ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution
作者: Junjie Huang, Jiarui Qin, Di Yin, Weiwen Liu, Yong Yu, Xing Sun, Weinan Zhang
分类: cs.CL
发布日期: 2026-02-03
备注: 25 pages
💡 一句话要点
ReMiT:强化学习引导的LLM中期训练,实现迭代式模型进化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 中期训练 迭代训练 推理能力
📋 核心要点
- 现有LLM训练流程是单向的,缺乏利用后训练信息反哺预训练阶段的机制,限制了模型能力的持续提升。
- ReMiT利用强化学习调整模型的推理先验,在预训练的中期(退火)阶段动态调整token权重,提升关键推理能力。
- 实验表明,ReMiT在多个基准测试中显著提升了LLM的性能,验证了迭代式训练的有效性。
📝 摘要(中文)
大型语言模型(LLM)的标准训练流程通常是单向的,从预训练到后训练。然而,双向流程的潜力——即从后训练中获得的见解反过来改进预训练的基础模型——仍未被探索。本文旨在建立一个自我强化的飞轮:一个循环,其中强化学习(RL)调整的模型加强基础模型,而基础模型反过来又增强后续的后训练性能,无需专门训练的教师或参考模型。为了实现这一点,本文分析了训练动态,并将中期训练(退火)阶段确定为模型能力的关键转折点。该阶段通常发生在预训练结束时,在快速衰减的学习率下利用高质量的语料库。基于这一洞察,本文提出了ReMiT(强化学习引导的中期训练)。具体而言,ReMiT利用RL调整模型的推理先验,在模型中期训练阶段动态地重新加权token,优先考虑那些对推理至关重要的token。实验结果表明,ReMiT在涵盖数学、代码和一般推理的10个预训练基准测试中平均提高了3%,并在整个后训练流程中保持了超过2%的增益。这些结果验证了一个迭代反馈循环,从而实现了LLM的持续和自我强化进化。
🔬 方法详解
问题定义:现有大型语言模型的训练流程通常是单向的,即从预训练到后训练,缺乏一个有效的反馈机制来利用后训练阶段获得的知识来改进预训练模型。这导致预训练阶段的不足可能会限制后续后训练阶段的性能。因此,如何建立一个迭代的、自我强化的训练流程,从而持续提升LLM的能力,是一个重要的研究问题。
核心思路:ReMiT的核心思路是利用强化学习(RL)调整后的模型所学习到的推理先验知识,来指导预训练过程中的中期训练阶段。具体来说,通过RL训练的模型能够识别出对于推理至关重要的token,然后ReMiT在预训练的中期训练阶段,动态地对这些token进行重新加权,从而提升模型对关键信息的关注度,进而提升模型的推理能力。
技术框架:ReMiT的整体框架包含以下几个主要阶段:1) 预训练阶段:使用标准的方法对LLM进行预训练。2) 强化学习训练阶段:使用RL方法对预训练的模型进行微调,使其具备更强的推理能力。3) 中期训练阶段:利用RL训练的模型,计算每个token的重要性权重,并在预训练的中期训练阶段,根据这些权重对token进行重新加权。4) 后训练阶段:使用标准的方法对中期训练后的模型进行后训练。
关键创新:ReMiT的关键创新在于提出了一个利用强化学习引导预训练中期训练的迭代式训练框架。与传统的单向训练流程不同,ReMiT通过RL模型将后训练阶段的知识反馈到预训练阶段,从而实现了模型的自我强化和持续进化。此外,ReMiT不需要额外的教师模型或参考模型,降低了训练成本。
关键设计:ReMiT的关键设计包括:1) 使用RL训练的模型来计算token的重要性权重。具体来说,可以使用RL模型的策略梯度来估计每个token对最终奖励的贡献。2) 在中期训练阶段,使用计算出的token权重来调整交叉熵损失函数。例如,可以对重要的token赋予更高的权重,从而使模型更加关注这些token。3) 学习率的设置:中期训练阶段的学习率需要仔细调整,以避免过度拟合或欠拟合。
🖼️ 关键图片
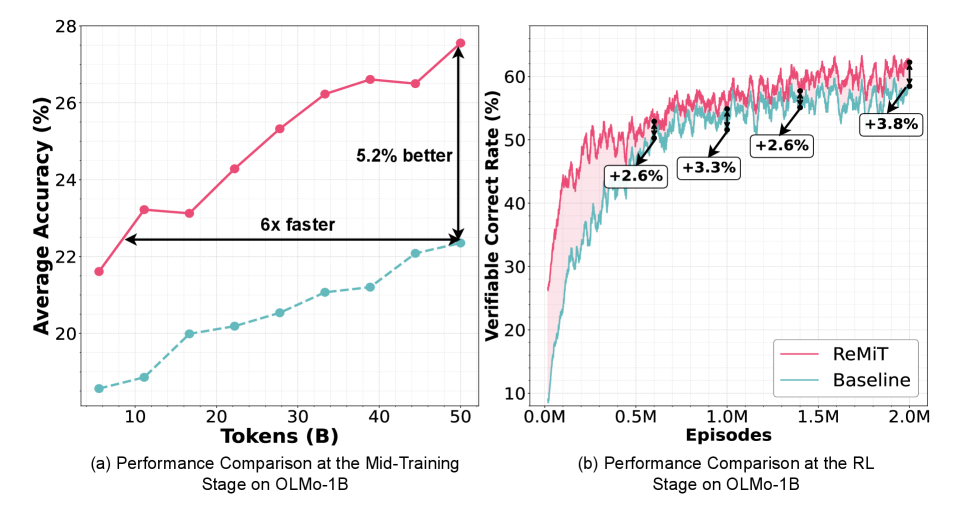


