Task--Specificity Score: Measuring How Much Instructions Really Matter for Supervision
作者: Pritam Kadasi, Abhishek Upperwal, Mayank Singh
分类: cs.CL, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出任务特异性评分(TSS)以衡量指令对LLM监督的重要性,提升小样本学习性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 任务特异性评分 大型语言模型 小样本学习 数据选择
📋 核心要点
- 现有指令调优数据集中,指令对输出的唯一确定性不足,存在多种指令对应相同输出的情况。
- 论文提出任务特异性评分(TSS)和TSS++,通过对比真实指令与替代指令,量化指令对输出的重要性。
- 实验表明,使用TSS选择的样本能提升小样本学习性能,且与困惑度等质量指标互补。
📝 摘要(中文)
指令调优已成为训练和调整大型语言模型的常用方法,但许多指令-输入-输出对的指定性较弱:对于给定的输入,相同的输出在几种替代指令下仍然是合理的。这就提出了一个简单的问题:指令是否唯一地决定了目标输出?我们提出了任务特异性评分(TSS)来量化指令对于预测其输出的重要性,通过将真实指令与同一输入的可行替代方案进行对比。我们进一步引入了TSS++,它使用硬性替代方案和一个小的质量项来减轻简单负例的影响。在三个指令数据集(Alpaca、Dolly-15k、NI-20)和三个开放LLM(Gemma、Llama、Qwen)上,我们表明,选择任务特定的示例可以提高在严格的token预算下的下游性能,并补充基于质量的过滤器,如困惑度和IFD。
🔬 方法详解
问题定义:现有指令调优方法依赖于大量的指令-输入-输出对,但这些数据集中存在一个问题:对于给定的输入,不同的指令可能产生相同的输出,这意味着指令的特异性不足。这种指令的模糊性会降低模型的学习效率,尤其是在资源有限的情况下。现有方法缺乏一种有效的方法来衡量指令对于生成特定输出的重要性,从而难以选择高质量的训练样本。
核心思路:论文的核心思想是通过对比真实指令与替代指令,来量化指令对于生成特定输出的重要性。如果一个指令对于生成特定的输出至关重要,那么用其他指令替换它应该会导致输出发生显著变化。反之,如果替换指令后输出没有明显变化,则说明该指令的特异性较低。TSS和TSS++正是基于这一思想设计的。
