Abstract Activation Spaces for Content-Invariant Reasoning in Large Language Models
作者: Gabriele Maraia, Marco Valentino, Fabio Massimo Zanzotto, Leonardo Ranaldi
分类: cs.CL, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出抽象激活空间框架,提升大语言模型在内容无关推理中的鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 形式推理 内容效应 抽象推理 激活空间
📋 核心要点
- 大语言模型在形式推理中易受语义内容干扰,导致内容效应,影响推理的正确性。
- 论文提出一种基于抽象激活空间的框架,将结构推理与词汇语义分离,减少语义干扰。
- 实验表明,该方法能有效减少内容驱动的错误,提高模型对有效性的敏感性,增强鲁棒性。
📝 摘要(中文)
大型语言模型(LLM)在三段论推理中常常面临演绎判断的困难,系统性地将语义合理性与形式有效性混淆,这种现象被称为内容效应。即使模型生成逐步解释,这种偏差仍然存在,表明中间推理可能继承了影响答案的相同语义捷径。最近的方法提出通过增加推理时的结构约束来缓解这个问题,或者通过鼓励抽象的中间表示,或者直接干预模型的内部计算;然而,可靠地抑制语义干扰仍然是一个开放的挑战。为了使形式演绎对语义内容不那么敏感,我们引入了一个用于抽象引导推理的框架,该框架明确地将结构推理与词汇语义分离。我们构建了配对的包含内容和抽象的三段论,并使用模型在抽象输入上的激活来定义一个抽象推理空间。然后,我们学习轻量级的抽象器,这些抽象器从内容条件残差流状态预测与该空间对齐的表示,并在前向传递期间通过多层干预整合这些预测。使用跨语言迁移作为测试平台,我们表明,与抽象对齐的引导减少了内容驱动的错误,并提高了对有效性敏感的性能。我们的结果将激活级别的抽象定位为一种可扩展的机制,用于增强LLM在形式推理中对抗语义干扰的鲁棒性。
🔬 方法详解
问题定义:大语言模型在进行三段论推理时,容易受到语义内容的影响,即“内容效应”。模型倾向于根据结论的语义合理性而非逻辑有效性进行判断,即使模型生成了中间推理步骤,也无法避免这种偏差。现有的方法试图通过增加结构约束或直接干预模型内部计算来缓解这个问题,但仍然难以完全消除语义干扰。
核心思路:论文的核心思路是将结构推理与词汇语义显式地分离。通过构建抽象的三段论,并利用模型在抽象输入上的激活来定义一个抽象推理空间。然后,训练一个轻量级的抽象器,将内容相关的表示映射到这个抽象空间,从而减少语义内容对推理过程的影响。
技术框架:整体框架包含以下几个主要步骤:1) 构建配对的包含内容和抽象的三段论数据集;2) 使用抽象的三段论作为输入,获取模型在各层的激活值,定义抽象推理空间;3) 训练抽象器,将内容相关的残差流状态映射到抽象推理空间;4) 在前向推理过程中,通过多层干预,将抽象器的预测结果整合到模型的内部表示中。
关键创新:最重要的技术创新点在于显式地构建和利用抽象推理空间,并通过抽象器将内容相关的表示映射到该空间。这种方法能够有效地分离结构推理和词汇语义,从而减少语义干扰。与现有方法相比,该方法更加直接和可控,能够更好地抑制内容效应。
关键设计:关键设计包括:1) 抽象三段论的构建方式,需要保证其结构与内容三段论一致,但语义内容是抽象的;2) 抽象器的训练目标,需要保证其输出与抽象推理空间中的表示对齐;3) 多层干预的具体实现方式,例如在哪些层进行干预,以及如何将抽象器的预测结果整合到模型的内部表示中。论文使用了跨语言迁移作为测试平台,验证了该方法的有效性。
🖼️ 关键图片

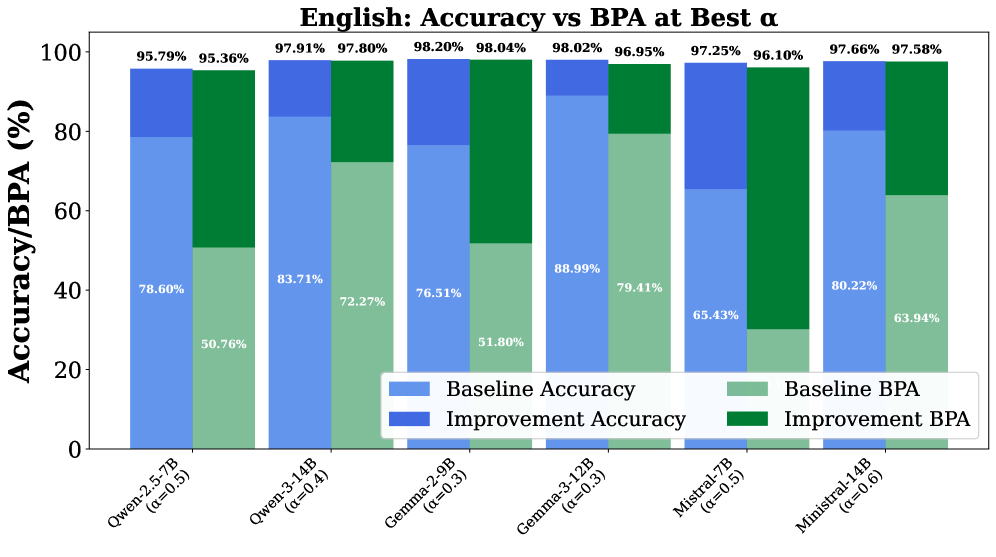
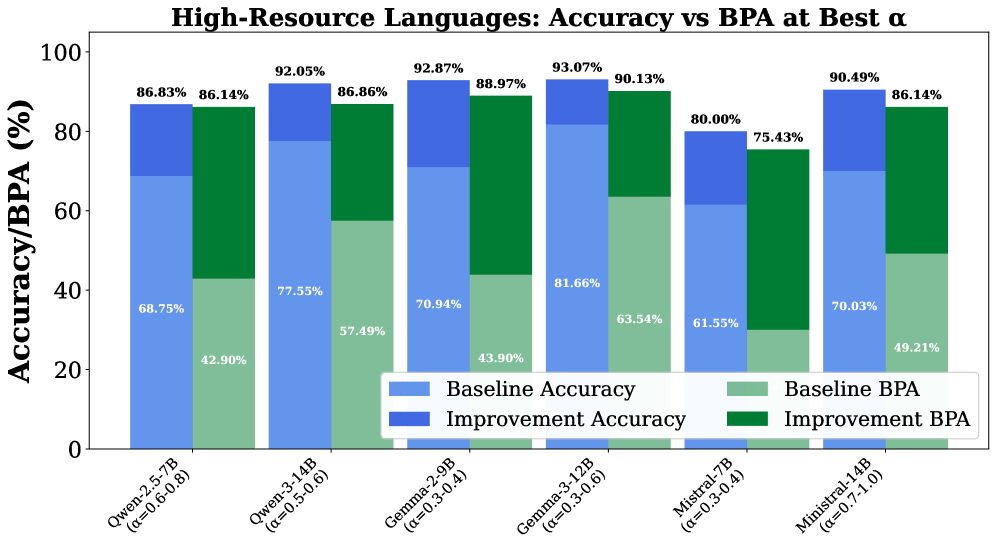
📊 实验亮点