📊 实验亮点
ReMiT在10个预训练基准测试中平均提高了3%,这些基准测试涵盖了数学、代码和一般推理等多个领域。更重要的是,ReMiT在整个后训练流程中保持了超过2%的增益,这表明ReMiT不仅提升了预训练模型的性能,而且还使其在后续的训练中更具优势。这些结果验证了ReMiT的有效性,并表明迭代式训练是提升LLM能力的一种有前景的方法。
🎯 应用场景
ReMiT的潜在应用领域包括:1) 提升各种LLM在数学、代码和一般推理等任务上的性能。2) 加速LLM的训练过程,通过迭代式训练,可以更快地达到相同的性能水平。3) 降低LLM的训练成本,ReMiT不需要额外的教师模型或参考模型。未来,ReMiT可以扩展到其他类型的模型和任务中,例如多模态模型和自然语言生成任务。
📄 摘要(原文)
Standard training pipelines for large language models (LLMs) are typically unidirectional, progressing from pre-training to post-training. However, the potential for a bidirectional process--where insights from post-training retroactively improve the pre-trained foundation--remains unexplored. We aim to establish a self-reinforcing flywheel: a cycle in which reinforcement learning (RL)-tuned model strengthens the base model, which in turn enhances subsequent post-training performance, requiring no specially trained teacher or reference model. To realize this, we analyze training dynamics and identify the mid-training (annealing) phase as a critical turning point for model capabilities. This phase typically occurs at the end of pre-training, utilizing high-quality corpora under a rapidly decaying learning rate. Building upon this insight, we introduce ReMiT (Reinforcement Learning-Guided Mid-Training). Specifically, ReMiT leverages the reasoning priors of RL-tuned models to dynamically reweight tokens during the mid-training phase, prioritizing those pivotal for reasoning. Empirically, ReMiT achieves an average improvement of 3\% on 10 pre-training benchmarks, spanning math, code, and general reasoning, and sustains these gains by over 2\% throughout the post-training pipeline. These results validate an iterative feedback loop, enabling continuous and self-reinforcing evolution of LLMs.