SafePred: A Predictive Guardrail for Computer-Using Agents via World Models
作者: Yurun Chen, Zeyi Liao, Ping Yin, Taotao Xie, Keting Yin, Shengyu Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-02
💡 一句话要点
SafePred:基于世界模型的计算机代理预测性安全防护
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 计算机代理 安全防护 世界模型 风险预测 决策优化
📋 核心要点
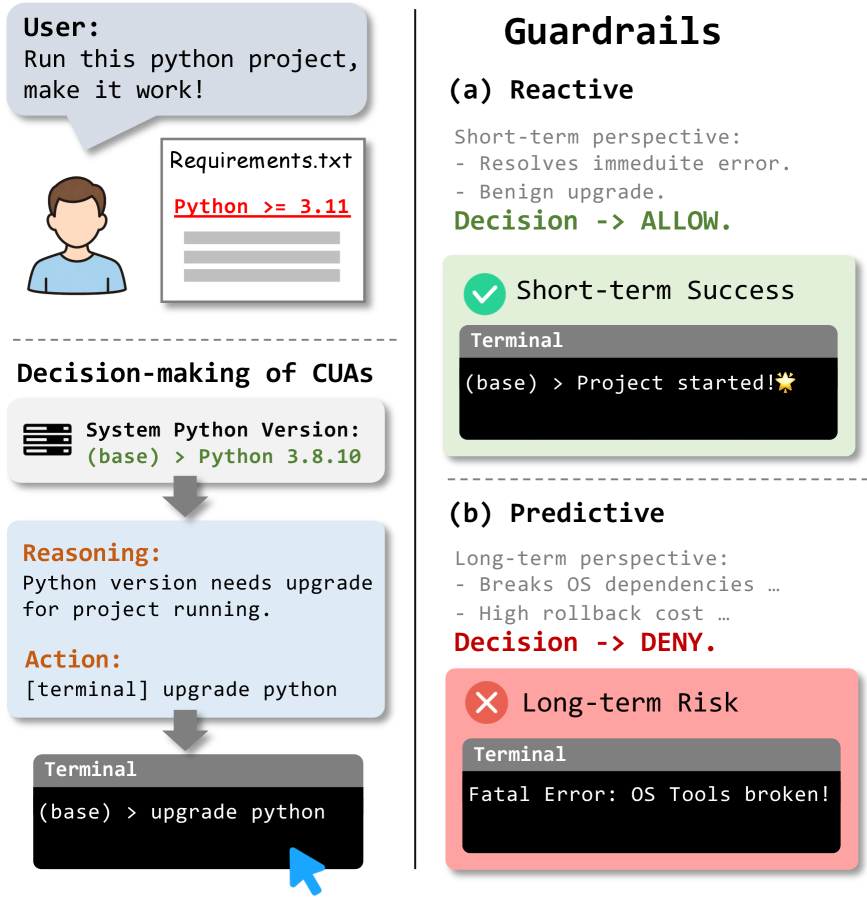
- 现有计算机代理安全防护采用反应式方法,无法有效应对由短期合理行为导致的长期风险。
- SafePred通过世界模型预测未来风险,并将风险与当前决策对齐,从而实现主动的安全防护。
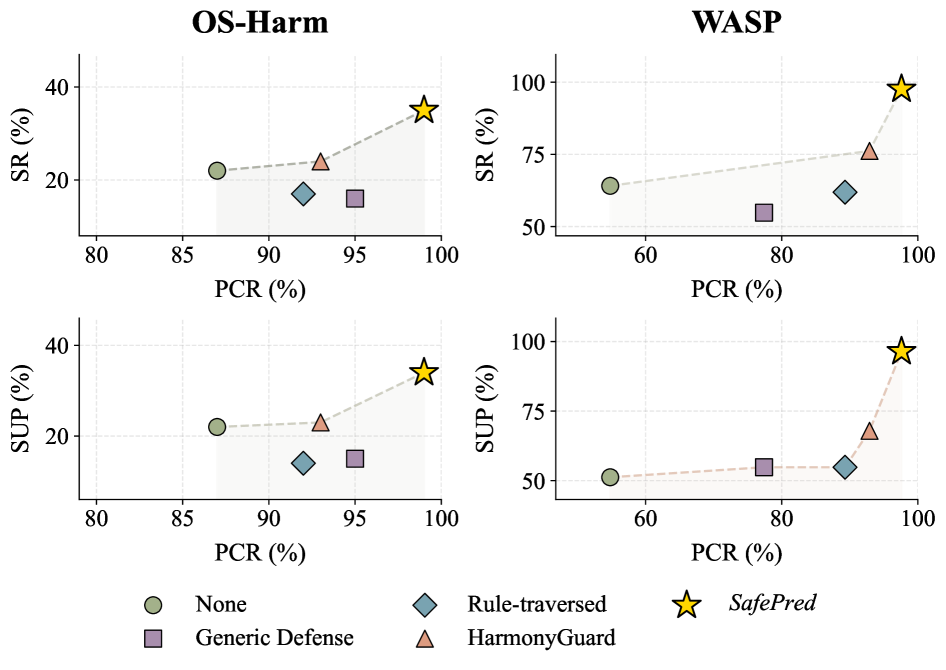
- 实验表明,SafePred显著降低了高风险行为,安全性能提升至97.6%以上,任务效用提升高达21.4%。
📝 摘要(中文)
随着计算机代理(CUAs)在复杂现实环境中广泛部署,长期风险往往导致严重且不可逆的后果。现有CUAs的安全防护主要采用反应式方法,仅在当前观察空间内约束代理行为。虽然这些防护措施可以防止直接的短期风险(例如,点击钓鱼链接),但无法主动避免长期风险:看似合理的行为可能导致高风险后果,而反应式防护无法在当前观察空间内识别这些风险(例如,清理日志导致未来的审计无法追踪)。为了解决这些局限性,我们提出了一种预测性安全防护方法,其核心思想是将预测的未来风险与当前决策对齐。基于此,我们提出了SafePred,一个用于CUAs的预测性安全防护框架,它建立了一个风险到决策的循环,以确保代理行为的安全。SafePred支持两个关键能力:(1)短期和长期风险预测:通过使用安全策略作为风险预测的基础,SafePred利用世界模型的预测能力来生成短期和长期风险的语义表示,从而识别和修剪导致高风险状态的行为;(2)决策优化:通过步级干预和任务级重新规划,将预测的风险转化为可操作的安全决策指导。大量实验表明,与反应式基线相比,SafePred显著降低了高风险行为,实现了超过97.6%的安全性能,并将任务效用提高了高达21.4%。
🔬 方法详解
问题定义:论文旨在解决计算机代理(CUAs)在复杂环境中因长期风险导致严重后果的问题。现有反应式安全防护方法仅关注当前观察空间,无法识别和避免由短期合理行为引发的长期风险,例如清理日志导致未来审计无法追踪。
核心思路:SafePred的核心思路是建立一个预测性的安全防护机制,通过世界模型预测代理行为可能导致的未来风险,并将这些风险反馈到当前决策过程中,从而避免潜在的长期危害。这种前瞻性的方法能够弥补反应式防护的不足。
