Evaluating Metalinguistic Knowledge in Large Language Models across the World's Languages
作者: Tjaša Arčon, Matej Klemen, Marko Robnik-Šikonja, Kaja Dobrovoljc
分类: cs.CL
发布日期: 2026-02-02
💡 一句话要点
构建多语言元语言知识评估基准,揭示大语言模型在不同语言上的结构理解能力差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 元语言知识 多语言评估 语言结构 低资源语言
📋 核心要点
- 现有语言模型评估侧重于语言使用,忽略了对语言结构知识的评估,尤其缺乏对元语言知识的考察。
- 本文构建了一个多语言元语言知识评估基准,旨在评估LLM在不同语言上的结构理解能力,填补了现有评估的空白。
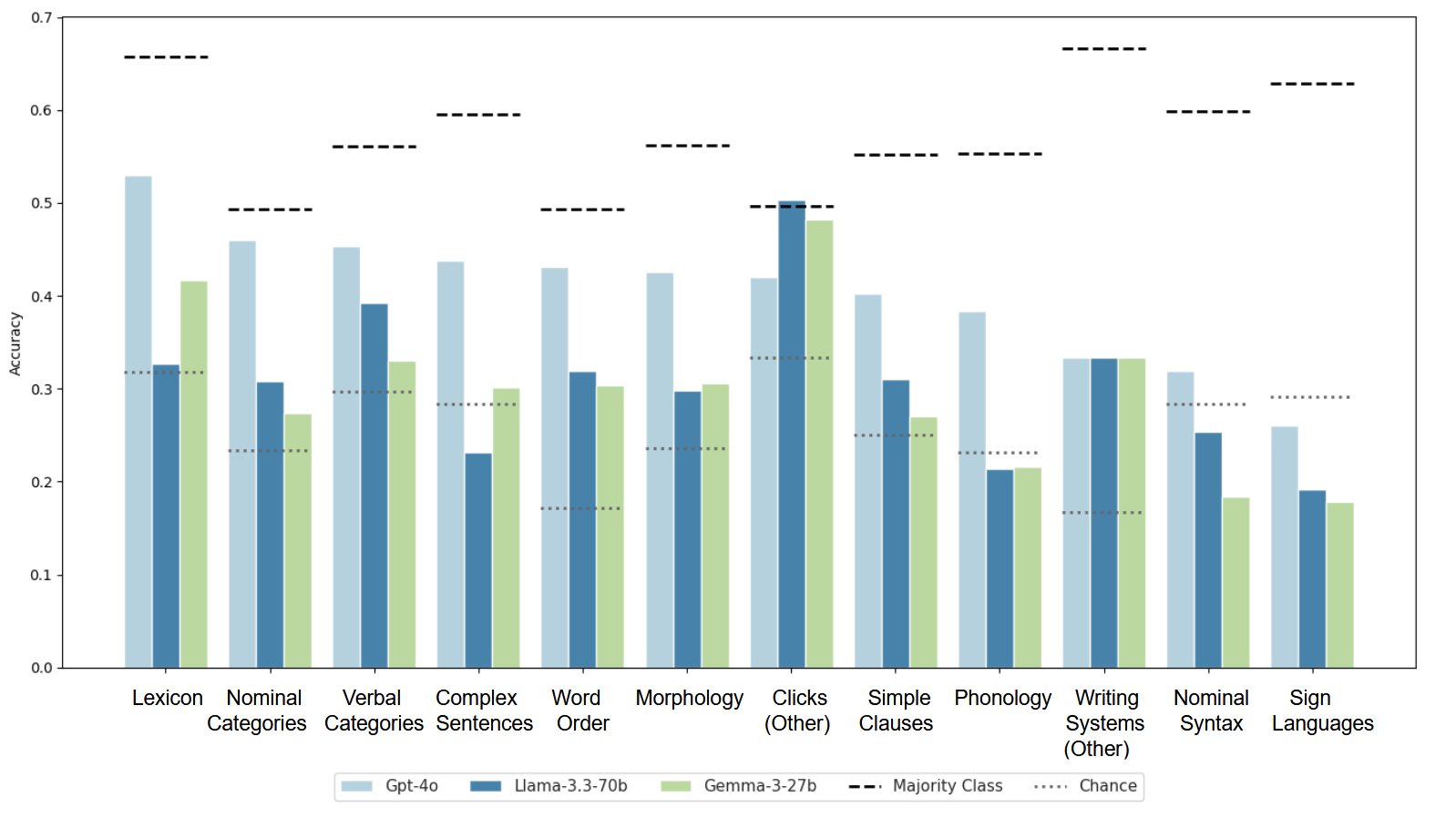
- 实验结果表明,LLM的元语言知识有限,且性能受数据可用性影响显著,低资源语言表现较差。
📝 摘要(中文)
大型语言模型(LLMs)通常在语言使用任务上进行评估,但它们对语言结构的知识仍然知之甚少。现有的语言基准通常侧重于狭窄的现象,强调高资源语言,并且很少评估元语言知识——即对语言结构的显式推理,而不是语言使用。本文使用准确率和宏F1值,以及多数类和随机基线,分析了LLM的整体性能,并考察了语言领域和语言相关因素的变化。结果表明,当前LLM的元语言知识有限:GPT-4o表现最佳,但仅达到中等准确率(0.367),而开源模型则落后。所有模型都表现高于随机水平,但未能超过多数类基线,表明它们捕获了跨语言模式,但缺乏细粒度的语法区分。性能因语言领域而异,词汇特征表现出最高的准确率,而语音特征表现出最低的准确率,部分反映了在线可见性的差异。在语言层面,准确率与数字语言状态密切相关:数字存在和资源可用性较高的语言被评估得更准确,而低资源语言的表现则明显较差。对预测因素的分析证实,与地理、谱系或社会语言学因素相比,与资源相关的指标(维基百科规模、语料库可用性)是更有效的准确率预测指标。总而言之,这些结果表明,LLM的元语言知识是零散的,并且受数据可用性的影响,而不是跨世界语言的通用语法能力。本文发布了基准测试作为开源数据集,以支持系统评估,并鼓励未来LLM中更大的全球语言多样性。
🔬 方法详解
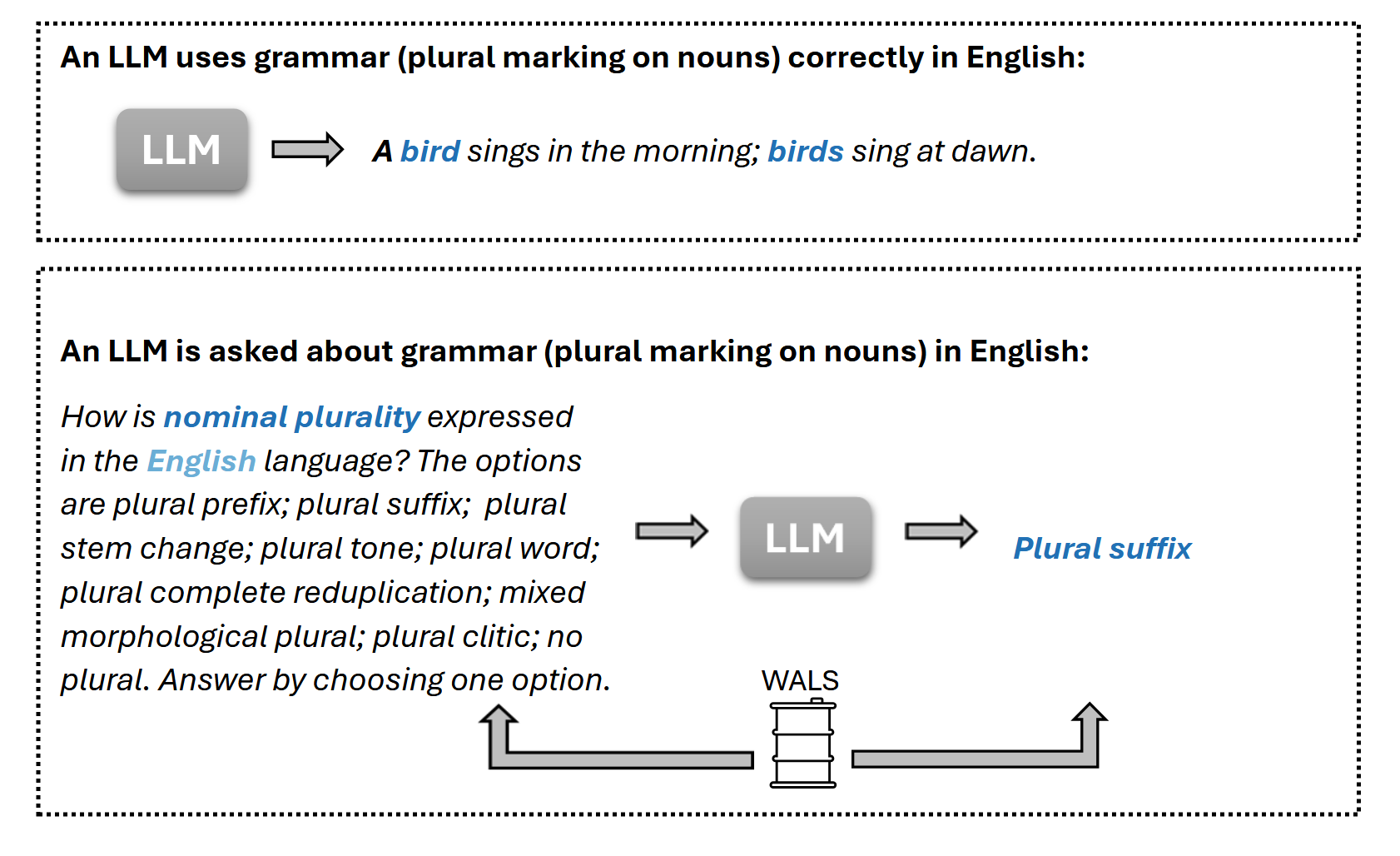
问题定义:现有的大语言模型评估主要集中在语言使用能力上,例如文本生成、机器翻译等,而忽略了对模型语言结构知识的评估。特别是,缺乏对元语言知识(即对语言结构进行显式推理的能力)的评估。现有的语言基准测试通常只关注少数几种高资源语言,并且评估的语言现象范围狭窄,无法全面反映模型在不同语言上的语言学理解能力。
核心思路:本文的核心思路是构建一个多语言的元语言知识评估基准,该基准覆盖多种语言和多种语言学领域,旨在系统地评估大语言模型在不同语言上的语言结构理解能力。通过分析模型在不同语言和语言学领域上的表现差异,可以深入了解模型的语言学知识的局限性和潜在的偏见。