技术框架:该方法主要包含以下几个步骤:1) 对于给定的指令-输入-输出对,生成多个替代指令;2) 使用LLM分别在真实指令和替代指令下生成输出;3) 计算真实指令下的输出与替代指令下的输出之间的相似度;4) 根据相似度计算TSS或TSS++得分。TSS++在TSS的基础上,引入了硬性替代方案和一个小的质量项,以减轻简单负例的影响。
关键创新:该论文的关键创新在于提出了任务特异性评分(TSS)和TSS++,这是一种量化指令对于生成特定输出的重要性的新方法。与现有方法不同,TSS直接衡量指令的特异性,而不是依赖于间接的质量指标,如困惑度。TSS++通过引入硬性替代方案和质量项,进一步提高了评分的准确性和鲁棒性。
关键设计:TSS的计算公式为:TSS = 1 - Sim(Output_true, Output_alternative),其中Sim表示相似度函数,例如cosine similarity。TSS++的计算公式为:TSS++ = 1 - Sim(Output_true, Output_hard_alternative) + Quality_term,其中Output_hard_alternative表示在硬性替代指令下的输出,Quality_term是一个小的质量项,用于衡量真实输出的质量。具体实现中,替代指令的生成方式、相似度函数的选择以及质量项的计算方式都会影响最终的评分结果。
🖼️ 关键图片
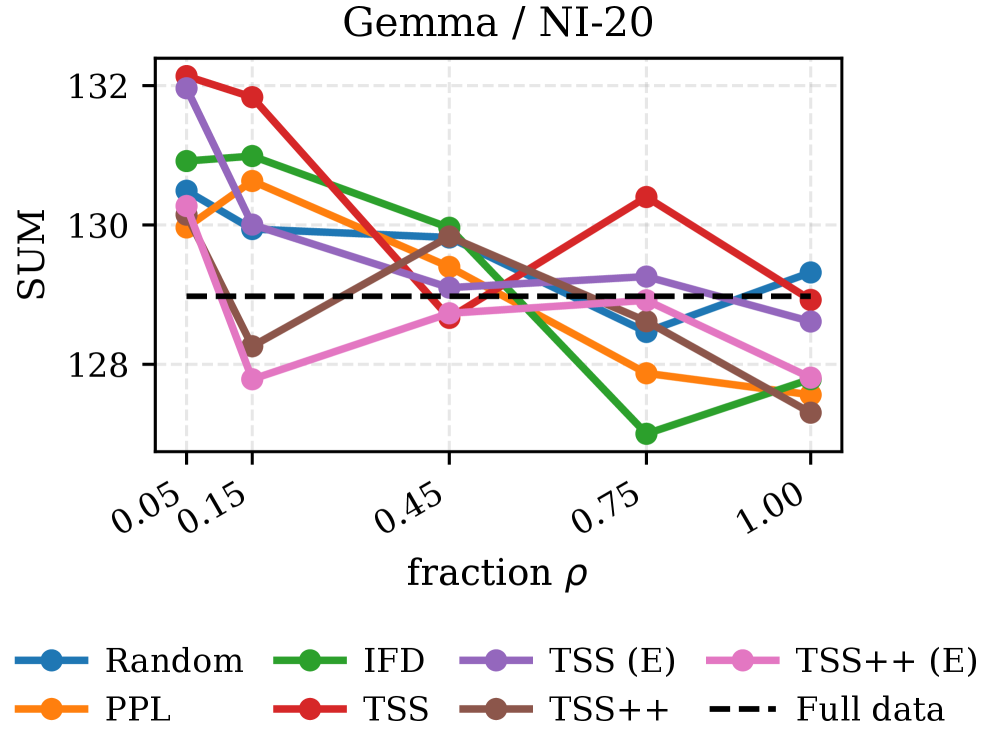
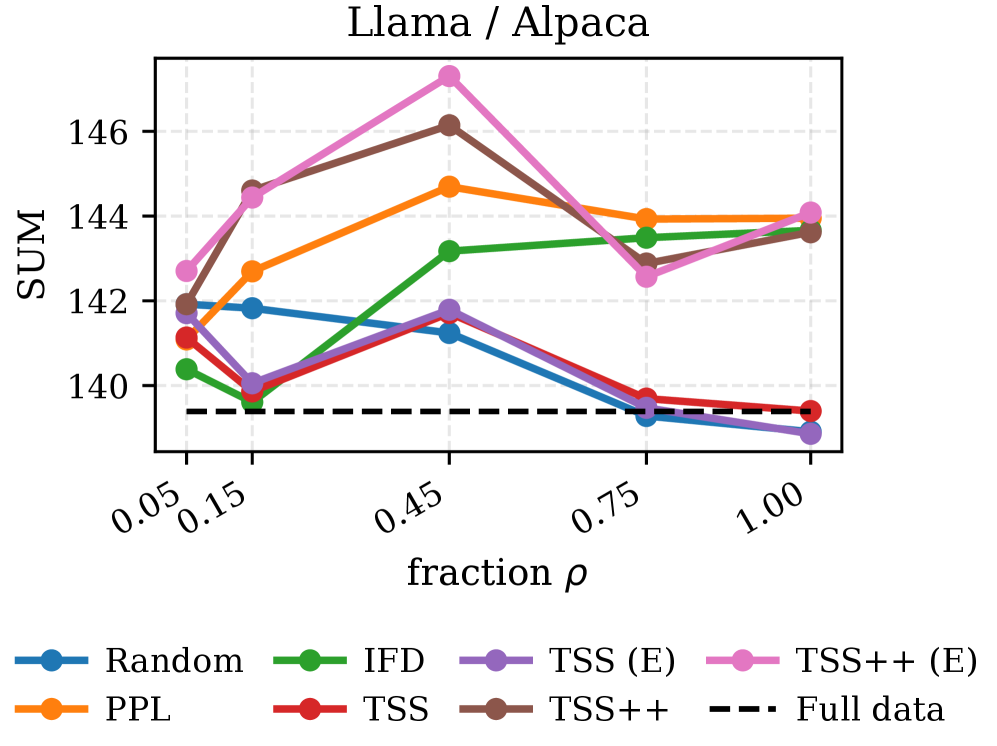
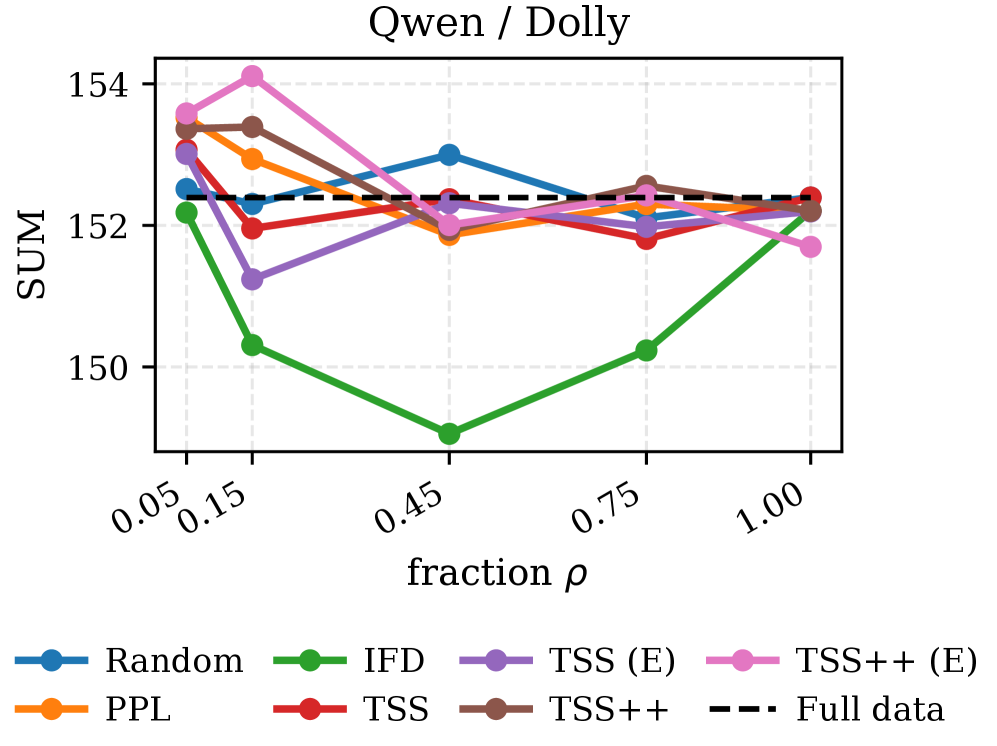
📊 实验亮点
实验结果表明,使用TSS/TSS++选择的样本在Alpaca、Dolly-15k和NI-20等数据集上,显著提升了Gemma、Llama和Qwen等LLM的下游任务性能。在token预算有限的情况下,TSS/TSS++的性能优于随机选择和基于困惑度的选择方法。此外,TSS/TSS++与困惑度等质量指标具有互补性,结合使用可以进一步提高性能。
🎯 应用场景
该研究成果可应用于指令调优数据集的清洗和筛选,提高LLM在小样本学习和资源受限场景下的性能。通过TSS/TSS++,可以更有效地选择高质量的指令样本,提升模型的泛化能力和效率。此外,该方法还可以用于评估不同指令数据集的质量,指导数据集的构建和优化。
📄 摘要(原文)
Instruction tuning is now the default way to train and adapt large language models, but many instruction--input--output pairs are only weakly specified: for a given input, the same output can remain plausible under several alternative instructions. This raises a simple question: \emph{does the instruction uniquely determine the target output?} We propose the \textbf{Task--Specificity Score (TSS)} to quantify how much an instruction matters for predicting its output, by contrasting the true instruction against plausible alternatives for the same input. We further introduce \textbf{TSS++}, which uses hard alternatives and a small quality term to mitigate easy-negative effects. Across three instruction datasets (\textsc{Alpaca}, \textsc{Dolly-15k}, \textsc{NI-20}) and three open LLMs (Gemma, Llama, Qwen), we show that selecting task-specific examples improves downstream performance under tight token budgets and complements quality-based filters such as perplexity and IFD.