AERO: Autonomous Evolutionary Reasoning Optimization via Endogenous Dual-Loop Feedback
作者: Zhitao Gao, Jie Ma, Xuhong Li, Pengyu Li, Ning Qu, Yaqiang Wu, Hui Liu, Jun Liu
分类: cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
AERO:通过内生双环反馈实现自主进化推理优化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自主进化 推理优化 大型语言模型 双环反馈 反事实校正
📋 核心要点
- 现有LLM推理依赖专家标注数据和外部验证,自进化方法易受内部反馈缺陷影响,强化错误先验。
- AERO通过内生双环系统,实现自我提问、回答和批判,从而进行自主推理进化。
- 实验表明,AERO在多个基准测试中优于现有基线,在Qwen3模型上平均提升4.57%-5.10%。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理方面取得了显著成功,但仍然受限于对专家标注数据和外部验证器的依赖。现有的自进化范式旨在绕过这些限制,但它们常常无法识别最佳学习区域,并且存在通过有缺陷的内部反馈来强化集体幻觉和不正确先验的风险。为了解决这些挑战,我们提出了自主进化推理优化(AERO),这是一个无监督框架,通过协同双环系统内部化自我提问、回答和批判来实现自主推理进化。受到最近发展区(ZPD)理论的启发,AERO利用基于熵的定位来瞄准“可解性差距”,并采用独立反事实校正来进行稳健的验证。此外,我们引入了一种交错训练策略,以同步跨职能角色的能力增长并防止课程崩溃。在跨越三个领域的九个基准上的广泛评估表明,AERO在Qwen3-4B-Base上实现了平均4.57%的性能提升,在Qwen3-8B-Base上实现了5.10%的性能提升,优于具有竞争力的基线。
🔬 方法详解
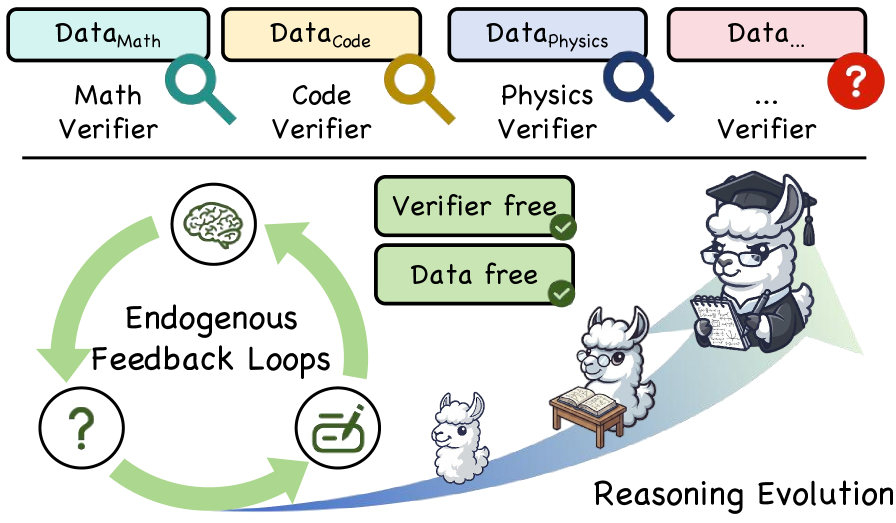
问题定义:现有大型语言模型在复杂推理任务中表现出色,但过度依赖人工标注数据和外部验证器。自进化方法虽然试图摆脱这些限制,但容易陷入局部最优,无法有效识别最佳学习区域,甚至可能因内部反馈机制的缺陷而加剧幻觉问题,强化错误的先验知识。因此,如何设计一种无需人工干预,能够自主进化并避免错误信息强化的推理优化框架是本文要解决的核心问题。
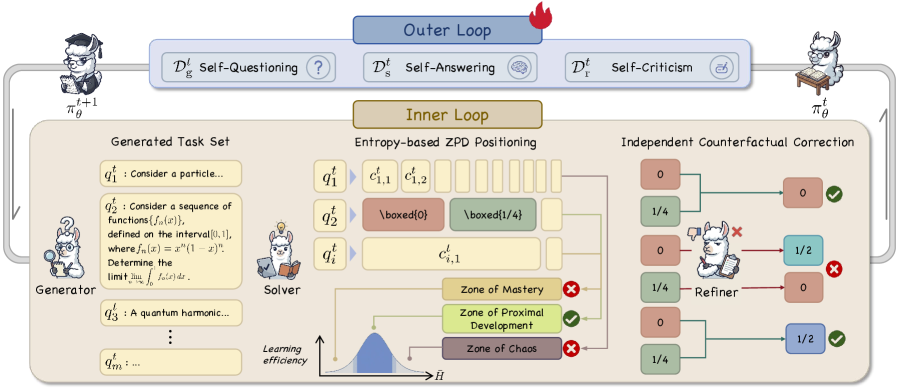
核心思路:AERO的核心思路是构建一个内生的双环反馈系统,模拟人类的自我反思和学习过程。该系统通过自我提问、自我回答和自我批判,不断优化推理能力。借鉴“最近发展区(ZPD)”理论,AERO并非盲目地进行学习,而是专注于模型能力边界附近的“可解性差距”,即那些模型通过少量引导就能解决的问题,从而实现高效学习。
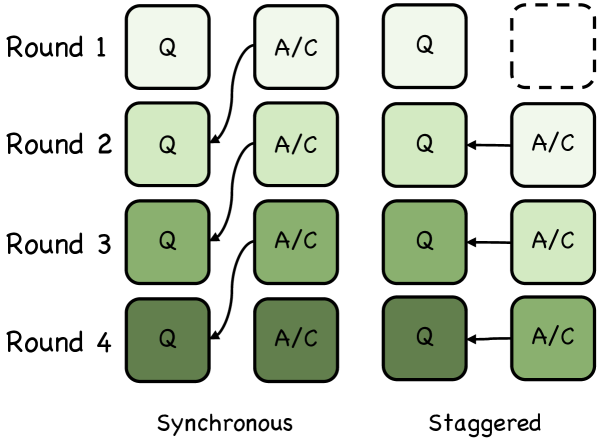
技术框架:AERO的整体框架包含两个主要循环:问题生成与解答循环,以及反事实校正循环。问题生成与解答循环负责根据当前模型的能力水平,生成具有挑战性的问题,并尝试解答。反事实校正循环则对解答进行验证,通过独立的反事实分析,识别并纠正潜在的错误。此外,AERO还采用了交错训练策略,同步不同功能角色的能力增长,避免出现课程崩溃现象。
关键创新:AERO的关键创新在于其完全自主的进化推理优化机制。与以往依赖外部数据或验证器的自进化方法不同,AERO完全依赖内部反馈,通过自我提问、回答和批判来提升推理能力。此外,基于熵的定位方法和独立反事实校正机制,能够有效识别最佳学习区域并避免错误信息的强化。
关键设计:AERO使用基于熵的定位方法来确定“可解性差距”,熵值越高,表明模型对该问题的理解程度越模糊,越有提升空间。独立反事实校正机制通过生成与原始问题相似但关键信息不同的反事实问题,来验证原始解答的正确性。交错训练策略则通过调整不同功能角色的训练频率,确保它们的能力同步增长。
