Data Distribution Matters: A Data-Centric Perspective on Context Compression for Large Language Model
作者: Kangtao Lv, Jiwei Tang, Langming Liu, Haibin Chen, Weidong Zhang, Shilei Liu, Yongwei Wang, Yujin Yuan, Wenbo Su, Bo Zheng
分类: cs.CL
发布日期: 2026-02-02
备注: 15 pages,6 figures
💡 一句话要点
从数据分布角度出发,研究数据分布对大语言模型上下文压缩质量的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 上下文压缩 数据分布 信息熵 自编码器
📋 核心要点
- 现有上下文压缩方法主要关注模型侧优化,忽略了数据分布对压缩质量的潜在影响。
- 本文从数据中心视角出发,研究输入数据和模型内在数据分布对上下文压缩质量的影响。
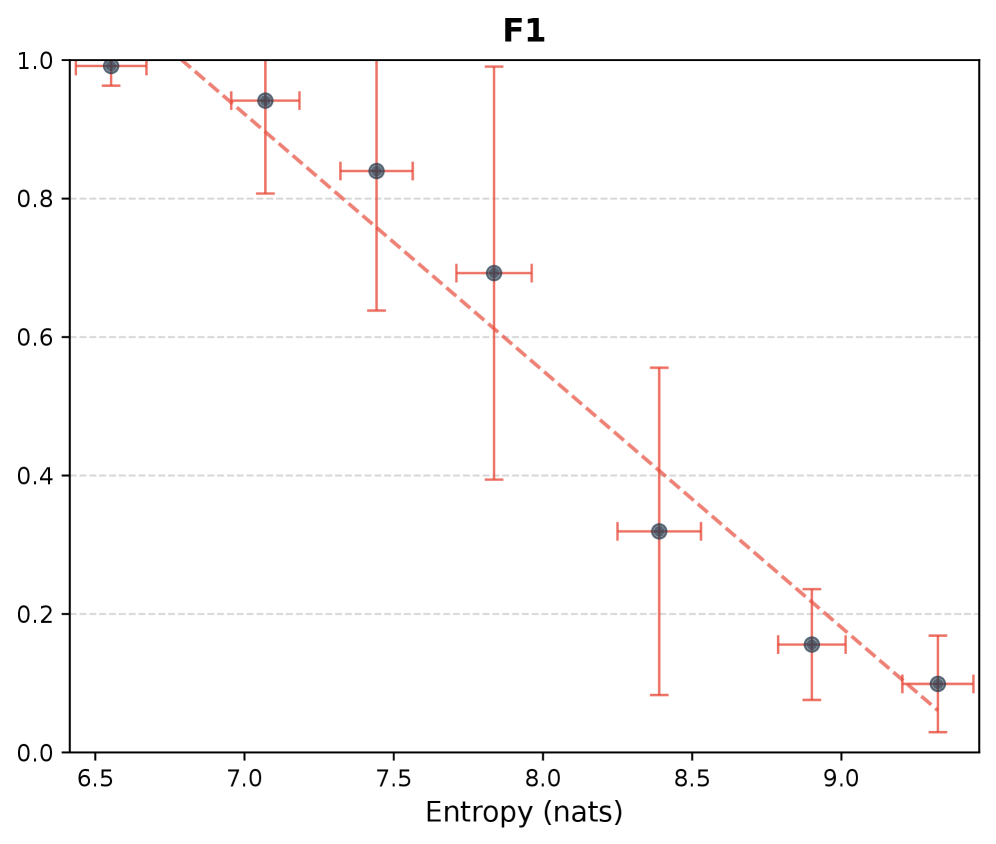
- 实验表明输入熵与压缩质量负相关,编码器-解码器内在数据差异会降低压缩增益,并提出优化指南。
📝 摘要(中文)
长文本场景下大语言模型的部署受到计算效率和信息冗余的限制。虽然上下文压缩技术已被广泛应用于解决这些问题,但现有研究主要集中在模型层面的改进,而忽略了数据分布本身对压缩质量的影响。本文首次从数据中心视角系统地研究了数据分布如何影响压缩质量,包括输入数据和内在数据(即模型内部的预训练知识)两个维度。我们使用基于自编码器的框架评估压缩表示的语义完整性。实验结果表明:(1)编码器测量的输入熵与压缩质量负相关,而在冻结解码器设置下,解码器测量的熵没有显著关系;(2)编码器和解码器的内在数据之间的差距显著降低了压缩增益,且难以缓解。基于这些发现,我们进一步提出了优化压缩增益的实用指南。
🔬 方法详解
问题定义:现有的大语言模型上下文压缩方法主要集中在模型结构和算法的优化上,忽略了数据本身特性对压缩效果的影响。具体来说,不同的输入数据分布(例如,信息熵的高低)以及模型预训练知识的分布(编码器和解码器之间的差异)如何影响压缩质量,缺乏系统的研究和量化分析。现有方法没有充分利用数据本身的特性来指导压缩策略的设计。
核心思路:本文的核心思路是从数据分布的角度出发,将数据分布作为影响上下文压缩质量的重要因素进行研究。通过分析输入数据的熵以及编码器和解码器内在知识的差异,来理解数据特性如何影响压缩效果。基于这些理解,可以设计更有效的数据驱动的压缩策略,从而提升压缩性能。
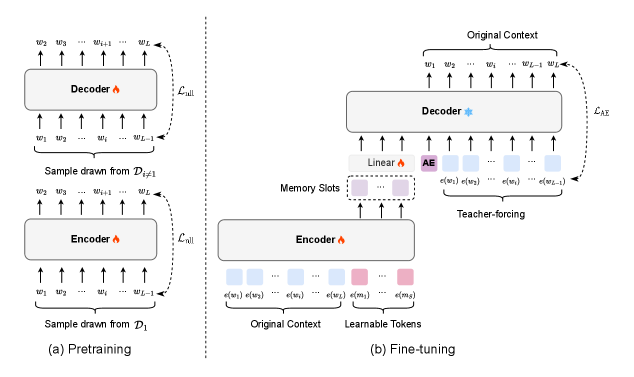
技术框架:本文采用基于自编码器的框架来评估压缩表示的语义完整性。该框架包含以下主要模块:1) 编码器:负责将输入上下文压缩成低维表示。2) 解码器:负责从低维表示重建原始上下文。3) 熵测量模块:用于测量输入数据和解码器输出的熵,以量化数据分布的特性。4) 语义完整性评估模块:通过比较原始上下文和重建上下文的语义相似度,来评估压缩表示的质量。
关键创新:本文最重要的创新点在于首次将数据分布的视角引入到大语言模型上下文压缩的研究中。通过量化输入数据的熵以及编码器和解码器内在知识的差异,揭示了数据特性对压缩质量的显著影响。这为未来设计更有效的数据驱动的压缩策略提供了新的思路。
