Automated Multiple Mini Interview (MMI) Scoring
作者: Ryan Huynh, Frank Guerin, Alison Callwood
分类: cs.CL
发布日期: 2026-02-02
备注: 18 pages, 2 figures
💡 一句话要点
提出多智能体提示框架,提升大型语言模型在自动化多重迷你面试评分中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多重迷你面试 自动化评分 大型语言模型 多智能体系统 提示工程
📋 核心要点
- 人工评分软技能(如同理心)存在不一致和偏见,自动化评估面临挑战。
- 提出多智能体提示框架,分解评估过程,细化成绩单并进行标准评分。
- 实验表明,该方法优于微调基线,可靠性与人类专家相当,且具有通用性。
📝 摘要(中文)
在竞争激烈的选拔过程中,评估同理心、伦理判断和沟通等软技能至关重要,但人工评分往往不一致且存在偏见。虽然大型语言模型(LLM)改进了自动作文评分(AES),但我们发现,最先进的基于理由的微调方法难以处理多重迷你面试(MMI)的抽象、上下文依赖性,错过了候选人叙述中隐含的信号。我们引入了一个多智能体提示框架,将评估过程分解为成绩单细化和特定标准的评分。通过使用具有大型指令调整模型的3-shot上下文学习,我们的方法优于专门的微调基线(平均QWK 0.62 vs 0.32),并实现了与人类专家相当的可靠性。我们进一步证明了我们的框架在ASAP基准上的通用性,在那里它与特定领域的最新模型相媲美,而无需额外的训练。这些发现表明,对于复杂的、主观的推理任务,结构化提示工程可能为数据密集型微调提供一种可扩展的替代方案,从而改变LLM在自动评估中的应用方式。
🔬 方法详解
问题定义:论文旨在解决自动化多重迷你面试(MMI)评分中,现有基于大型语言模型(LLM)的微调方法难以捕捉候选人叙述中隐含信号的问题。现有方法在处理MMI的抽象性和上下文依赖性方面存在不足,导致评分不准确和可靠性低。
核心思路:论文的核心思路是将复杂的MMI评分任务分解为多个子任务,并利用多智能体协作的方式,分别处理成绩单细化和特定标准的评分。通过结构化的提示工程,引导LLM更好地理解和评估候选人的表现。这种分解和协作的方式旨在提高评分的准确性和可靠性。
技术框架:该框架包含两个主要阶段:成绩单细化和标准评分。在成绩单细化阶段,一个智能体负责清理和提炼候选人的叙述,提取关键信息。在标准评分阶段,多个智能体根据不同的评估标准(如同理心、伦理判断等)对细化后的成绩单进行评分。每个智能体都使用3-shot上下文学习,利用大型指令调整模型进行推理。最终,将各个智能体的评分结果进行汇总,得到最终的MMI评分。
关键创新:该论文的关键创新在于提出了多智能体提示框架,将复杂的MMI评分任务分解为多个子任务,并利用智能体之间的协作来提高评分的准确性和可靠性。与传统的微调方法相比,该框架不需要大量的训练数据,而是通过结构化的提示工程来引导LLM进行推理。这种方法更具可扩展性和通用性。
关键设计:该框架的关键设计包括:1) 使用3-shot上下文学习,为每个智能体提供少量示例,以指导其进行推理;2) 使用大型指令调整模型,提高智能体的推理能力;3) 将评估标准分解为多个维度,并为每个维度分配一个智能体,以提高评分的细粒度和准确性。具体的参数设置和网络结构信息未知。
🖼️ 关键图片

