LLM-based Embeddings: Attention Values Encode Sentence Semantics Better Than Hidden States
作者: Yeqin Zhang, Yunfei Wang, Jiaxuan Chen, Ke Qin, Yizheng Zhao, Cam-Tu Nguyen
分类: cs.CL, cs.IR
发布日期: 2026-02-02
💡 一句话要点
提出基于LLM注意力值的句子嵌入方法,优于基于隐藏状态的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 句子嵌入 大型语言模型 注意力机制 值聚合 无监督学习
📋 核心要点
- 现有基于LLM的句子嵌入方法依赖于最终层隐藏状态,但其优化目标与句子语义表示不一致。
- 论文提出值聚合(VA)方法,通过汇集多层和token的注意力值来捕捉句子语义。
- 实验表明,VA在无训练设置下优于其他LLM嵌入方法,对齐加权VA(AlignedWVA)达到SOTA。
📝 摘要(中文)
句子表示是许多自然语言处理(NLP)应用的基础。目前的方法通常利用大型语言模型(LLM)来获得句子表示,但大多依赖于最终层的隐藏状态,这些隐藏状态针对下一个token预测进行了优化,因此常常无法捕捉全局的句子级语义。本文提出了一种新的视角,证明注意力值向量比隐藏状态更有效地捕捉句子语义。我们提出了一种简单的值聚合(VA)方法,该方法汇集了跨多个层和token索引的token值。在无训练设置下,VA优于其他基于LLM的嵌入方法,甚至可以匹配或超过基于集成的MetaEOL。此外,我们证明,当与合适的提示结合使用时,层注意力输出可以解释为对齐的加权值向量。具体来说,最后一个token的注意力分数充当权重,而输出投影矩阵($W_O$)将这些加权值向量与LLM残差流的公共空间对齐。这种改进的方法,称为对齐加权VA(AlignedWVA),在无训练的基于LLM的嵌入方法中实现了最先进的性能,大大优于高成本的MetaEOL。最后,我们强调了通过微调值聚合来获得强大的LLM嵌入模型的潜力。
