Provable Defense Framework for LLM Jailbreaks via Noise-Augumented Alignment
作者: Zehua Cheng, Jianwei Yang, Wei Dai, Jiahao Sun
分类: cs.CL, cs.AI
发布日期: 2026-02-02
备注: 10 pages
💡 一句话要点
提出噪声增强对齐的认证防御框架,提升LLM抵抗恶意越狱攻击的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对抗攻击 越狱攻击 可认证鲁棒性 语义平滑
📋 核心要点
- 现有LLM防御方法易被自适应越狱攻击绕过,缺乏可证明的鲁棒性保证。
- 提出认证语义平滑(CSS)和噪声增强对齐调整(NAAT),构建可认证的防御框架。
- 实验表明,该方法显著降低攻击成功率,同时保持较高的良性效用,优于现有基线。
📝 摘要(中文)
大型语言模型(LLMs)仍然容易受到自适应越狱攻击的影响,这些攻击可以轻易绕过经验性防御,如GCG。我们提出了一个可认证鲁棒性的框架,将安全保证从单次推理转移到集成的统计稳定性。我们引入了通过分层随机消融实现的认证语义平滑(CSS),该技术将输入划分为不可变的结构化提示和可变的有效载荷,以使用超几何分布推导出严格的l0范数保证。为了解决稀疏上下文中的性能下降问题,我们采用了噪声增强对齐调整(NAAT),将基础模型转换为语义去噪器。在Llama-3上的大量实验表明,我们的方法将基于梯度的攻击的攻击成功率从84.2%降低到1.2%,同时保持94.1%的良性效用,显著优于将效用降低到74.3%的字符级基线。该框架提供了一个确定性的安全证书,确保模型在可证明的半径内对所有对抗变体保持鲁棒性。
🔬 方法详解
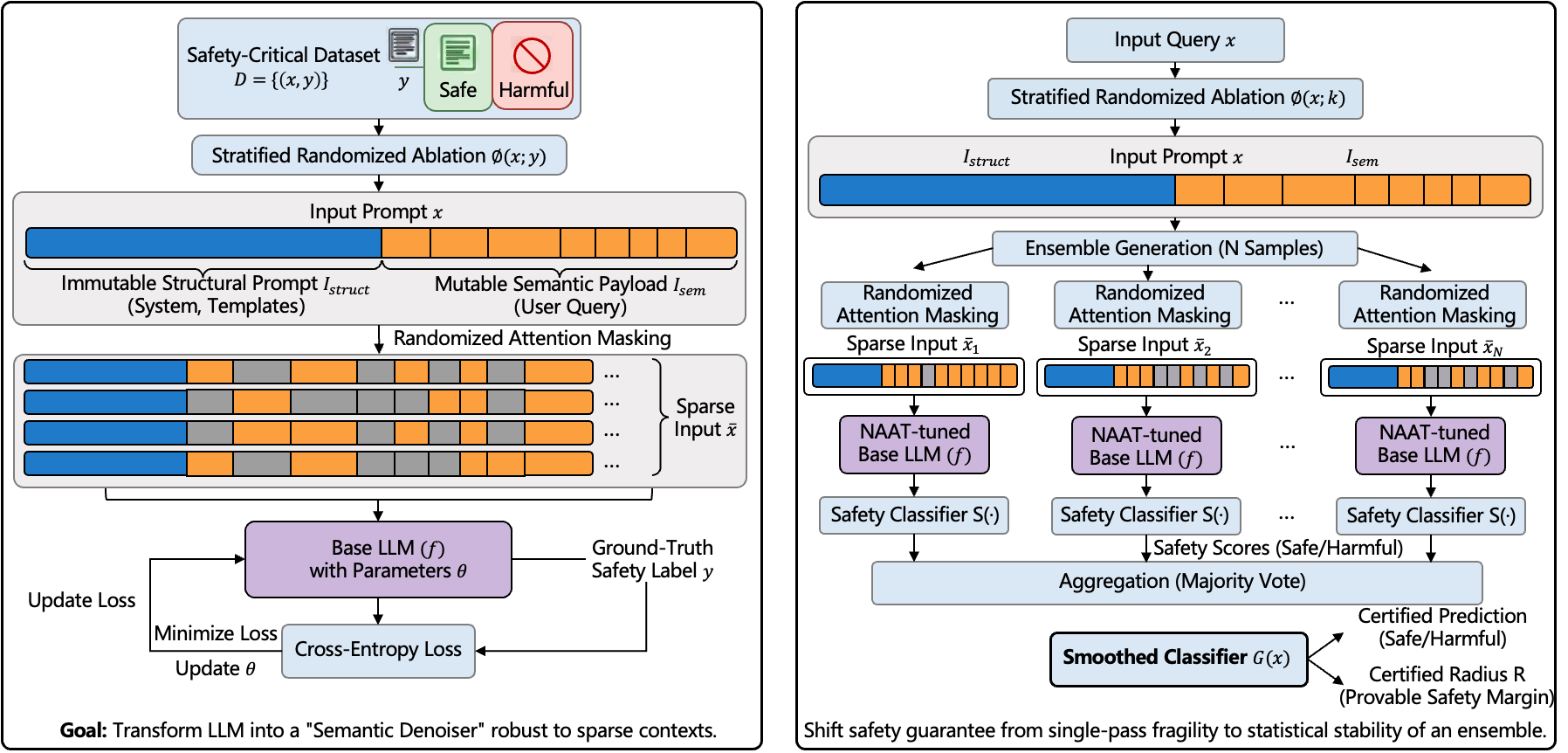
问题定义:现有的大型语言模型(LLMs)容易受到对抗性攻击,特别是越狱攻击,攻击者可以通过精心设计的输入绕过模型的安全限制。现有的防御方法,如GCG,通常是经验性的,容易被自适应攻击绕过,缺乏可证明的鲁棒性保证。因此,如何提供一种可认证的防御框架,确保模型在一定范围内的对抗性扰动下仍然安全,是一个重要的挑战。
核心思路:该论文的核心思路是将安全保证从单次推理转移到集成的统计稳定性。通过引入认证语义平滑(CSS),将输入划分为结构化提示和可变的有效载荷,并使用超几何分布来推导鲁棒性保证。此外,为了解决在稀疏上下文中的性能下降问题,采用了噪声增强对齐调整(NAAT),将基础模型转换为语义去噪器,从而提高模型的鲁棒性和泛化能力。
技术框架:该框架主要包含两个核心模块:认证语义平滑(CSS)和噪声增强对齐调整(NAAT)。CSS通过分层随机消融,将输入划分为不可变的结构化提示和可变的有效载荷,并使用超几何分布来计算鲁棒性半径。NAAT则通过引入噪声来增强模型的鲁棒性,并使用对齐调整来保持模型的性能。整体流程是先使用NAAT对基础模型进行微调,然后使用CSS对模型进行认证,从而获得一个具有可证明鲁棒性的LLM。
关键创新:该论文的关键创新在于提出了一个可认证的防御框架,该框架可以提供确定性的安全证书,确保模型在可证明的半径内对所有对抗变体保持鲁棒性。与现有的经验性防御方法相比,该框架具有更强的安全性和可靠性。此外,该论文还提出了噪声增强对齐调整(NAAT),可以有效地提高模型的鲁棒性和泛化能力。
