CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
作者: Ran Li, Zeyuan Liu, Yinghao chen, Bingxiang He, Jiarui Yuan, Zixuan Fu, Weize Chen, Jinyi Hu, Zhiyuan Liu, Maosong Sun
分类: cs.CL
发布日期: 2026-02-03
备注: work in progress
💡 一句话要点
提出CPMobius,一种用于数据自由强化学习的迭代教练-队员推理框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据自由学习 强化学习 大型语言模型 推理能力 教练-队员范式
📋 核心要点
- 现有LLM推理依赖大量人工标注数据,监督密集型训练范式难以为继,面临可扩展性瓶颈。
- CPMobius采用教练-队员协作范式,教练指导队员,队员解决任务,通过合作优化提升推理能力。
- CPMobius无需外部数据,在数学推理任务上显著优于现有无监督方法,提升了模型准确率。
📝 摘要(中文)
大型语言模型(LLMs)在复杂推理方面展现出强大的潜力,但其进展受到对大量高质量人工标注任务和标签的依赖的根本限制,无论是通过监督微调(SFT)还是在特定推理数据上进行强化学习(RL)。这种依赖使得监督密集型训练范式越来越难以为继,并且在实践中已经出现了可扩展性降低的迹象。为了克服这一限制,我们引入了CPMöbius (CPMobius),这是一种用于推理模型数据自由强化学习的协作教练-队员范式。与传统的对抗性自博弈不同,CPMobius受到现实世界人类体育协作和多智能体协作的启发,将教练和队员视为独立但合作的角色。教练提出针对队员能力的指令,并根据队员表现的变化获得奖励,而队员则因解决教练生成的越来越具有指导性的任务而获得奖励。这种合作优化循环旨在直接提高队员的数学推理能力。值得注意的是,CPMobius在不依赖任何外部训练数据的情况下取得了显著的改进,优于现有的无监督方法。例如,在Qwen2.5-Math-7B-Instruct上,我们的方法在总体平均准确率上提高了+4.9,在分布外平均准确率上提高了+5.4,超过RENT +1.5的总体准确率和R-zero +4.2的OOD准确率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在推理能力提升过程中对大量标注数据的依赖问题。现有方法,如监督微调和基于推理数据的强化学习,需要耗费大量人力物力进行数据标注,且存在可扩展性问题。因此,如何在不依赖外部数据的情况下,有效提升LLM的推理能力是一个关键挑战。
