Cross-Lingual Stability of LLM Judges Under Controlled Generation: Evidence from Finno-Ugric Languages
作者: Isaac Chung, Linda Freienthal
分类: cs.CL
发布日期: 2026-02-02
备注: First Workshop on Multilingual Multicultural Evaluation, co-located with EACL 2026
🔗 代码/项目: GITHUB
💡 一句话要点
研究表明,在芬兰-乌戈尔语系中,LLM评判器跨语言稳定性不足,尤其在语用判断上。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言评估 大型语言模型 LLM评判器 芬兰-乌戈尔语系 评估稳定性
📋 核心要点
- 现有跨语言LLM评估方法难以区分模型性能差异和评估方法本身的不稳定性。
- 本研究通过控制生成条件,在芬兰-乌戈尔语系中考察LLM评判器的跨语言稳定性。
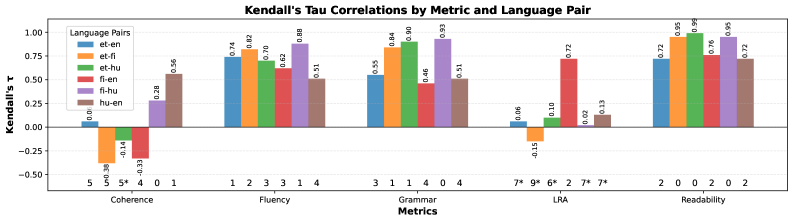
- 实验发现,表面指标稳定,但语用判断在不同语言间存在排名反转,表明零样本评判器迁移不可靠。
📝 摘要(中文)
大型语言模型(LLM)的跨语言评估通常混淆了两种差异来源:模型性能的真正差异和评估的不稳定性。本研究通过在不同目标语言中保持生成条件不变来研究评估的可靠性。我们使用在爱沙尼亚语、芬兰语和匈牙利语中以相同参数生成的合成客户支持对话,测试自动指标和LLM评判器评分是否能在这些形态丰富的相关芬兰-乌戈尔语系语言中产生稳定的模型排名。以少量爱沙尼亚语母语人士的标注作为参考点,我们发现存在系统性的排名不稳定性:表面指标(词汇多样性、表面和语义相似性)保持了跨语言稳定性,但语用判断(连贯性、指令遵循)表现出排名反转和接近于零的相关性。由于生成是受控的,这些不一致反映了评判器评分在不同语言中的行为差异,而不是真正的模型差异。这种受控设计提供了一种诊断探针:在相同生成条件下未能保持稳定性的评估方法表明在部署前存在迁移失败。我们的研究结果表明,对于形态丰富的语言中的篇章级评估,零样本评判器迁移是不可靠的,这促使人们针对特定的人工基线进行特定语言的校准。我们发布了受控生成协议、合成数据和评估框架,以便在不同语系中进行复制,代码见https://github.com/isaac-chung/cross-lingual-stability-judges。
🔬 方法详解
问题定义:现有LLM跨语言评估方法难以区分模型性能的真正差异和评估方法本身的不稳定性。现有方法在评估跨语言LLM时,无法确定观察到的性能差异是由于模型本身在不同语言上的表现不同,还是由于评估指标或评判器在不同语言上的行为不一致。这使得跨语言LLM的可靠评估变得困难。
核心思路:本研究的核心思路是通过控制生成条件,消除模型生成差异带来的影响,从而专注于评估指标或LLM评判器在不同语言上的稳定性。具体来说,使用相同的生成参数在不同语言上生成合成数据,然后使用不同的评估方法对这些数据进行评估,观察评估结果在不同语言之间是否一致。如果评估结果在不同语言之间存在显著差异,则表明该评估方法存在跨语言不稳定性。
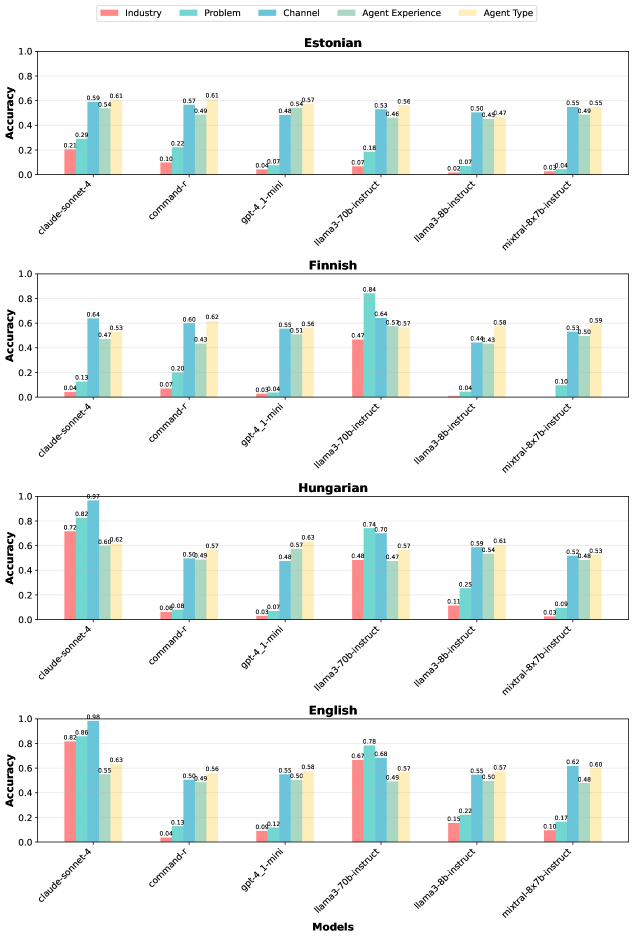
技术框架:本研究的技术框架主要包括以下几个步骤: 1. 数据生成:使用相同的生成参数在爱沙尼亚语、芬兰语和匈牙利语中生成合成客户支持对话。 2. 评估指标选择:选择一系列自动指标(如词汇多样性、表面和语义相似性)和LLM评判器作为评估方法。 3. 评估:使用选定的评估方法对生成的合成数据进行评估,得到模型在不同语言上的排名。 4. 稳定性分析:分析模型排名在不同语言之间的一致性,评估评估方法的跨语言稳定性。 5. 人工评估:使用爱沙尼亚语母语人士的标注作为参考点,验证自动评估结果的可靠性。
关键创新:本研究的关键创新在于其受控的实验设计。通过控制生成条件,消除了模型生成差异带来的影响,从而能够更准确地评估评估方法本身的跨语言稳定性。这种受控设计提供了一种诊断探针,可以用于识别在部署前存在迁移失败的评估方法。