关键设计:本文的关键设计包括:1) 使用自编码器框架来评估压缩质量,保证了评估的客观性和可重复性。2) 通过测量输入熵和解码器输出熵,量化了数据分布的特性。3) 通过比较编码器和解码器的内在数据,评估了模型预训练知识对压缩的影响。4) 实验中,冻结解码器参数,以隔离输入数据分布的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,编码器测量的输入熵与压缩质量负相关,即输入数据的信息量越大,压缩效果越差。此外,编码器和解码器的内在数据之间的差距会显著降低压缩增益。例如,当编码器和解码器的预训练数据分布差异较大时,压缩性能会明显下降。这些发现为优化上下文压缩策略提供了重要的指导。
🎯 应用场景
该研究成果可应用于各种需要处理长文本的大语言模型应用场景,例如长文档摘要、问答系统、代码生成等。通过优化数据分布,可以提高上下文压缩的效率和质量,从而降低计算成本,提升用户体验。未来的研究可以进一步探索如何根据数据分布动态调整压缩策略,实现更智能的上下文压缩。
📄 摘要(原文)
The deployment of Large Language Models (LLMs) in long-context scenarios is hindered by computational inefficiency and significant information redundancy. Although recent advancements have widely adopted context compression to address these challenges, existing research only focus on model-side improvements, the impact of the data distribution itself on context compression remains largely unexplored. To bridge this gap, we are the first to adopt a data-centric perspective to systematically investigate how data distribution impacts compression quality, including two dimensions: input data and intrinsic data (i.e., the model's internal pretrained knowledge). We evaluate the semantic integrity of compressed representations using an autoencoder-based framework to systematically investigate it. Our experimental results reveal that: (1) encoder-measured input entropy negatively correlates with compression quality, while decoder-measured entropy shows no significant relationship under a frozen-decoder setting; and (2) the gap between intrinsic data of the encoder and decoder significantly diminishes compression gains, which is hard to mitigate. Based on these findings, we further present practical guidelines to optimize compression gains.