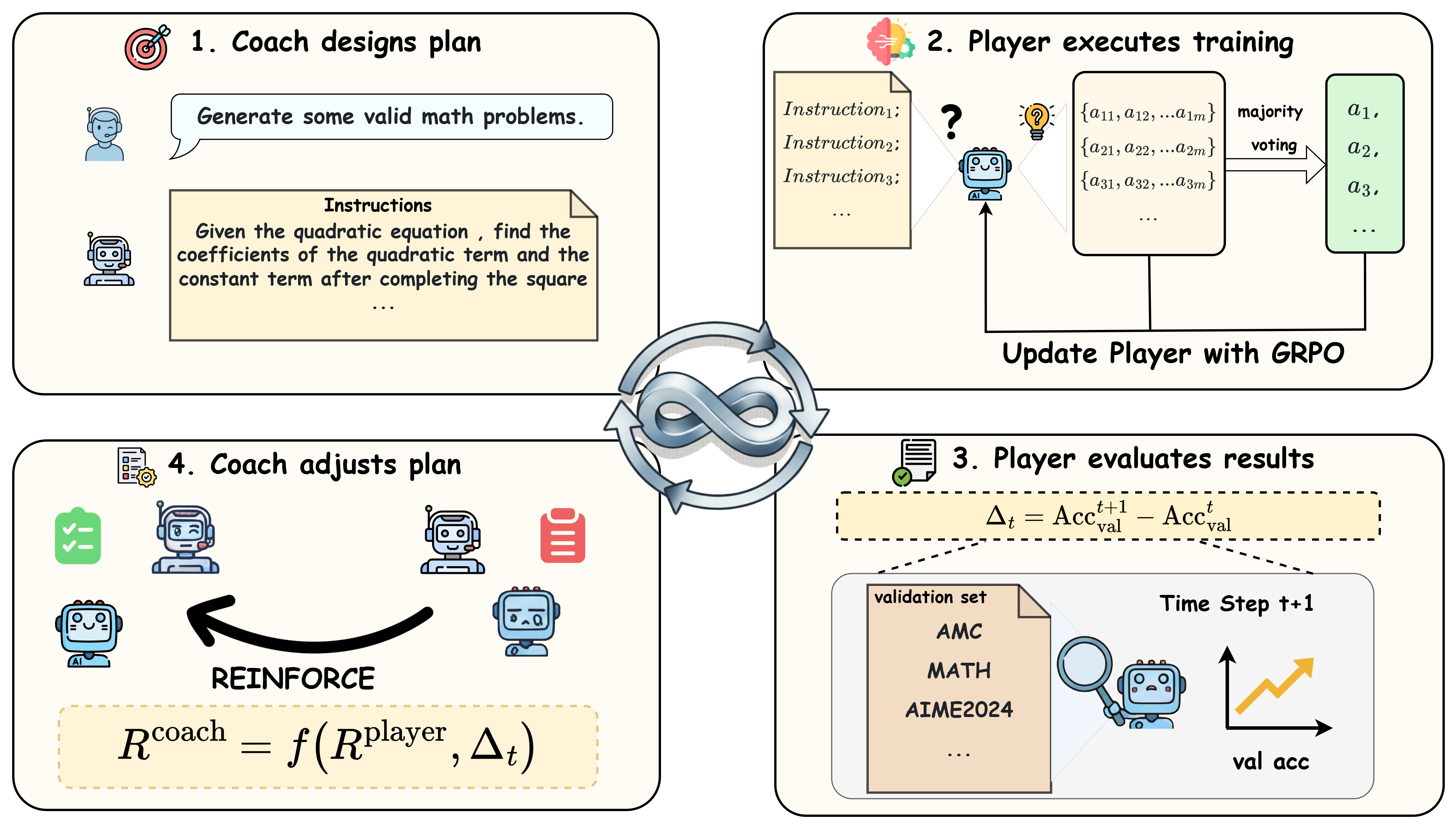
核心思路:论文的核心思路是借鉴人类体育运动中的教练-队员协作模式,设计一种数据自由的强化学习框架。教练负责生成具有挑战性的任务,并根据队员的表现给予反馈;队员则负责解决这些任务,并根据解决情况获得奖励。通过这种合作优化,共同提升模型的推理能力。这种设计避免了对外部数据的依赖,并模拟了人类学习和进步的过程。
技术框架:CPMobius框架包含两个主要角色:教练(Coach)和队员(Player)。教练负责生成任务,并根据队员的表现给予奖励。队员负责解决教练生成的任务,并根据解决情况获得奖励。整个训练过程是一个迭代的循环:1) 教练根据队员当前的能力,生成更具挑战性的任务;2) 队员尝试解决这些任务;3) 教练根据队员的表现,调整任务的难度和奖励;4) 队员根据教练的反馈,改进自己的解题策略。这个循环不断迭代,直到队员的推理能力达到预期的水平。
关键创新:CPMobius的关键创新在于其协作式的教练-队员范式。与传统的对抗性自博弈不同,CPMobius强调教练和队员之间的合作,而不是竞争。教练的目标是帮助队员提升能力,而不是击败队员。这种合作式的训练方式能够更有效地提升模型的推理能力。此外,CPMobius无需外部数据,这使得它更具可扩展性和实用性。
关键设计:在具体实现上,教练和队员可以是独立的模型,也可以是同一个模型的不同部分。教练的任务生成策略可以通过强化学习来训练,奖励函数可以根据队员的解题正确率、效率等指标来设计。队员的解题策略也可以通过强化学习来训练,奖励函数可以根据解题的正确率、效率等指标来设计。论文中具体使用了Qwen2.5-Math-7B-Instruct作为基础模型,并针对数学推理任务设计了相应的奖励函数和任务生成策略。具体参数设置和网络结构细节未在摘要中详细说明,可能在论文正文中给出。
🖼️ 关键图片


📊 实验亮点
CPMobius在Qwen2.5-Math-7B-Instruct模型上取得了显著的性能提升。在总体平均准确率上提高了+4.9,在分布外(OOD)平均准确率上提高了+5.4。相比于现有无监督方法,CPMobius在总体准确率上超过RENT +1.5,在OOD准确率上超过R-zero +4.2。这些结果表明,CPMobius是一种有效的数据自由强化学习方法,能够显著提升LLM的推理能力。
🎯 应用场景
CPMobius具有广泛的应用前景,可用于提升各种LLM在数学、逻辑推理等领域的表现。该方法无需标注数据,降低了训练成本,加速了LLM在教育、金融、科研等领域的应用。未来,该方法有望扩展到其他复杂推理任务,并与其他无监督学习技术结合,进一步提升LLM的智能化水平。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.