The Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
作者: Raphaël Sarfati, Eric Bigelow, Daniel Wurgaft, Jack Merullo, Atticus Geiger, Owen Lewis, Tom McGrath, Ekdeep Singh Lubana
分类: cs.CL
发布日期: 2026-02-02
💡 一句话要点
研究LLM信念的几何结构,提出场感知线性引导方法以提升干预效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 信念表示 几何引导 场感知引导 线性场探测
📋 核心要点
- 现有方法缺乏对LLM中信念如何编码、更新和干预的机制性理解,阻碍了对LLM行为的精确控制。
- 论文提出研究LLM在参数推断任务中的信念流形,并利用几何和场感知引导方法进行干预。
- 实验表明,相比线性引导,几何和场感知引导能更好地保持信念族,提升干预效果。
📝 摘要(中文)
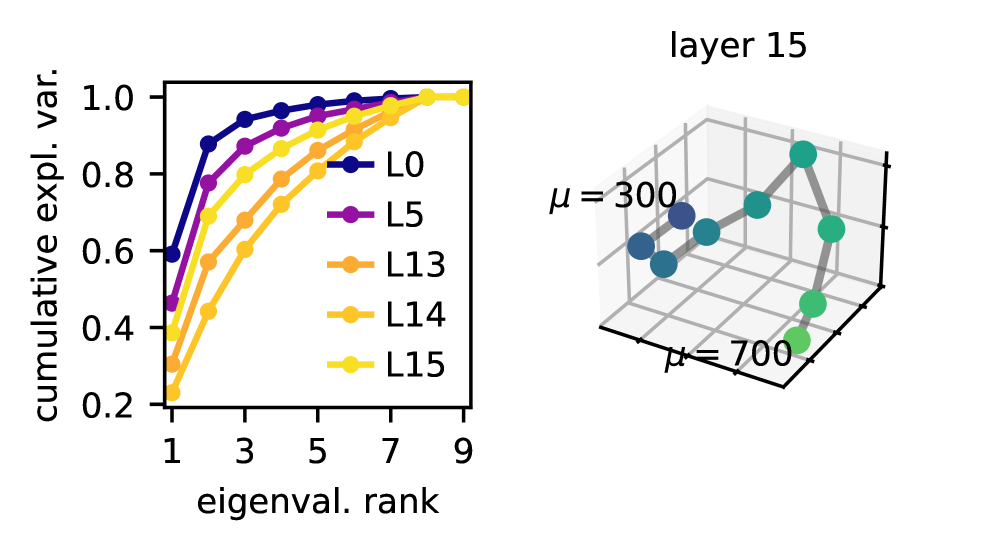
大型语言模型(LLM)表示提示条件下的信念(关于答案和声明的后验概率),但我们缺乏对这些信念如何在表征空间中编码、如何随新证据更新以及干预如何重塑它们的机制性解释。我们研究了一个受控环境,其中Llama-3.2通过隐式推断正态分布的参数(均值和标准差)来生成样本,而上下文中仅给出该分布的样本。我们发现,通过足够的上下文学习,这些参数的弯曲“信念流形”的表征会形成,并研究模型在分布突然变化时如何适应。虽然标准的线性引导通常会将模型推离流形,并导致耦合的、超出分布的偏移,但几何和场感知引导能更好地保持预期的信念族。我们的工作展示了线性场探测(LFP)的一个例子,作为一种简单的平铺数据流形并进行尊重底层几何结构的干预的方法。我们得出结论,丰富的结构自然地出现在LLM中,并且纯粹的线性概念表征通常是不充分的抽象。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中信念表示的机制性理解问题。具体来说,研究LLM如何编码提示条件下的信念(后验概率),如何根据新证据更新这些信念,以及如何通过干预来重塑它们。现有方法,如线性引导,往往无法有效控制LLM的信念,容易导致模型偏离预期分布,产生不可预测的行为。
核心思路:论文的核心思路是研究LLM在表征空间中形成的“信念流形”,并利用几何和场感知的方法进行干预。通过将信念表示视为流形上的点,可以更好地理解信念之间的关系以及干预对信念的影响。场感知引导则考虑了表征空间中的局部结构,避免了线性引导可能导致的“脱离流形”问题。
技术框架:论文的技术框架主要包括以下几个部分:1)构建一个受控的实验环境,让LLM(Llama-3.2)通过上下文学习来推断正态分布的参数(均值和标准差)。2)分析LLM在表征空间中形成的信念流形,观察其几何结构。3)提出几何和场感知引导方法,用于干预LLM的信念。4)通过实验比较不同引导方法的效果,评估其对信念保持和干预效果的影响。
关键创新:论文最重要的技术创新点在于提出了几何和场感知引导方法。与传统的线性引导方法不同,该方法考虑了表征空间中的局部几何结构,能够更好地保持信念族,避免模型偏离预期分布。此外,论文还提出了线性场探测(LFP)方法,用于平铺数据流形,从而实现尊重底层几何结构的干预。
关键设计:在实验设计上,论文选择了一个可控的参数推断任务,使得可以精确地分析LLM的信念表示。在引导方法的设计上,论文利用了表征空间中的梯度信息,构建了场感知的引导向量。此外,论文还仔细评估了不同引导方法对模型输出分布的影响,并使用了合适的指标来衡量信念保持和干预效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,相比于标准的线性引导,几何和场感知引导能够更好地保持LLM的信念族,避免模型偏离预期分布。具体来说,场感知引导在参数推断任务中,能够更准确地控制LLM对均值和标准差的估计,并减少了超出分布的偏移。线性场探测(LFP)作为一种平铺数据流形的方法,也展现了其在干预LLM信念方面的潜力。
🎯 应用场景
该研究成果可应用于提升LLM的可控性和可靠性,例如在对话系统中,可以利用该方法控制LLM的回答风格和内容,避免生成不准确或有害的信息。在知识推理领域,可以引导LLM进行更准确的推理,提高知识利用效率。此外,该研究也有助于理解LLM内部表征的形成机制,为开发更强大的LLM提供理论基础。
📄 摘要(原文)
Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.