Reward-free Alignment for Conflicting Objectives
作者: Peter Chen, Xiaopeng Li, Xi Chen, Tianyi Lin
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-02
备注: 27 pages
💡 一句话要点
提出RACO框架,通过冲突规避梯度下降解决多目标LLM对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多目标对齐 大型语言模型 冲突规避梯度下降 无奖励学习 帕累托优化
📋 核心要点
- 现有LLM对齐方法在处理多目标冲突时,简单聚合偏好易导致训练不稳定和权衡不佳。
- RACO框架通过冲突规避梯度下降,直接利用成对偏好数据解决梯度冲突,无需奖励模型。
- 实验表明,RACO在多目标摘要和安全对齐任务中,相比基线方法能实现更好的帕累托权衡。
📝 摘要(中文)
直接对齐方法越来越多地被用于使大型语言模型(LLM)与人类偏好对齐。然而,许多实际对齐问题涉及多个冲突的目标,对偏好进行简单的聚合可能导致不稳定的训练和较差的权衡。特别是,加权损失方法可能无法识别同时改进所有目标的更新方向,并且现有的多目标方法通常依赖于显式的奖励模型,从而引入额外的复杂性并扭曲用户指定的偏好。本文的贡献有两方面。首先,我们提出了一个用于冲突目标的无奖励对齐框架(RACO),该框架直接利用成对偏好数据,并通过一种新颖的冲突规避梯度下降的裁剪变体来解决梯度冲突。我们提供了收敛到尊重用户指定目标权重的帕累托临界点的保证,并进一步表明,在双目标设置中,裁剪可以严格提高收敛速度。其次,我们使用一些启发式方法改进了我们的方法,并进行实验以证明所提出的框架与LLM对齐的兼容性。在多个LLM系列(Qwen 3、Llama 3、Gemma 3)上的多目标摘要和安全对齐任务的定性和定量评估表明,与现有的多目标对齐基线相比,我们的方法始终能实现更好的帕累托权衡。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在多目标对齐中,因目标冲突导致的训练不稳定和权衡不佳问题。现有方法,如加权损失,难以找到同时改进所有目标的更新方向。依赖奖励模型的方法则引入了额外的复杂性,并可能扭曲用户偏好。
核心思路:论文的核心思路是提出一个无奖励的对齐框架(RACO),直接利用成对偏好数据,并通过一种新颖的冲突规避梯度下降的裁剪变体来解决梯度冲突。通过避免显式奖励模型的引入,RACO旨在更直接地对齐LLM与用户偏好,并实现更好的多目标权衡。
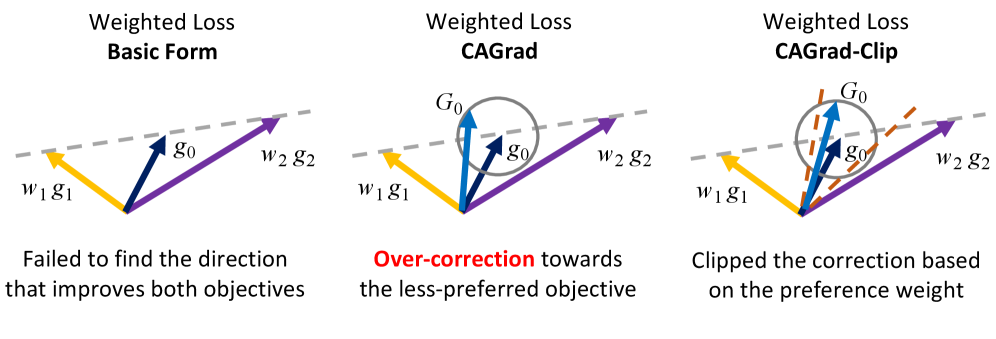
技术框架:RACO框架主要包含以下几个阶段:1) 数据收集:收集成对偏好数据,反映不同目标之间的权衡。2) 梯度计算:计算每个目标的梯度。3) 冲突规避梯度下降:使用裁剪的冲突规避梯度下降算法,解决梯度冲突,找到一个能够同时改进多个目标的更新方向。4) 模型更新:使用计算得到的更新方向来更新LLM的参数。
关键创新:RACO的关键创新在于其冲突规避梯度下降算法的裁剪变体。该算法能够有效地解决多目标优化中的梯度冲突问题,并保证收敛到尊重用户指定目标权重的帕累托临界点。此外,RACO框架避免了使用显式奖励模型,从而降低了复杂性,并减少了用户偏好被扭曲的可能性。
关键设计:RACO的关键设计包括:1) 冲突规避梯度下降算法:该算法通过计算梯度之间的夹角,并对冲突的梯度进行裁剪,从而避免了梯度冲突。2) 裁剪策略:论文提出了一种新颖的裁剪策略,可以严格提高双目标设置中的收敛速度。3) 目标权重:RACO框架允许用户指定不同目标的权重,从而实现对不同目标之间的权衡。
🖼️ 关键图片
📊 实验亮点
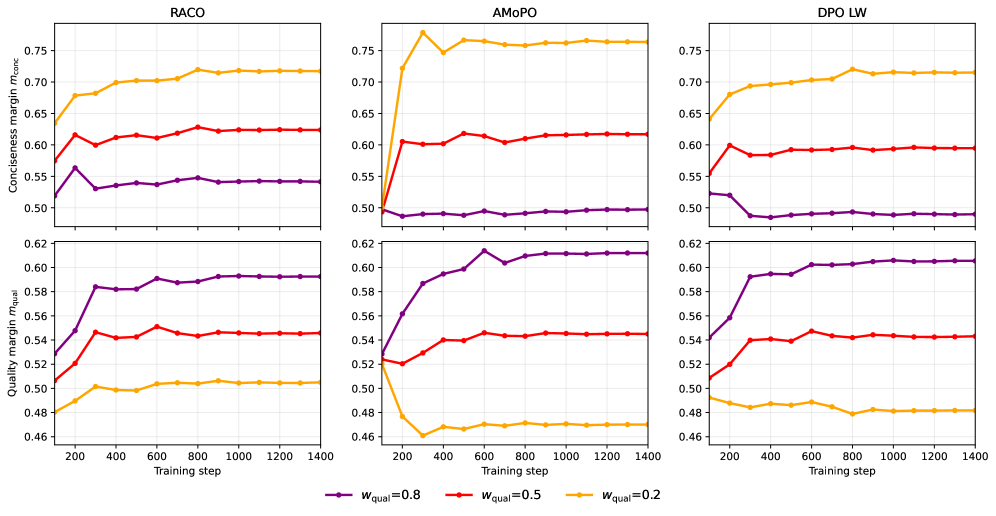
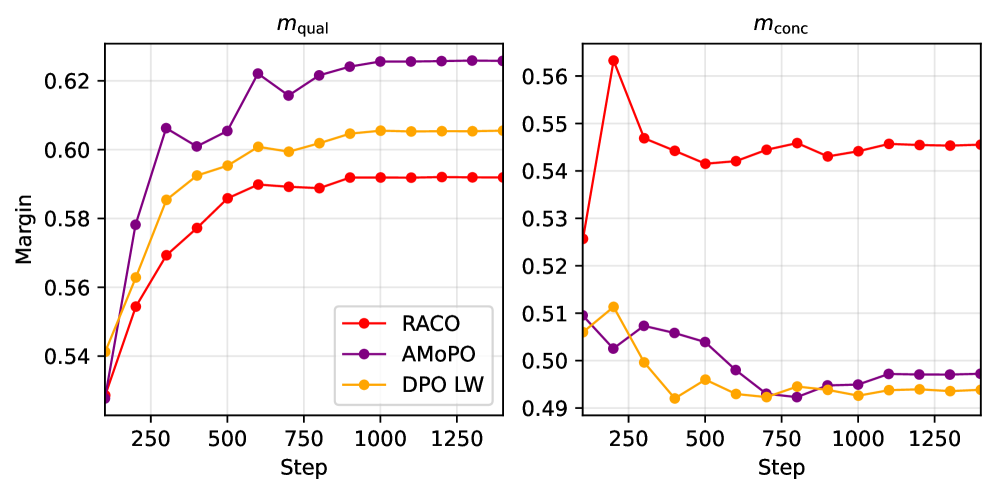