技术框架:该研究构建了一个包含多种语言的元语言知识评估数据集。该数据集涵盖了词汇、形态、句法、语义和语音等多个语言学领域。研究人员使用该数据集评估了多个大语言模型,包括GPT-4o和一些开源模型。评估指标包括准确率和宏F1值。此外,研究人员还分析了模型在不同语言和语言学领域上的表现差异,并探讨了影响模型性能的因素。
关键创新:该研究的关键创新在于构建了一个多语言的元语言知识评估基准,该基准覆盖了多种语言和多种语言学领域,可以更全面地评估大语言模型在不同语言上的语言结构理解能力。此外,该研究还深入分析了模型在不同语言和语言学领域上的表现差异,并探讨了影响模型性能的因素,为未来的模型改进提供了有价值的 insights。
关键设计:该基准测试的关键设计包括:1) 覆盖多种语言,包括高资源和低资源语言;2) 涵盖多个语言学领域,包括词汇、形态、句法、语义和语音;3) 使用明确的元语言知识问题,要求模型进行显式推理;4) 提供详细的评估指标,包括准确率和宏F1值;5) 分析模型在不同语言和语言学领域上的表现差异,并探讨影响模型性能的因素。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o在元语言知识评估中表现最佳,但准确率仅为0.367,开源模型表现更差。所有模型均优于随机基线,但未能超过多数类基线,表明模型缺乏细粒度的语法区分能力。性能在不同语言领域存在差异,词汇特征准确率最高,语音特征最低。语言资源丰富的语言评估结果更准确,低资源语言表现较差。
🎯 应用场景
该研究成果可应用于大语言模型的评估和改进,帮助开发者更好地了解模型的语言学知识局限性,并针对性地进行改进。此外,该基准测试可以促进对低资源语言的支持,提高大语言模型在不同语言上的通用性。该研究还有助于推动自然语言处理领域的公平性和包容性。
📄 摘要(原文)
Large language models (LLMs) are routinely evaluated on language use tasks, yet their knowledge of linguistic structure remains poorly understood. Existing linguistic benchmarks typically focus on narrow phenomena, emphasize high-resource languages, and rarely evaluate metalinguistic knowledge-explicit reasoning about language structure rather than language use. Using accuracy and macro F1, together with majority-class and chance baselines, we analyse overall performance and examine variation by linguistic domains and language-related factors. Our results show that metalinguistic knowledge in current LLMs is limited: GPT-4o performs best but achieves only moderate accuracy (0.367), while open-source models lag behind. All models perform above chance but fail to outperform the majority-class baseline, suggesting they capture cross-linguistic patterns but lack fine-grained grammatical distinctions. Performance varies across linguistic domains, with lexical features showing the highest accuracy and phonological features among the lowest, partially reflecting differences in online visibility. At the language level, accuracy shows a strong association with digital language status: languages with higher digital presence and resource availability are evaluated more accurately, while low-resource languages show substantially lower performance. Analyses of predictive factors confirm that resource-related indicators (Wikipedia size, corpus availability) are more informative predictors of accuracy than geographical, genealogical, or sociolinguistic factors. Together, these results suggest that LLMs' metalinguistic knowledge is fragmented and shaped by data availability rather than generalizable grammatical competence across the world's languages. We release our benchmark as an open-source dataset to support systematic evaluation and encourage greater global linguistic diversity in future LLMs.