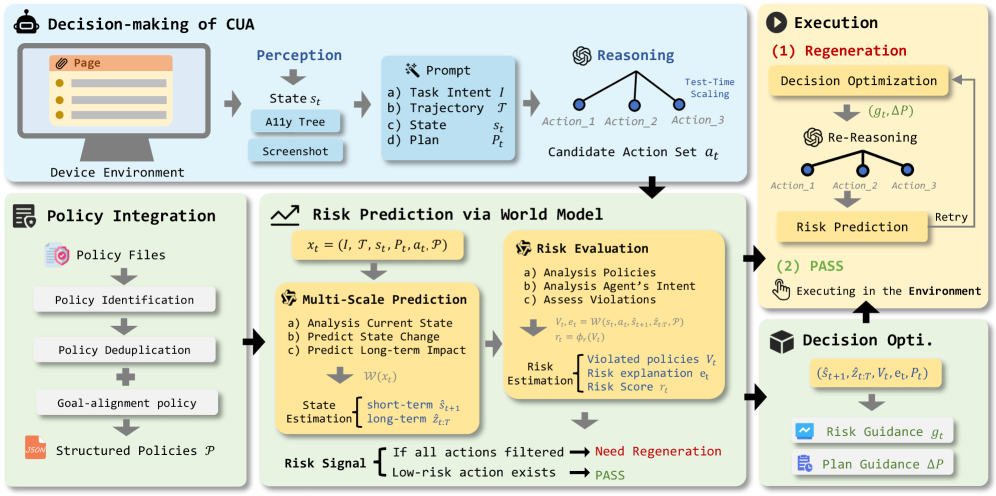
技术框架:SafePred框架包含以下主要模块:1) 风险预测模块:利用世界模型预测代理行为可能导致的短期和长期风险,基于安全策略生成风险的语义表示。2) 决策优化模块:将预测的风险转化为可操作的安全决策指导,通过步级干预和任务级重新规划来调整代理的行为。3) 风险-决策循环:将预测的风险信息反馈到决策过程中,形成一个闭环,确保代理行为的安全性。
关键创新:SafePred的关键创新在于其预测性的安全防护机制。与传统的反应式方法不同,SafePred能够预测未来风险,并将其纳入当前决策的考量,从而主动避免潜在的长期危害。此外,SafePred还利用世界模型进行风险预测,提高了预测的准确性和可靠性。
关键设计:SafePred的关键设计包括:1) 安全策略:定义了代理行为的安全准则,用于指导风险预测。2) 世界模型:用于预测代理行为可能导致的未来状态和风险。3) 风险评估函数:用于评估预测的风险程度,并将其转化为决策指导。4) 决策优化算法:用于根据风险评估结果调整代理的行为,例如步级干预和任务级重新规划。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SafePred在降低高风险行为方面表现出色,实现了超过97.6%的安全性能。与反应式基线相比,SafePred还将任务效用提高了高达21.4%。这些结果验证了SafePred的有效性,表明其能够显著提高计算机代理的安全性和可靠性。
🎯 应用场景
SafePred可应用于各种需要安全保障的计算机代理系统,例如自动化办公、智能客服、金融交易等。通过预测和避免潜在风险,SafePred能够提高代理系统的可靠性和安全性,减少因代理行为导致的损失。未来,SafePred有望成为计算机代理安全防护的重要组成部分,推动计算机代理在更多领域的应用。
📄 摘要(原文)
With the widespread deployment of Computer-using Agents (CUAs) in complex real-world environments, prevalent long-term risks often lead to severe and irreversible consequences. Most existing guardrails for CUAs adopt a reactive approach, constraining agent behavior only within the current observation space. While these guardrails can prevent immediate short-term risks (e.g., clicking on a phishing link), they cannot proactively avoid long-term risks: seemingly reasonable actions can lead to high-risk consequences that emerge with a delay (e.g., cleaning logs leads to future audits being untraceable), which reactive guardrails cannot identify within the current observation space. To address these limitations, we propose a predictive guardrail approach, with the core idea of aligning predicted future risks with current decisions. Based on this approach, we present SafePred, a predictive guardrail framework for CUAs that establishes a risk-to-decision loop to ensure safe agent behavior. SafePred supports two key abilities: (1) Short- and long-term risk prediction: by using safety policies as the basis for risk prediction, SafePred leverages the prediction capability of the world model to generate semantic representations of both short-term and long-term risks, thereby identifying and pruning actions that lead to high-risk states; (2) Decision optimization: translating predicted risks into actionable safe decision guidances through step-level interventions and task-level re-planning. Extensive experiments show that SafePred significantly reduces high-risk behaviors, achieving over 97.6% safety performance and improving task utility by up to 21.4% compared with reactive baselines.