实验结果表明,RACO在多目标摘要和安全对齐任务中,相比于现有的多目标对齐基线方法,能够始终实现更好的帕累托权衡。在Qwen 3、Llama 3和Gemma 3等多个LLM系列上都验证了RACO的有效性。定性和定量评估均表明,RACO能够更好地平衡不同目标之间的冲突,并生成更符合用户偏好的结果。
🎯 应用场景
RACO框架可应用于各种需要多目标对齐的LLM应用场景,例如安全对话、无害内容生成、多目标摘要等。该方法能够帮助LLM在多个冲突目标之间取得更好的平衡,从而提高LLM的实用性和安全性。此外,RACO框架的无奖励特性使其更易于部署和维护。
📄 摘要(原文)
Direct alignment methods are increasingly used to align large language models (LLMs) with human preferences. However, many real-world alignment problems involve multiple conflicting objectives, where naive aggregation of preferences can lead to unstable training and poor trade-offs. In particular, weighted loss methods may fail to identify update directions that simultaneously improve all objectives, and existing multi-objective approaches often rely on explicit reward models, introducing additional complexity and distorting user-specified preferences. The contributions of this paper are two-fold. First, we propose a Reward-free Alignment framework for Conflicted Objectives (RACO) that directly leverages pairwise preference data and resolves gradient conflicts via a novel clipped variant of conflict-averse gradient descent. We provide convergence guarantees to Pareto-critical points that respect user-specified objective weights, and further show that clipping can strictly improve convergence rate in the two-objective setting. Second, we improve our method using some heuristics and conduct experiments to demonstrate the compatibility of the proposed framework for LLM alignment. Both qualitative and quantitative evaluations on multi-objective summarization and safety alignment tasks across multiple LLM families (Qwen 3, Llama 3, Gemma 3) show that our method consistently achieves better Pareto trade-offs compared to existing multi-objective alignment baselines.