Focus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
作者: Lingkun Long, Yushi Huang, Shihao Bai, Ruihao Gong, Jun Zhang, Ao Zhou, Jianlei Yang
分类: cs.CL
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出Focus-dLLM,通过置信度引导的上下文聚焦加速长文本扩散LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 长文本处理 注意力机制 稀疏注意力 推理加速
📋 核心要点
- 现有稀疏注意力方法难以有效加速长文本扩散LLM推理,因为在扩散过程中,未解码token的重要性难以估计。
- Focus-dLLM利用相邻扩散步骤间token置信度的相关性,预测未掩码区域,并进行sink感知的注意力剪枝。
- 实验表明,Focus-dLLM在32K上下文长度下实现了超过29倍的无损加速,显著提升了推理效率。
📝 摘要(中文)
扩散大语言模型(dLLMs)在非自回归解码范式中展现了强大的长文本处理能力。然而,双向全注意力机制带来的巨大计算成本限制了推理效率。虽然稀疏注意力很有前景,但现有方法仍然无效。这是因为需要估计尚未解码的token的注意力重要性,而在扩散过程中,未掩码的token位置是未知的。本文提出了Focus-dLLM,一种新颖的、无需训练的注意力稀疏化框架,专为准确高效的长文本dLLM推理而设计。基于相邻步骤之间token置信度高度相关的发现,我们首先设计了一个过去置信度引导的指示器来预测未掩码区域。在此基础上,我们提出了一种感知sink的剪枝策略,以准确估计和移除冗余的注意力计算,同时保留具有高度影响力的注意力sink。为了进一步减少开销,该策略跨层重用已识别的sink位置,利用观察到的跨层一致性。实验结果表明,我们的方法在32K上下文长度下提供了超过29倍的无损加速。代码已公开。
🔬 方法详解
问题定义:论文旨在解决长文本扩散LLM(dLLM)推理效率低下的问题。dLLM虽然具有强大的长文本处理能力,但其双向全注意力机制导致计算成本巨大,限制了实际应用。现有的稀疏注意力方法在dLLM中效果不佳,主要原因是扩散过程的特殊性:需要预测尚未解码的token的注意力重要性,而这些token的位置在扩散过程中是动态变化的,难以准确估计。
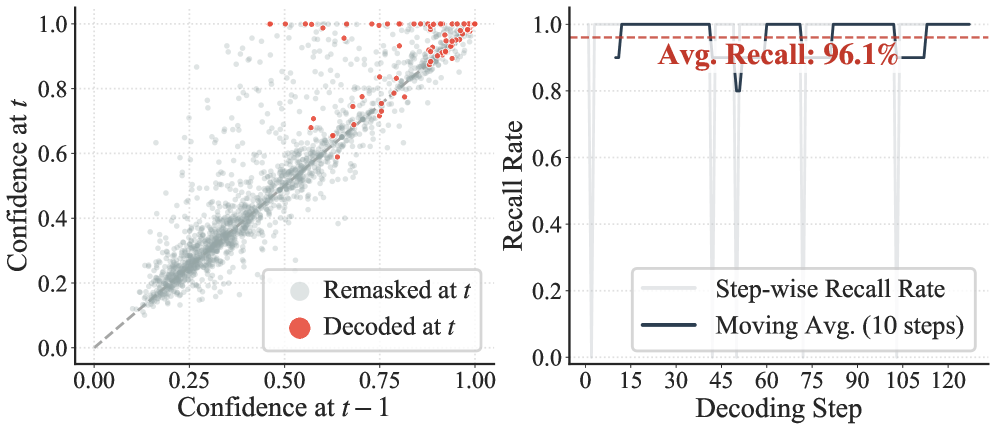
