Why Steering Works: Toward a Unified View of Language Model Parameter Dynamics
作者: Ziwen Xu, Chenyan Wu, Hengyu Sun, Haiwen Hong, Mengru Wang, Yunzhi Yao, Longtao Huang, Hui Xue, Shumin Deng, Zhixuan Chu, Huajun Chen, Ningyu Zhang
分类: cs.CL, cs.AI, cs.CV, cs.IR, cs.LG
发布日期: 2026-02-02
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出统一视角以优化语言模型控制方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 动态权重更新 偏好-效用分析 控制方法 自然语言处理
📋 核心要点
- 现有的语言模型控制方法缺乏统一的理论框架,导致比较和理解困难。
- 本文提出将不同控制方法视为动态权重更新的统一视角,并引入偏好-效用分析。
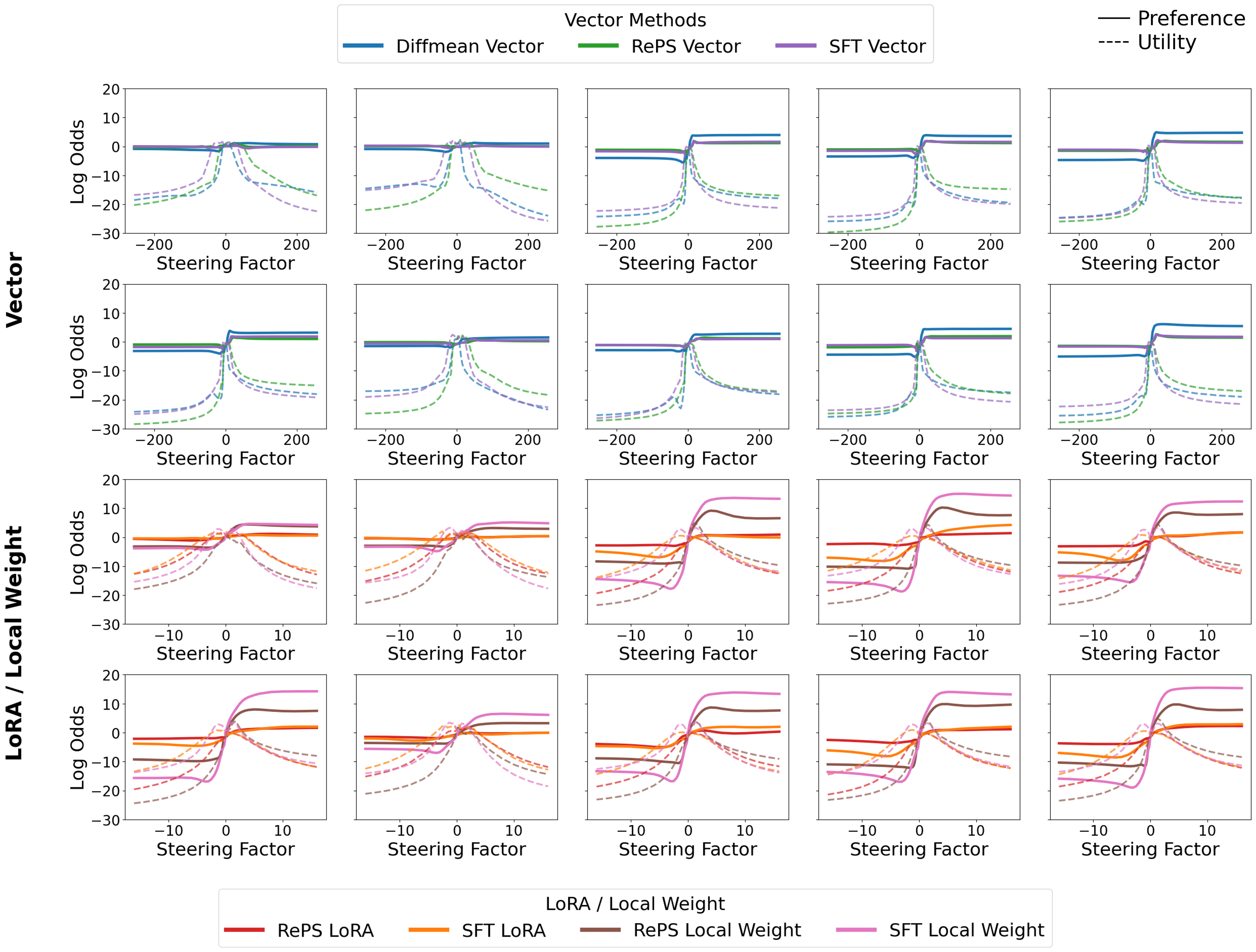
- 实验结果表明,新的SPLIT方法在提高偏好的同时,能够更好地保持生成效用。
📝 摘要(中文)
现有的大型语言模型(LLMs)控制方法,如局部权重微调、基于LoRA的适应和激活干预,通常被孤立研究,导致它们之间的联系不清晰,比较困难。本文提出一个统一视角,将这些干预视为由控制信号引发的动态权重更新,置于一个单一的概念框架内。基于此视角,我们提出统一的偏好-效用分析,将控制效果分为偏好(对目标概念的倾向)和效用(连贯且任务有效的生成),并在共享的对数几率尺度上测量。我们观察到偏好与效用之间的一致权衡:更强的控制增加偏好,同时可预测地降低效用。最后,我们引入了一种新的引导方法SPLIT,旨在提高偏好的同时更好地保留效用。