关键设计:本研究的关键设计包括: 1. 合成数据生成:使用相同的生成参数,确保不同语言的数据在内容和结构上尽可能一致。 2. 评估指标选择:选择既有表面指标,也有需要理解上下文的语用指标,以全面评估评估方法的稳定性。 3. 稳定性分析方法:使用排名相关性等指标来量化评估方法在不同语言之间的稳定性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,表面指标(如词汇多样性、表面和语义相似性)在不同语言之间保持了较好的稳定性,而语用判断(如连贯性、指令遵循)则表现出排名反转和接近于零的相关性。这表明零样本评判器迁移对于形态丰富的语言中的篇章级评估是不可靠的。
🎯 应用场景
该研究成果可应用于跨语言LLM的开发和评估。通过识别和避免使用不稳定的评估方法,可以更准确地评估LLM在不同语言上的性能,从而提高跨语言LLM的质量和可靠性。此外,该研究也为开发更具跨语言适应性的评估方法提供了指导。
📄 摘要(原文)
Cross-lingual evaluation of large language models (LLMs) typically conflates two sources of variance: genuine model performance differences and measurement instability. We investigate evaluation reliability by holding generation conditions constant while varying target language. Using synthetic customer-support dialogues generated with identical parameters across Estonian, Finnish, and Hungarian, we test whether automatic metrics and LLM-as-a-judge scoring produce stable model rankings across these morphologically rich, related Finno-Ugric languages. With a small set of Estonian native speaker annotations as a reference point, we find systematic ranking instabilities: surface-level metrics (lexical diversity, surface and semantic similarity) maintain cross-language stability, but pragmatic judgments (coherence, instruction-following) exhibit rank inversions and near-zero correlations. Because generation is controlled, these inconsistencies reflect how judge scoring behaves differently across languages rather than true model differences. This controlled design provides a diagnostic probe: evaluation methods that fail to maintain stability under identical generation conditions signal transfer failure before deployment. Our findings suggest that zero-shot judge transfer is unreliable for discourse-level assessment in morphologically rich languages, motivating language-specific calibration against targeted human baselines. We release our controlled generation protocol, synthetic data, and evaluation framework to enable replication across language families at https://github.com/isaac-chung/cross-lingual-stability-judges.