核心思路:论文的核心思路是利用扩散过程中相邻步骤之间token置信度的高度相关性。作者观察到,一个token在当前扩散步骤中的置信度可以有效地预测其在下一个步骤中的重要性。基于此,可以通过历史置信度信息来指导注意力机制的稀疏化,从而减少不必要的计算。
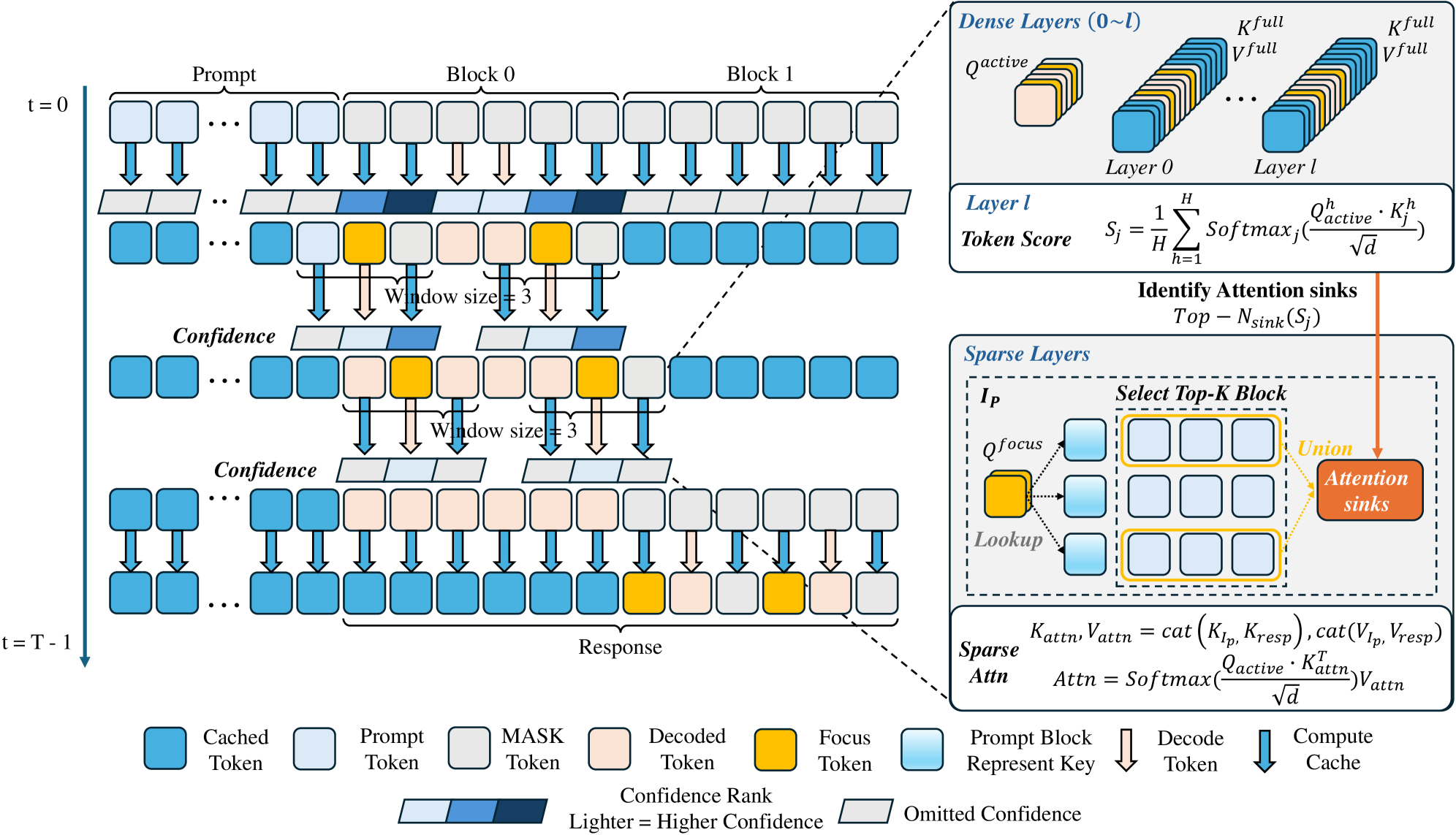
技术框架:Focus-dLLM框架主要包含两个阶段:(1) 过去置信度引导的指示器:该模块利用前一步骤的token置信度来预测当前步骤中需要保留的token区域。具体来说,通过一个简单的函数(例如阈值函数)将置信度转化为一个指示器,用于标识重要的token。(2) Sink感知的剪枝策略:该模块基于预测的token区域,对注意力矩阵进行剪枝。为了进一步提高效率,该策略还考虑了注意力sink的位置,即那些接收大量注意力的token。通过保留这些sink,可以确保模型性能不会受到太大影响。此外,该策略还跨层重用sink位置,利用了跨层一致性。
关键创新:Focus-dLLM的关键创新在于其无需训练的注意力稀疏化方法,该方法充分利用了扩散过程的特性,即相邻步骤之间token置信度的高度相关性。与需要额外训练或微调的稀疏注意力方法不同,Focus-dLLM可以直接应用于现有的dLLM模型,无需修改模型结构或参数。此外,sink感知的剪枝策略进一步提高了效率,同时保证了模型性能。
关键设计:在过去置信度引导的指示器中,一个关键的设计是选择合适的置信度度量方式以及阈值。论文中可能使用了softmax输出的概率值作为置信度,并根据经验或实验选择合适的阈值。在sink感知的剪枝策略中,如何准确识别和保留sink位置也是一个关键设计。论文可能采用了一些启发式方法或简单的统计方法来识别sink,例如选择接收最多注意力的前k个token作为sink。跨层重用sink位置的设计旨在减少计算开销,但同时也需要考虑不同层之间sink位置的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Focus-dLLM在32K上下文长度下实现了超过29倍的无损加速。这意味着在相同的硬件条件下,使用Focus-dLLM可以更快地生成长文本,或者在相同的推理时间内,可以处理更长的文本。这种显著的性能提升使得dLLM在处理超长文本任务时更具竞争力。
🎯 应用场景
Focus-dLLM可应用于各种需要处理长文本的场景,例如长篇文档摘要、机器翻译、代码生成等。通过显著提升长文本扩散LLM的推理效率,该方法有望推动dLLM在实际应用中的普及,并降低计算成本。未来,该方法还可以扩展到其他类型的生成模型,例如图像生成模型。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM