AR-MAP: Are Autoregressive Large Language Models Implicit Teachers for Diffusion Large Language Models?
作者: Liang Lin, Feng Xiong, Zengbin Wang, Kun Wang, Junhao Dong, Xuecai Hu, Yong Wang, Xiangxiang Chu
分类: cs.CL
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
AR-MAP:利用自回归大语言模型作为扩散大语言模型的隐式教师,实现高效偏好对齐。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 自回归模型 偏好对齐 迁移学习 知识蒸馏
📋 核心要点
- 扩散语言模型偏好对齐面临高方差和计算开销的挑战,现有方法难以有效利用已对齐的自回归模型知识。
- AR-MAP框架通过权重缩放,将偏好对齐的自回归模型作为隐式教师,迁移知识到扩散模型,避免直接对齐的困难。
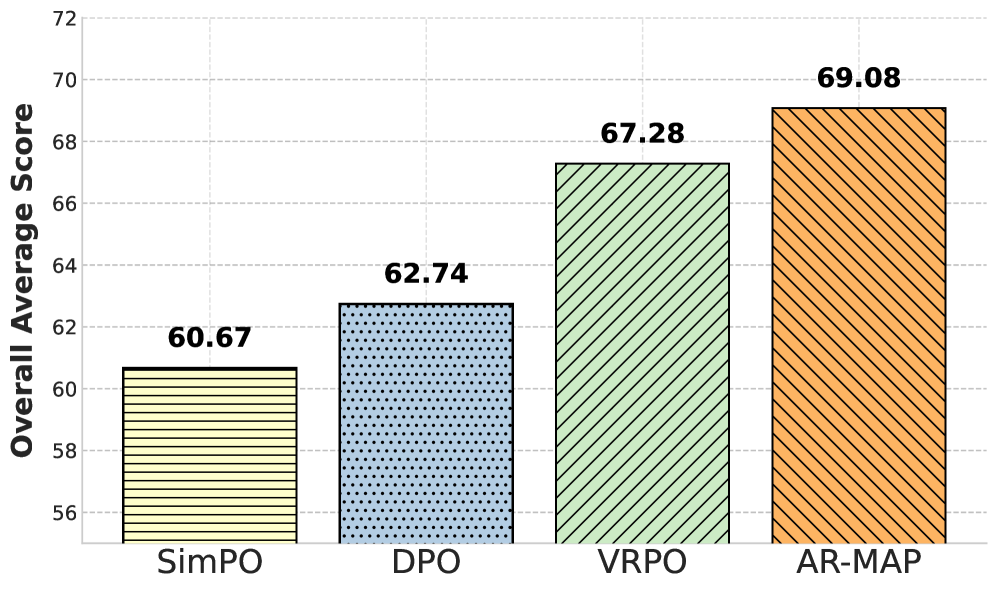
- 实验表明,AR-MAP在多个偏好对齐任务上表现优异,平均得分达到69.08%,优于或媲美现有扩散模型对齐方法。
📝 摘要(中文)
扩散大语言模型(DLLMs)作为一种强大的自回归模型的替代方案,能够跨多个位置并行生成token。然而,由于基于证据下界(ELBO)的似然估计引入的高方差,DLLMs的偏好对齐仍然具有挑战性。本文提出了AR-MAP,一种新颖的迁移学习框架,它利用偏好对齐的自回归LLMs (AR-LLMs)作为DLLM对齐的隐式教师。我们发现,DLLMs可以通过简单的权重缩放有效地吸收来自AR-LLMs的对齐知识,利用这些不同的生成范式之间共享的架构结构。至关重要的是,我们的方法规避了直接DLLM对齐的高方差和计算开销。在各种偏好对齐任务中的综合实验表明,AR-MAP与现有的DLLM专用对齐方法相比,实现了有竞争力的或更优越的性能,在所有任务和模型中实现了69.08%的平均得分。我们的代码可在https://github.com/AMAP-ML/AR-MAP获得。
🔬 方法详解
问题定义:扩散大语言模型(DLLMs)虽然具有并行生成token的优势,但在偏好对齐方面面临挑战。直接对DLLM进行偏好对齐通常基于证据下界(ELBO)的似然估计,这导致训练过程中的高方差和巨大的计算开销。此外,如何有效利用已经对齐的自回归大语言模型(AR-LLMs)的知识,也是一个亟待解决的问题。
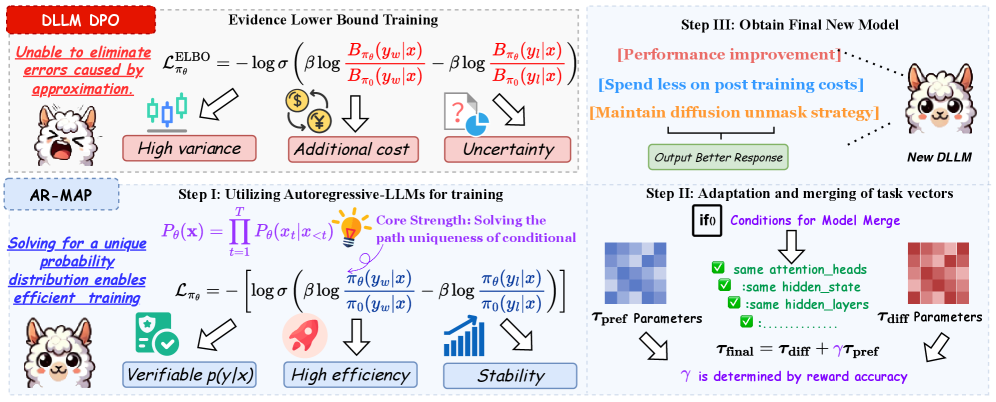
核心思路:AR-MAP的核心思想是将偏好对齐的AR-LLMs作为DLLMs的隐式教师。通过观察到AR-LLMs和DLLMs之间存在共享的架构结构,AR-MAP提出可以通过简单的权重缩放操作,将AR-LLMs的对齐知识迁移到DLLMs。这种方法避免了直接对DLLMs进行偏好对齐,从而降低了训练的方差和计算成本。
技术框架:AR-MAP框架主要包含以下几个步骤:1) 首先,使用偏好对齐的AR-LLM作为教师模型。2) 然后,将AR-LLM的权重通过缩放操作迁移到DLLM。3) 最后,在DLLM上进行微调,以进一步优化其性能。整个框架的关键在于权重缩放操作,它允许DLLM有效地吸收来自AR-LLM的对齐知识。
关键创新:AR-MAP最重要的技术创新点在于它提出了一种利用AR-LLMs作为DLLMs隐式教师的迁移学习方法。与传统的直接对DLLMs进行偏好对齐的方法相比,AR-MAP避免了高方差和高计算成本的问题。此外,AR-MAP还揭示了AR-LLMs和DLLMs之间存在共享的架构结构,这为知识迁移提供了理论基础。