实验结果表明,通过抽象对齐的引导,可以有效减少内容驱动的错误,并提高模型对有效性的敏感性。在跨语言迁移实验中,该方法能够显著提升模型在形式推理任务上的性能,验证了其在对抗语义干扰方面的有效性。
🎯 应用场景
该研究成果可应用于提升大语言模型在需要形式推理的场景中的可靠性,例如法律文本分析、数学问题求解、代码理解等。通过减少语义干扰,可以提高模型在这些领域的准确性和鲁棒性,使其能够更好地服务于专业领域。
📄 摘要(原文)
Large Language Models (LLMs) often struggle with deductive judgment in syllogistic reasoning, systematically conflating semantic plausibility with formal validity a phenomenon known as content effect. This bias persists even when models generate step-wise explanations, indicating that intermediate rationales may inherit the same semantic shortcuts that affect answers. Recent approaches propose mitigating this issue by increasing inference-time structural constraints, either by encouraging abstract intermediate representations or by intervening directly in the model's internal computations; however, reliably suppressing semantic interference remains an open challenge. To make formal deduction less sensitive to semantic content, we introduce a framework for abstraction-guided reasoning that explicitly separates structural inference from lexical semantics. We construct paired content-laden and abstract syllogisms and use the model's activations on abstract inputs to define an abstract reasoning space. We then learn lightweight Abstractors that, from content-conditioned residual-stream states, predict representations aligned with this space and integrate these predictions via multi-layer interventions during the forward pass. Using cross-lingual transfer as a test bed, we show that abstraction-aligned steering reduces content-driven errors and improves validity-sensitive performance. Our results position activation-level abstraction as a scalable mechanism for enhancing the robustness of formal reasoning in LLMs against semantic interference.