Game of Thought: Robust Information Seeking with Large Language Models Using Game Theory
作者: Langyuan Cui, Chun Kai Ling, Hwee Tou Ng
分类: cs.CL, cs.AI, cs.GT
发布日期: 2026-02-02
备注: 23 pages, 10 figures, under review at ICML 2026
💡 一句话要点
提出Game of Thought框架,利用博弈论提升大语言模型在信息搜寻任务中的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 信息搜寻 博弈论 鲁棒性 对抗性环境
📋 核心要点
- 现有大语言模型在信息不足时,主动信息搜寻能力不足,且现有方法在最坏情况下表现不佳。
- 提出Game of Thought框架,将信息搜寻问题建模为博弈,利用博弈论寻找纳什均衡策略。
- 实验表明,GoT框架在各种设置下,均能提升大语言模型在信息搜寻任务中的最坏情况性能。
📝 摘要(中文)
大型语言模型(LLMs)越来越多地部署在现实场景中,但它们可能缺乏完成给定任务的足够信息。在这种情况下,主动寻找缺失信息的能力至关重要。现有的增强这种能力的方法通常依赖于简化的假设,这会降低 extit{最坏情况}下的性能。这在高风险应用中是一个具有严重影响的问题。在这项工作中,我们使用“二十个问题”游戏来评估LLM的信息搜寻能力。我们引入并形式化了它的对抗性对应物,即战略语言搜索(SLS)问题及其变体,作为一个双人零和扩展形式博弈。我们提出了Game of Thought (GoT),一个应用博弈论技术来近似该游戏受限变体的纳什均衡(NE)策略的框架。经验结果表明,与(1)基于直接提示的方法和(2)基于启发式引导的搜索方法相比,我们的方法在所有测试设置中始终提高了最坏情况下的性能。
🔬 方法详解
问题定义:论文旨在解决大语言模型在信息搜寻任务中,面对对抗性环境时鲁棒性不足的问题。现有方法通常基于简化的假设,导致在最坏情况下性能显著下降,无法保证在高风险应用中的可靠性。论文将此问题形式化为战略语言搜索(SLS)问题,作为“二十个问题”游戏的对抗性版本。
核心思路:论文的核心思路是将信息搜寻过程建模为一个双人零和博弈,其中一个玩家(LLM)试图通过提问获取信息,另一个玩家(对抗者)则试图给出误导性答案。通过寻找该博弈的纳什均衡(NE)策略,可以得到在最坏情况下也能保证一定性能的信息搜寻策略。这种方法的核心在于利用博弈论的框架,显式地考虑了对抗性环境的影响,从而提升了模型的鲁棒性。
技术框架:Game of Thought (GoT)框架包含以下主要步骤:1. 将信息搜寻问题建模为双人零和扩展形式博弈。2. 使用博弈论技术(具体方法未知,论文中可能未详细说明)来近似计算该博弈的纳什均衡策略。3. 利用得到的纳什均衡策略指导大语言模型进行信息搜寻。具体来说,LLM根据当前状态和纳什均衡策略选择下一个问题,并根据收到的答案更新状态,直到找到目标信息或达到最大提问次数。
关键创新:论文的关键创新在于将博弈论引入到大语言模型的信息搜寻任务中,并显式地考虑了对抗性环境的影响。与传统的基于启发式搜索或直接提示的方法相比,GoT框架能够更好地应对最坏情况,从而提升了模型的鲁棒性。此外,将信息搜寻问题形式化为战略语言搜索(SLS)问题,为后续研究提供了标准化的评估基准。