🖼️ 关键图片
📊 实验亮点
AERO在九个基准测试中取得了显著的性能提升。具体而言,在Qwen3-4B-Base模型上,AERO实现了平均4.57%的性能提升;在Qwen3-8B-Base模型上,AERO实现了平均5.10%的性能提升。这些结果表明,AERO能够有效提升大型语言模型的推理能力,并且优于现有的竞争基线。
🎯 应用场景
AERO的潜在应用领域包括智能问答系统、自动推理引擎、以及需要复杂逻辑推理的机器人等。该研究的实际价值在于降低了对人工标注数据的依赖,提高了模型的自主学习能力和鲁棒性。未来,AERO有望应用于更广泛的领域,例如医疗诊断、金融分析等,为各行业提供更智能、更可靠的解决方案。
📄 摘要(原文)
Large Language Models (LLMs) have achieved significant success in complex reasoning but remain bottlenecked by reliance on expert-annotated data and external verifiers. While existing self-evolution paradigms aim to bypass these constraints, they often fail to identify the optimal learning zone and risk reinforcing collective hallucinations and incorrect priors through flawed internal feedback. To address these challenges, we propose \underline{A}utonomous \underline{E}volutionary \underline{R}easoning \underline{O}ptimization (AERO), an unsupervised framework that achieves autonomous reasoning evolution by internalizing self-questioning, answering, and criticism within a synergistic dual-loop system. Inspired by the \textit{Zone of Proximal Development (ZPD)} theory, AERO utilizes entropy-based positioning to target the ``solvability gap'' and employs Independent Counterfactual Correction for robust verification. Furthermore, we introduce a Staggered Training Strategy to synchronize capability growth across functional roles and prevent curriculum collapse. Extensive evaluations across nine benchmarks spanning three domains demonstrate that AERO achieves average performance improvements of 4.57\% on Qwen3-4B-Base and 5.10\% on Qwen3-8B-Base, outperforming competitive baselines. Code is available at https://github.com/mira-ai-lab/AERO.