ChemPro: A Progressive Chemistry Benchmark for Large Language Models
作者: Aaditya Baranwal, Shruti Vyas
分类: cs.CL
发布日期: 2026-02-03
💡 一句话要点
ChemPro:面向大语言模型的渐进式化学能力评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 化学基准 科学推理 自然语言处理 能力评估
📋 核心要点
- 现有LLM在科学推理和理解方面存在局限性,尤其是在化学等领域,难以处理复杂问题。
- ChemPro基准通过设计难度递增的化学问题,系统评估LLM在不同难度级别的表现。
- 实验结果表明,LLM在基础化学问题上表现较好,但在复杂问题上准确率显著下降,揭示了LLM的不足。
📝 摘要(中文)
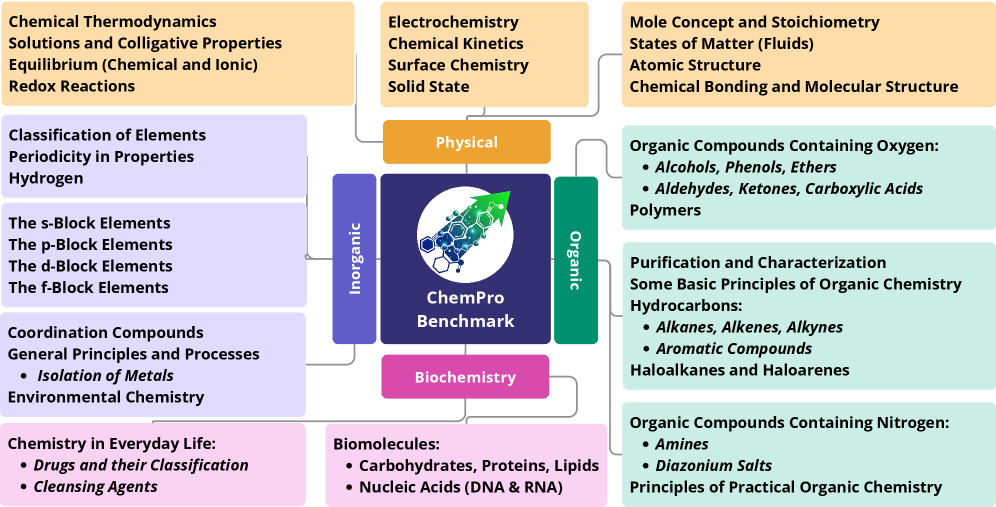
本文提出了ChemPro,一个包含4100个自然语言问答对的化学渐进式基准,它分为四个难度递增的部分,旨在评估大型语言模型(LLM)在广泛的通用化学主题中的能力。ChemPro包含多项选择题和数值题,涵盖了细粒度的信息回忆、长程推理、多概念问题、需要细致表达的问题解决以及直接问题,并以平衡的比例有效覆盖了生物化学、无机化学、有机化学和物理化学。ChemPro的设计类似于学生从基础到高中化学的学业评估。问题难度逐渐增加,严格测试了LLM从解决基本问题到解决更复杂挑战的能力。我们评估了45+7个最先进的LLM,包括开源和专有模型,分析表明,虽然LLM在基础化学问题上表现良好,但其准确性随着不同类型和复杂程度而下降。这些发现突出了LLM在一般科学推理和理解方面的关键局限性,并指出了难度方面未被充分研究的维度,强调需要更强大的方法来改进LLM。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在通用科学推理和理解方面存在局限性,尤其是在化学领域。现有的化学数据集可能无法充分评估LLM在不同难度级别上的表现,并且可能缺乏对长程推理、多概念问题和细致表达能力的要求。因此,需要一个更全面、更具挑战性的基准来评估LLM在化学领域的真实能力。
核心思路:ChemPro的核心思路是创建一个难度渐进的化学基准,模拟学生从基础到高中化学的学习过程。通过设计不同难度级别的问题,可以更准确地评估LLM在不同能力层次上的表现,并揭示其在复杂问题解决方面的不足。这种渐进式的方法能够更有效地诊断LLM的弱点,并为未来的改进提供指导。
技术框架:ChemPro基准包含4100个自然语言问答对,分为四个难度递增的部分。这些问题涵盖了生物化学、无机化学、有机化学和物理化学等多个领域,并包括多项选择题和数值题。问题的设计考虑了细粒度的信息回忆、长程推理、多概念问题、需要细致表达的问题解决以及直接问题等多个方面。通过评估LLM在不同类型和难度级别问题上的表现,可以全面了解其在化学领域的理解和推理能力。
关键创新:ChemPro的关键创新在于其渐进式的难度设计,这使得它能够更准确地评估LLM在不同能力层次上的表现。与现有的化学数据集相比,ChemPro更加注重对长程推理、多概念问题和细致表达能力的要求,从而更全面地反映了LLM在化学领域的真实能力。此外,ChemPro还包含了多种类型的问题,例如多项选择题和数值题,从而更全面地评估了LLM的不同能力。
关键设计:ChemPro的关键设计在于其难度分级和问题类型的选择。难度分级参考了学生从基础到高中化学的学习过程,确保问题难度逐渐增加。问题类型的选择则考虑了化学领域常见的知识点和技能,例如信息回忆、长程推理、多概念问题和问题解决等。此外,ChemPro还注重问题的自然语言表达,避免使用过于专业或晦涩的术语,从而更真实地反映了LLM在实际应用中的表现。
🖼️ 关键图片

📊 实验亮点
ChemPro基准评估了45+7个最先进的LLM,结果表明,LLM在基础化学问题上表现良好,但在复杂问题上准确率显著下降。例如,在需要长程推理和多概念整合的问题上,LLM的性能明显低于人类专家。这些结果揭示了LLM在科学推理和理解方面的局限性,并强调了开发更强大的LLM的必要性。
🎯 应用场景
ChemPro基准可用于评估和改进大型语言模型在化学及相关科学领域的应用。通过该基准,研究人员可以更好地了解LLM在化学知识理解、推理和问题解决方面的能力,并针对性地改进模型。此外,ChemPro还可以用于开发智能化学教育系统、化学研究辅助工具等,提高科研效率和教学质量。
📄 摘要(原文)
We introduce ChemPro, a progressive benchmark with 4100 natural language question-answer pairs in Chemistry, across 4 coherent sections of difficulty designed to assess the proficiency of Large Language Models (LLMs) in a broad spectrum of general chemistry topics. We include Multiple Choice Questions and Numerical Questions spread across fine-grained information recall, long-horizon reasoning, multi-concept questions, problem-solving with nuanced articulation, and straightforward questions in a balanced ratio, effectively covering Bio-Chemistry, Inorganic-Chemistry, Organic-Chemistry and Physical-Chemistry. ChemPro is carefully designed analogous to a student's academic evaluation for basic to high-school chemistry. A gradual increase in the question difficulty rigorously tests the ability of LLMs to progress from solving basic problems to solving more sophisticated challenges. We evaluate 45+7 state-of-the-art LLMs, spanning both open-source and proprietary variants, and our analysis reveals that while LLMs perform well on basic chemistry questions, their accuracy declines with different types and levels of complexity. These findings highlight the critical limitations of LLMs in general scientific reasoning and understanding and point towards understudied dimensions of difficulty, emphasizing the need for more robust methodologies to improve LLMs.