关键设计:论文中关于博弈论技术的具体实现细节未知。但是,可以推测可能涉及到对博弈树的搜索和评估,以及对纳什均衡的近似计算。此外,如何有效地将纳什均衡策略融入到大语言模型的提示中,以及如何设计合适的奖励函数来鼓励模型学习有效的提问策略,也是关键的设计考虑因素。论文中可能还涉及到对提问次数的限制,以及对答案质量的评估等方面的设计。
🖼️ 关键图片

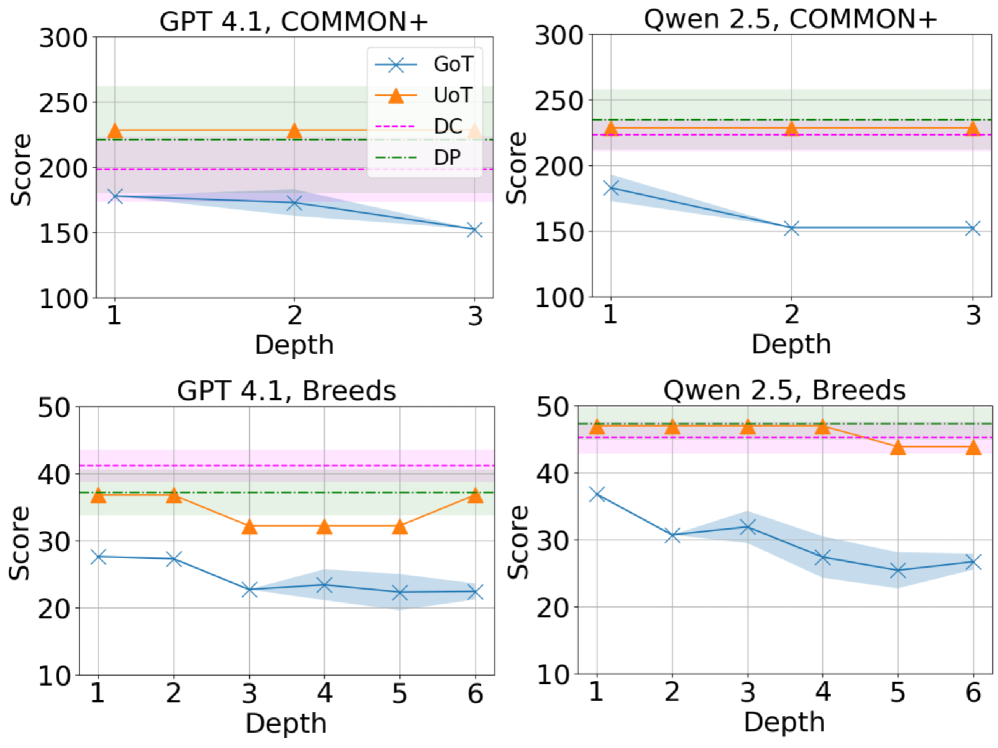
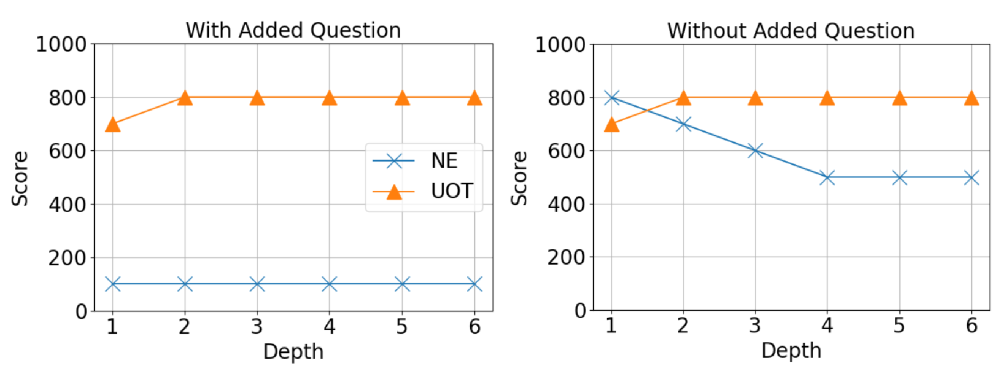
📊 实验亮点
实验结果表明,Game of Thought框架在各种测试设置下,均能显著提升大语言模型在信息搜寻任务中的最坏情况性能。与基于直接提示的方法和基于启发式引导的搜索方法相比,GoT框架能够更有效地应对对抗性环境,从而提高了模型的鲁棒性。具体的性能提升幅度未知,需要在论文中查找更详细的实验数据。
🎯 应用场景
该研究成果可应用于需要高可靠性和鲁棒性的信息搜寻场景,例如医疗诊断、金融风险评估、法律咨询等。通过提升大语言模型在对抗性环境下的信息搜寻能力,可以减少错误决策的风险,提高决策的准确性和可靠性。未来,该方法还可以扩展到其他需要主动信息获取的任务中,例如机器人导航、智能客服等。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed in real-world scenarios where they may lack sufficient information to complete a given task. In such settings, the ability to actively seek out missing information becomes a critical capability. Existing approaches to enhancing this ability often rely on simplifying assumptions that degrade \textit{worst-case} performance. This is an issue with serious implications in high-stakes applications. In this work, we use the game of Twenty Questions to evaluate the information-seeking ability of LLMs. We introduce and formalize its adversarial counterpart, the Strategic Language Search (SLS) problem along with its variants as a two-player zero-sum extensive form game. We propose Game of Thought (GoT), a framework that applies game-theoretic techniques to approximate a Nash equilibrium (NE) strategy for the restricted variant of the game. Empirical results demonstrate that our approach consistently improves worst-case performance compared to (1) direct prompting-based methods and (2) heuristic-guided search methods across all tested settings.