合作完成任务。未来,该技术有望应用于更复杂的社交场景,例如谈判、调解和团队合作。
📄 摘要(原文)
This paper introduces OMAR: One Model, All Roles, a reinforcement learning framework that enables AI to develop social intelligence through multi-turn, multi-agent conversational self-play. Unlike traditional paradigms that rely on static, single-turn optimizations, OMAR allows a single model to role-play all participants in a conversation simultaneously, learning to achieve long-term goals and complex social norms directly from dynamic social interaction. To ensure training stability across long dialogues, we implement a hierarchical advantage estimation that calculates turn-level and token-level advantages. Evaluations in the SOTOPIA social environment and Werewolf strategy games show that our trained models develop fine-grained, emergent social intelligence, such as empathy, persuasion, and compromise seeking, demonstrating the effectiveness of learning collaboration even under competitive scenarios. While we identify practical challenges like reward hacking, our results show that rich social intelligence can emerge without human supervision. We hope this work incentivizes further research on AI social intelligence in group conversations.