关键设计:在CSS中,关键的设计在于如何将输入划分为结构化提示和可变的有效载荷,以及如何使用超几何分布来计算鲁棒性半径。在NAAT中,关键的设计在于如何引入噪声,以及如何使用对齐调整来保持模型的性能。具体的参数设置和损失函数需要根据具体的任务和数据集进行调整。例如,噪声的强度和对齐调整的权重需要根据实验结果进行优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在Llama-3上将基于梯度的攻击的攻击成功率从84.2%降低到1.2%,同时保持94.1%的良性效用。相比之下,字符级基线将效用降低到74.3%。这表明该方法在提高模型鲁棒性的同时,能够有效地保持模型的性能。
🎯 应用场景
该研究成果可应用于各种需要高安全性和可靠性的LLM应用场景,例如金融、医疗、法律等领域。通过提供可认证的防御框架,可以确保LLM在这些关键领域中的安全使用,防止恶意攻击和数据泄露。此外,该研究还可以促进LLM在更广泛的应用场景中的部署,提高LLM的社会价值。
📄 摘要(原文)
Large Language Models (LLMs) remain vulnerable to adaptive jailbreaks that easily bypass empirical defenses like GCG. We propose a framework for certifiable robustness that shifts safety guarantees from single-pass inference to the statistical stability of an ensemble. We introduce Certified Semantic Smoothing (CSS) via Stratified Randomized Ablation, a technique that partitions inputs into immutable structural prompts and mutable payloads to derive rigorous lo norm guarantees using the Hypergeometric distribution. To resolve performance degradation on sparse contexts, we employ Noise-Augmented Alignment Tuning (NAAT), which transforms the base model into a semantic denoiser. Extensive experiments on Llama-3 show that our method reduces the Attack Success Rate of gradient-based attacks from 84.2% to 1.2% while maintaining 94.1% benign utility, significantly outperforming character-level baselines which degrade utility to 74.3%. This framework provides a deterministic certificate of safety, ensuring that a model remains robust against all adversarial variants within a provable radius.