Out of the Memory Barrier: A Highly Memory Efficient Training System for LLMs with Million-Token Contexts
作者: Wenhao Li, Daohai Yu, Gen Luo, Yuxin Zhang, Fei Chao, Rongrong Ji, Yifan Wu, Jiaxin Liu, Ziyang Gong, Zimu Liao
分类: cs.CL
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
OOMB:一种高内存效率的LLM训练系统,支持百万token上下文
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文LLM 内存优化 激活值重计算 分页内存管理 稀疏注意力 chunk-recurrent训练 GPU训练
📋 核心要点
- 现有长上下文LLM训练面临的主要挑战是激活值导致的GPU内存开销随序列长度线性增长,限制了模型训练的上下文长度。
- OOMB通过chunk-recurrent训练框架和on-the-fly激活值重计算,将激活值的内存占用降低到常数级别,有效缓解了内存瓶颈。
- 实验表明,OOMB显著降低了长上下文训练的内存开销,使得在单个GPU上训练具有百万token上下文的LLM成为可能。
📝 摘要(中文)
本文提出了一种名为OOMB的高内存效率训练系统,旨在解决长上下文LLM训练中GPU内存开销过大的问题。该问题主要源于激活值的内存占用随序列长度线性增长。OOMB采用chunk-recurrent训练框架,结合on-the-fly激活值重计算,将激活值的内存占用维持在常数级别(O(1)),并将瓶颈转移到KV缓存。为了管理KV缓存,OOMB集成了一系列协同优化技术:包括用于KV缓存及其梯度的分页内存管理器以消除碎片,异步CPU卸载以隐藏数据传输延迟,以及页级稀疏注意力以降低计算复杂度和通信开销。这些技术的协同作用带来了卓越的效率。实验结果表明,对于Qwen2.5-7B,每增加10K token的上下文,端到端训练内存开销仅增加10MB。这使得在单个H200 GPU上训练具有4M token上下文的Qwen2.5-7B成为可能,而使用上下文并行则需要大型集群。这项工作代表了长上下文LLM训练在资源效率方面的重大进步。源代码可在https://github.com/wenhaoli-xmu/OOMB获取。
🔬 方法详解
问题定义:长上下文大型语言模型(LLM)的训练受到GPU内存的严重限制,尤其是在处理长序列时。激活值的内存占用随序列长度线性增长,成为主要的瓶颈。现有的上下文并行等方法虽然可以缓解这一问题,但需要大量的计算资源和复杂的分布式训练设置。
核心思路:OOMB的核心思路是通过chunk-recurrent训练框架和on-the-fly激活值重计算,将激活值的内存占用从线性复杂度降低到常数复杂度。这意味着激活值的内存占用不再随序列长度增加而显著增加,从而显著降低了GPU内存需求。
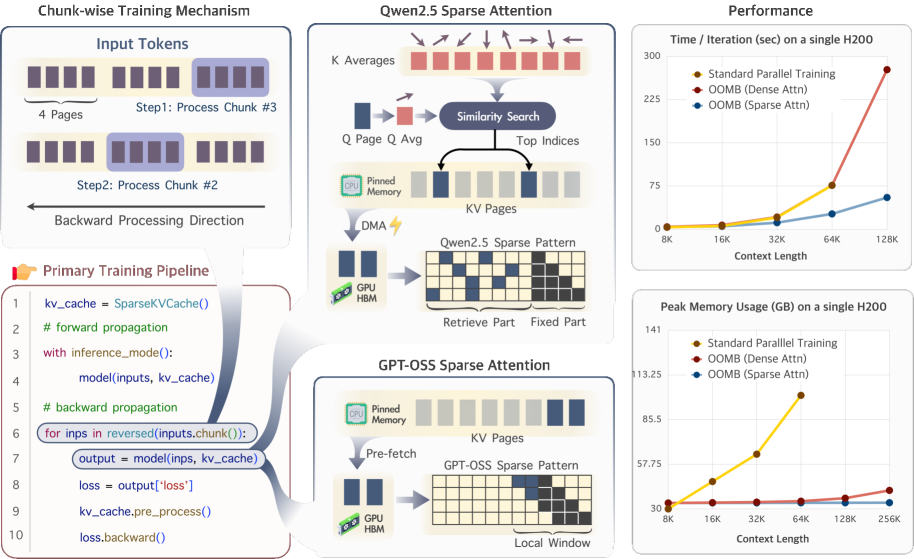
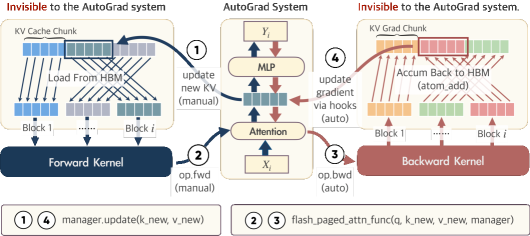
技术框架:OOMB的整体框架包括以下几个关键模块:1) Chunk-Recurrent训练:将长序列分成多个chunk进行处理。2) On-the-fly激活值重计算:在需要时重新计算激活值,而不是存储所有激活值。3) 分页内存管理器:用于KV缓存及其梯度,消除内存碎片。4) 异步CPU卸载:将部分数据卸载到CPU,并隐藏数据传输延迟。5) 页级稀疏注意力:减少计算复杂度和通信开销。
关键创新:OOMB的关键创新在于将chunk-recurrent训练与on-the-fly激活值重计算相结合,实现了激活值内存占用的常数复杂度。此外,分页内存管理器和页级稀疏注意力进一步优化了KV缓存的管理和计算效率。与现有方法相比,OOMB无需复杂的分布式训练设置,即可在单个GPU上训练具有长上下文的LLM。
关键设计:OOMB的关键设计包括:1) Chunk大小的选择:需要根据GPU内存和计算资源进行调整。2) 激活值重计算的策略:需要权衡计算成本和内存占用。3) 分页内存管理器的页大小:需要根据KV缓存的大小和访问模式进行优化。4) 页级稀疏注意力的稀疏模式:需要根据模型的结构和任务进行选择。
