OpenSeal: Good, Fast, and Cheap Construction of an Open-Source Southeast Asian LLM via Parallel Data
作者: Tan Sang Nguyen, Muhammad Reza Qorib, Hwee Tou Ng
分类: cs.CL, cs.AI
发布日期: 2026-02-02
💡 一句话要点
OpenSeal:通过并行数据高效构建开源东南亚语言大模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 东南亚语言 开源模型 并行数据 持续预训练
📋 核心要点
- 现有东南亚语言大模型缺乏真正的开源性,阻碍了对其内部机制的深入理解和改进。
- 论文提出利用并行数据进行持续预训练,以高效扩展LLM到东南亚语言,强调数据质量。
- 实验表明,仅使用并行数据即可构建性能媲美现有模型的开源东南亚LLM OpenSeal。
📝 摘要(中文)
大型语言模型(LLMs)已被证明是各种自然语言处理(NLP)应用的有效工具。尽管许多LLM是多语言的,但大多数仍然以英语为中心,并且在低资源语言上的表现不佳。最近,已经开发了一些以东南亚为重点的LLM,但没有一个是真正开源的,因为它们没有公开其训练数据。真正开源的模型对于透明度至关重要,并且能够更深入、更精确地理解LLM的内部结构和开发,包括偏差、泛化和多语言性。受到最近的研究进展的启发,这些进展表明并行数据在提高多语言性能方面的有效性,我们进行了受控和全面的实验,以研究并行数据在LLM持续预训练中的有效性。我们的研究结果表明,仅使用并行数据是扩展LLM到新语言的最有效方法。仅使用347亿个token的并行数据和在8个NVIDIA H200 GPU上花费的180小时,我们构建了OpenSeal,这是第一个真正开源的东南亚LLM,其性能可与现有类似规模的模型相媲美。
🔬 方法详解
问题定义:现有东南亚语言大模型虽然在不断涌现,但缺乏真正的开源性,即没有公开训练数据。这使得研究人员难以深入理解模型的偏差、泛化能力和多语言特性,也限制了社区对模型的改进和定制。因此,如何构建一个真正开源且性能良好的东南亚语言大模型是一个亟待解决的问题。
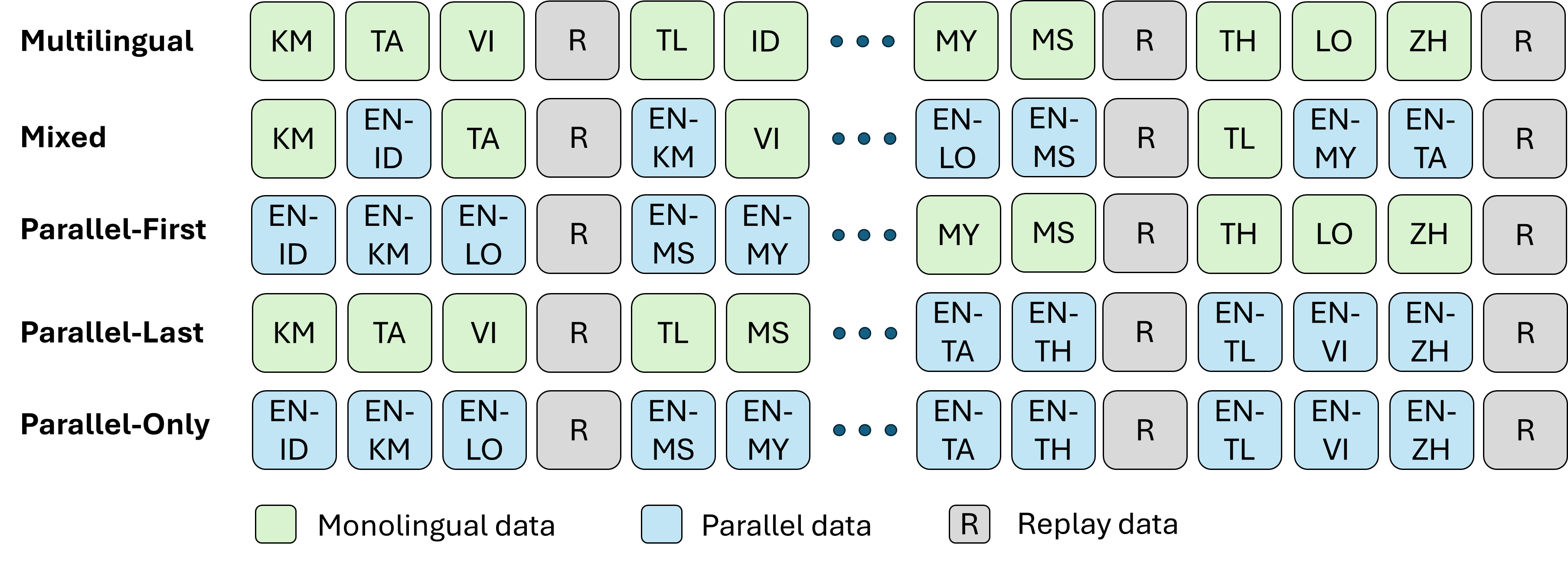
核心思路:论文的核心思路是利用高质量的并行数据进行持续预训练。作者认为,相比于混合多种数据源,仅使用并行数据能够更有效地将LLM扩展到新的语言。这种方法能够避免引入噪声数据,并更好地保留模型的原有能力。
技术框架:OpenSeal的构建流程主要包括以下几个阶段:1) 选择一个现有的LLM作为基础模型;2) 收集和清洗高质量的东南亚语言并行数据;3) 使用并行数据对基础模型进行持续预训练;4) 对预训练后的模型进行评估和微调。整个流程旨在高效地构建一个开源且性能良好的东南亚语言大模型。
关键创新:论文的关键创新在于强调了并行数据在多语言LLM构建中的重要性,并证明了仅使用并行数据即可实现媲美现有模型的性能。此外,OpenSeal的开源性也为东南亚语言NLP研究提供了宝贵的资源。
关键设计:论文中使用了347亿个token的并行数据,并在8个NVIDIA H200 GPU上进行了180小时的训练。具体的训练参数和超参数设置未在摘要中详细说明,属于未知信息。损失函数和网络结构沿用了基础模型的设计,未进行显著修改。