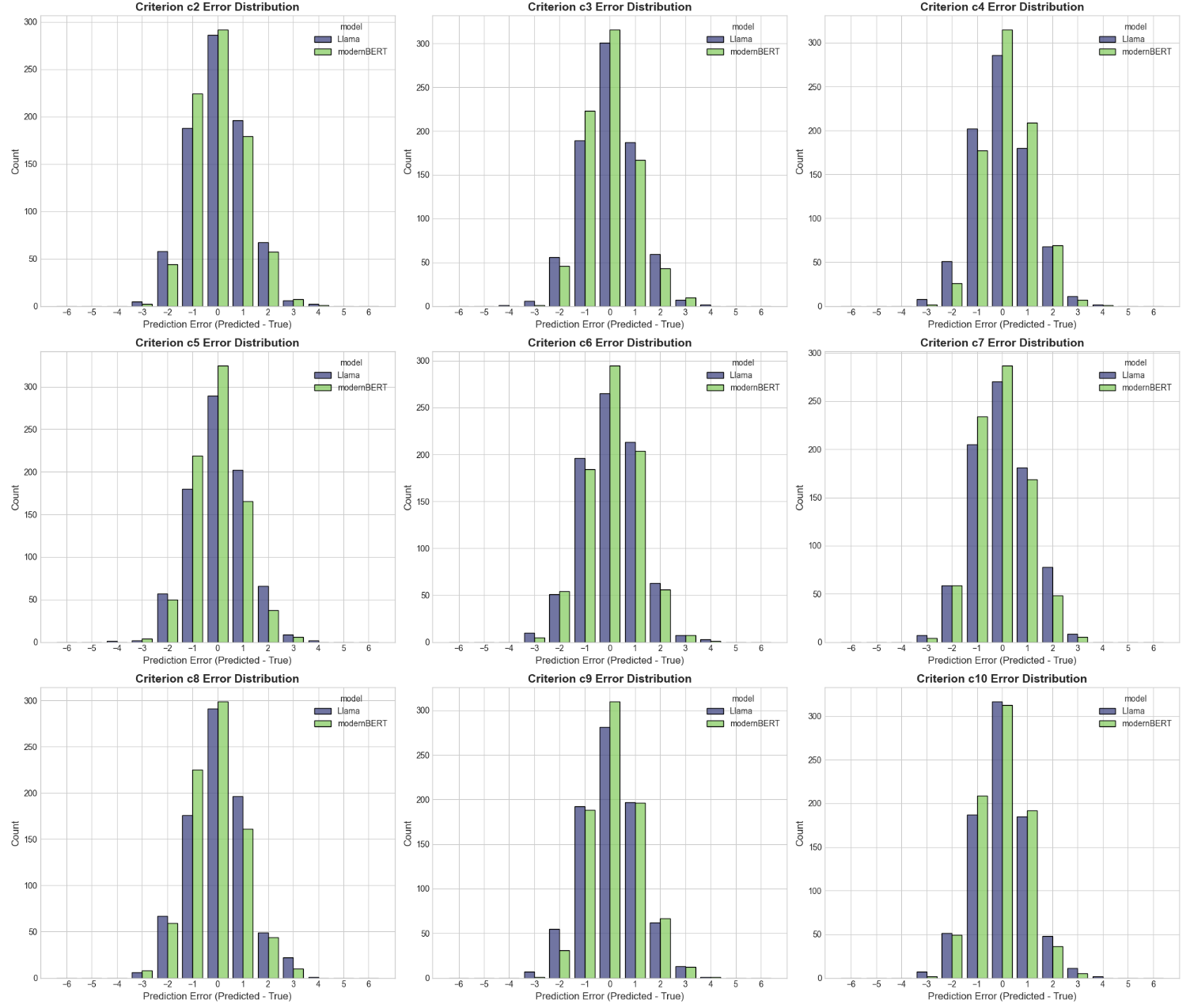
📊 实验亮点
实验结果表明,该多智能体提示框架在MMI评分任务中优于专门的微调基线(平均QWK 0.62 vs 0.32),并实现了与人类专家相当的可靠性。此外,该框架在ASAP基准上表现出色,与特定领域的最新模型相媲美,无需额外训练,证明了其通用性。
🎯 应用场景
该研究成果可应用于各种需要评估软技能的选拔场景,如医学院入学、招聘面试等。通过自动化MMI评分,可以提高评估效率、降低人工成本,并减少主观偏见。未来,该方法有望扩展到其他类型的复杂评估任务中,例如项目评审、绩效评估等。
📄 摘要(原文)
Assessing soft skills such as empathy, ethical judgment, and communication is essential in competitive selection processes, yet human scoring is often inconsistent and biased. While Large Language Models (LLMs) have improved Automated Essay Scoring (AES), we show that state-of-the-art rationale-based fine-tuning methods struggle with the abstract, context-dependent nature of Multiple Mini-Interviews (MMIs), missing the implicit signals embedded in candidate narratives. We introduce a multi-agent prompting framework that breaks down the evaluation process into transcript refinement and criterion-specific scoring. Using 3-shot in-context learning with a large instruct-tuned model, our approach outperforms specialised fine-tuned baselines (Avg QWK 0.62 vs 0.32) and achieves reliability comparable to human experts. We further demonstrate the generalisability of our framework on the ASAP benchmark, where it rivals domain-specific state-of-the-art models without additional training. These findings suggest that for complex, subjective reasoning tasks, structured prompt engineering may offer a scalable alternative to data-intensive fine-tuning, altering how LLMs can be applied to automated assessment.