🖼️ 关键图片

📊 实验亮点
OOMB在Qwen2.5-7B模型上的实验结果表明,每增加10K token的上下文,端到端训练内存开销仅增加10MB。这使得在单个H200 GPU上训练具有4M token上下文的Qwen2.5-7B成为可能,而传统的上下文并行方法需要大型GPU集群。这一结果突显了OOMB在降低长上下文LLM训练内存开销方面的显著优势。
🎯 应用场景
OOMB的潜在应用领域包括:处理长文档、对话历史建模、基因组序列分析等需要长上下文信息的任务。该研究的实际价值在于降低了长上下文LLM训练的资源需求,使得更多研究者和开发者能够在有限的计算资源下训练和部署长上下文模型。未来,OOMB可以进一步扩展到其他类型的模型和任务,并与其他优化技术相结合,以实现更高的效率。
📄 摘要(原文)
Training Large Language Models (LLMs) on long contexts is severely constrained by prohibitive GPU memory overhead, not training time. The primary culprits are the activations, whose memory footprints scale linearly with sequence length. We introduce OOMB, a highly memory-efficient training system that directly confronts this barrier. Our approach employs a chunk-recurrent training framework with on-the-fly activation recomputation, which maintains a constant activation memory footprint (O(1)) and shifts the primary bottleneck to the growing KV cache. To manage the KV cache, OOMB integrates a suite of synergistic optimizations: a paged memory manager for both the KV cache and its gradients to eliminate fragmentation, asynchronous CPU offloading to hide data transfer latency, and page-level sparse attention to reduce both computational complexity and communication overhead. The synergy of these techniques yields exceptional efficiency. Our empirical results show that for every additional 10K tokens of context, the end-to-end training memory overhead increases by a mere 10MB for Qwen2.5-7B. This allows training Qwen2.5-7B with a 4M-token context on a single H200 GPU, a feat that would otherwise require a large cluster using context parallelism. This work represents a substantial advance in resource efficiency for long-context LLM training. The source code is available at https://github.com/wenhaoli-xmu/OOMB.