🖼️ 关键图片

📊 实验亮点
OpenSeal仅使用347亿个token的并行数据和180小时的GPU训练,便构建了性能可与现有类似规模模型相媲美的东南亚语言LLM。这一结果突显了并行数据在多语言LLM构建中的高效性。具体的性能指标和对比基线未在摘要中详细说明,属于未知信息。
🎯 应用场景
OpenSeal的潜在应用领域包括机器翻译、跨语言信息检索、多语言文本摘要、以及面向东南亚市场的智能客服和聊天机器人等。该研究的开源特性将促进东南亚语言NLP技术的发展,并为相关应用提供更可靠的基础模型。未来,OpenSeal可以作为进一步研究和改进的起点,推动东南亚地区人工智能的普及和应用。
📄 摘要(原文)
Large language models (LLMs) have proven to be effective tools for a wide range of natural language processing (NLP) applications. Although many LLMs are multilingual, most remain English-centric and perform poorly on low-resource languages. Recently, several Southeast Asia-focused LLMs have been developed, but none are truly open source, as they do not publicly disclose their training data. Truly open-source models are important for transparency and for enabling a deeper and more precise understanding of LLM internals and development, including biases, generalization, and multilinguality. Motivated by recent advances demonstrating the effectiveness of parallel data in improving multilingual performance, we conduct controlled and comprehensive experiments to study the effectiveness of parallel data in continual pretraining of LLMs. Our findings show that using only parallel data is the most effective way to extend an LLM to new languages. Using just 34.7B tokens of parallel data and 180 hours on 8x NVIDIA H200 GPUs, we built OpenSeal, the first truly open Southeast Asian LLM that rivals the performance of existing models of similar size.