关键设计:AR-MAP的关键设计在于权重缩放操作。具体来说,对于DLLM的每一层,AR-MAP将其权重初始化为AR-LLM对应层权重的缩放版本。缩放因子是一个可学习的参数,可以通过微调来优化。此外,AR-MAP还使用了标准的交叉熵损失函数进行微调,以进一步提高DLLM的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AR-MAP在多个偏好对齐任务上取得了显著的性能提升。例如,在某些任务上,AR-MAP的平均得分达到了69.08%,超过了现有的DLLM专用对齐方法。此外,AR-MAP还能够显著降低训练的计算成本,使其成为一种高效且有效的偏好对齐方法。
🎯 应用场景
AR-MAP框架可广泛应用于各种需要偏好对齐的文本生成任务,例如对话系统、文本摘要、机器翻译等。该方法能够有效提升扩散语言模型的生成质量和对齐程度,降低训练成本,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他生成模型和模态,例如图像生成和视频生成。
📄 摘要(原文)
Diffusion Large Language Models (DLLMs) have emerged as a powerful alternative to autoregressive models, enabling parallel token generation across multiple positions. However, preference alignment of DLLMs remains challenging due to high variance introduced by Evidence Lower Bound (ELBO)-based likelihood estimation. In this work, we propose AR-MAP, a novel transfer learning framework that leverages preference-aligned autoregressive LLMs (AR-LLMs) as implicit teachers for DLLM alignment. We reveal that DLLMs can effectively absorb alignment knowledge from AR-LLMs through simple weight scaling, exploiting the shared architectural structure between these divergent generation paradigms. Crucially, our approach circumvents the high variance and computational overhead of direct DLLM alignment and comprehensive experiments across diverse preference alignment tasks demonstrate that AR-MAP achieves competitive or superior performance compared to existing DLLM-specific alignment methods, achieving 69.08\% average score across all tasks and models. Our Code is available at https://github.com/AMAP-ML/AR-MAP.