Proof-RM: A Scalable and Generalizable Reward Model for Math Proof
作者: Haotong Yang, Zitong Wang, Shijia Kang, Siqi Yang, Wenkai Yu, Xu Niu, Yike Sun, Yi Hu, Zhouchen Lin, Muhan Zhang
分类: cs.CL
发布日期: 2026-02-02
备注: Under review
💡 一句话要点
提出Proof-RM,一种可扩展且泛化的数学证明奖励模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学证明 奖励模型 强化学习 大型语言模型 可验证奖励
📋 核心要点
- 现有方法难以验证复杂数学证明的正确性,阻碍了LLM在高级数学领域的应用。
- Proof-RM通过大规模LLM生成数据和分层人工审核,构建高质量的“问题-证明-检查”数据集。
- 实验表明,Proof-RM在奖励准确性、泛化能力和测试时指导方面表现出色,提升了LLM的数学能力。
📝 摘要(中文)
大型语言模型(LLMs)通过可验证奖励的强化学习(RLVR)展示了强大的数学推理能力,但许多高级数学问题是基于证明的,无法通过简单的答案匹配来确定证明的真实性。为了实现自动验证,需要一个能够可靠评估完整证明过程的奖励模型(RM)。本文设计了一个可扩展的数据构建流程,以最小的人工干预,利用LLMs生成大量高质量的“问题-证明-检查”三元组数据。通过系统地改变问题来源、生成方法和模型配置,我们创建了涵盖多个难度级别、语言风格和错误类型的多样化问题-证明对,并通过分层人工审查进行标签对齐。利用这些数据,我们训练了一个证明检查RM,结合额外的过程奖励和token权重平衡来稳定RL过程。实验从多个角度验证了模型的可扩展性和强大性能,包括奖励准确性、泛化能力和测试时指导,为加强LLM的数学能力提供了重要的实践方法和工具。
🔬 方法详解
问题定义:现有基于答案匹配的奖励模型无法有效评估数学证明的正确性,尤其是在高级数学问题中,证明过程的合理性至关重要。缺乏可靠的自动验证手段限制了LLM在数学证明领域的应用。
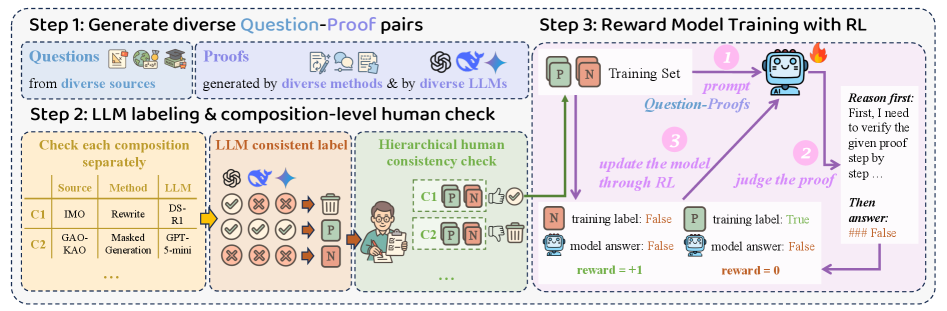
核心思路:利用LLM生成大量的“问题-证明-检查”三元组数据,并结合人工审核,构建高质量的训练数据集。通过训练奖励模型,使其能够评估证明过程的正确性,从而指导LLM生成更可靠的数学证明。
技术框架:整体框架包括三个主要阶段:1) 数据生成阶段:利用LLM生成多样化的“问题-证明”对,涵盖不同难度、风格和错误类型。2) 数据审核阶段:通过分层人工审核,对生成的数据进行标签对齐,确保数据质量。3) 模型训练阶段:训练Proof-RM,使其能够准确评估证明过程的正确性。
关键创新:核心创新在于数据构建流程的可扩展性和通用性。通过系统地改变问题来源、生成方法和模型配置,可以生成大量多样化的数据,从而提高模型的泛化能力。此外,结合过程奖励和token权重平衡,可以稳定RL过程,提高训练效率。
关键设计:在模型训练阶段,采用了过程奖励,鼓励模型关注证明过程中的关键步骤。同时,引入token权重平衡,解决数据集中不同token出现频率不平衡的问题。具体的网络结构和损失函数细节未在摘要中明确说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Proof-RM在奖励准确性、泛化能力和测试时指导方面表现出色。具体性能数据和对比基线未在摘要中明确说明,属于未知信息。但论文强调了模型的可扩展性和强大性能,为加强LLM的数学能力提供了重要的实践方法和工具。
🎯 应用场景
Proof-RM可应用于自动数学证明验证、数学教育辅助、以及提升LLM在科学研究等领域的推理能力。该模型能够帮助学生和研究人员检查数学证明的正确性,并为LLM在需要严谨推理的场景中提供更可靠的保障,具有广泛的应用前景。
📄 摘要(原文)
While Large Language Models (LLMs) have demonstrated strong math reasoning abilities through Reinforcement Learning with Verifiable Rewards (RLVR), many advanced mathematical problems are proof-based, with no guaranteed way to determine the authenticity of a proof by simple answer matching. To enable automatic verification, a Reward Model (RM) capable of reliably evaluating full proof processes is required. In this work, we design a scalable data-construction pipeline that, with minimal human effort, leverages LLMs to generate a large quantity of high-quality "question-proof-check" triplet data. By systematically varying problem sources, generation methods, and model configurations, we create diverse problem-proof pairs spanning multiple difficulty levels, linguistic styles, and error types, subsequently filtered through hierarchical human review for label alignment. Utilizing these data, we train a proof-checking RM, incorporating additional process reward and token weight balance to stabilize the RL process. Our experiments validate the model's scalability and strong performance from multiple perspectives, including reward accuracy, generalization ability and test-time guidance, providing important practical recipes and tools for strengthening LLM mathematical capabilities.