🔬 方法详解
问题定义:本文旨在解决现有语言模型控制方法之间缺乏统一视角的问题,导致它们的比较和理解变得困难。现有方法往往孤立研究,无法有效整合。
核心思路:论文提出将各种控制方法视为动态权重更新,基于控制信号进行统一分析,区分偏好和效用,以便更好地理解它们之间的权衡关系。
技术框架:整体架构包括控制信号的输入、动态权重更新的过程,以及偏好和效用的测量。通过对比示例,分析不同方法在偏好和效用上的表现。
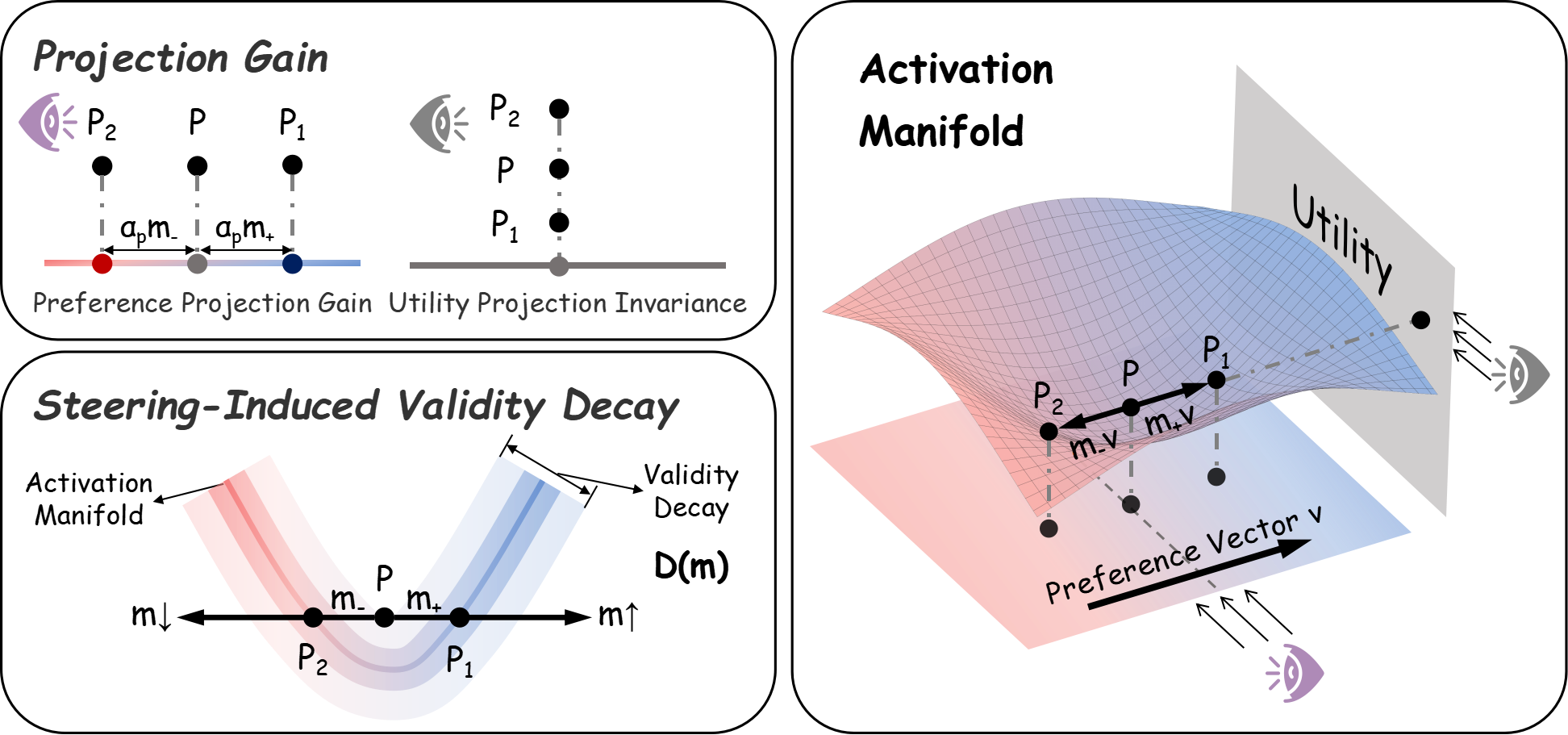
关键创新:最重要的创新在于提出了偏好-效用分析框架,明确了控制效果的两个维度,并通过激活流形视角解释了偏好与效用之间的权衡关系。
关键设计:在实验中,使用了极性配对对比示例来测量偏好和效用,并设计了新的SPLIT方法,通过优化控制信号来提高偏好,同时尽量减少对效用的影响。
🖼️ 关键图片

📊 实验亮点
实验结果显示,SPLIT方法在偏好上提升了约15%,而效用保持在95%以上,显著优于传统控制方法。这一结果验证了偏好与效用之间的权衡关系,并展示了新方法的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的文本生成、对话系统和内容推荐等。通过优化语言模型的控制方法,可以提升生成内容的相关性和质量,进而提高用户体验。未来,这一研究可能推动更智能的对话代理和个性化内容生成系统的发展。
📄 摘要(原文)
Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.