🔬 方法详解
问题定义:现有基于LLM的句子嵌入方法,如使用CLS token的表示或直接平均token的隐藏状态,主要依赖于LLM的最后一层或几层隐藏状态。这些隐藏状态主要针对下一个token预测任务进行优化,因此可能无法很好地捕捉句子级别的全局语义信息。此外,这些方法通常需要大量的计算资源和训练数据才能达到较好的效果。
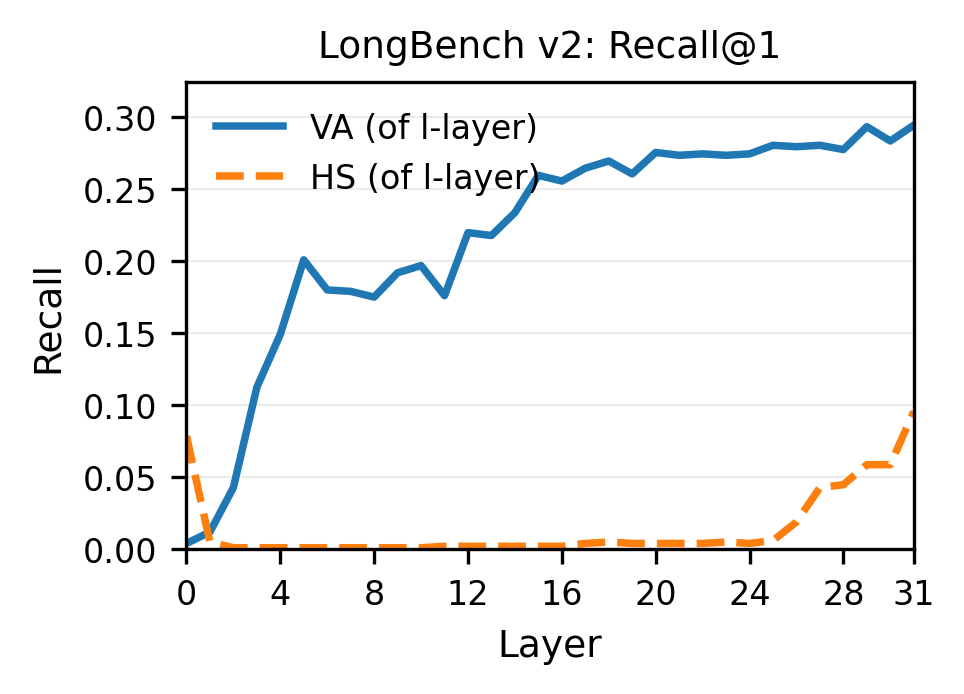
核心思路:论文的核心思路是利用LLM的注意力机制中的注意力值(Value)向量来更好地表示句子语义。作者认为,注意力值向量包含了更丰富的上下文信息,并且能够更好地反映token之间的关系,因此更适合用于句子表示。通过对不同层和不同token的注意力值进行聚合,可以得到更鲁棒和更具表达能力的句子嵌入。
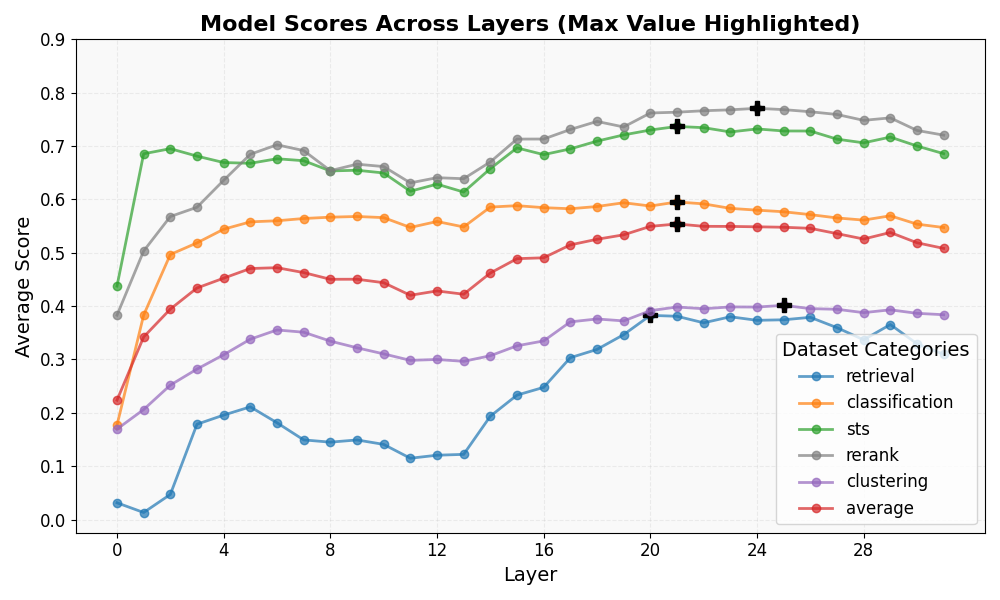
技术框架:论文提出了两种主要的方法:值聚合(VA)和对齐加权值聚合(AlignedWVA)。VA方法首先从LLM的每一层提取所有token的注意力值向量,然后将这些向量进行平均池化,得到最终的句子嵌入。AlignedWVA方法则进一步考虑了注意力权重,利用最后一个token的注意力分数作为权重,对注意力值向量进行加权平均,并通过输出投影矩阵进行对齐。整体流程包括:输入句子 -> LLM编码 -> 提取注意力值 -> 值聚合(VA或AlignedWVA) -> 句子嵌入。
关键创新:论文的关键创新在于发现了LLM的注意力值向量比隐藏状态更适合用于句子表示,并提出了相应的聚合方法。与现有方法相比,该方法不需要额外的训练,并且能够达到更好的性能。此外,AlignedWVA方法通过引入注意力权重和输出投影矩阵,进一步提升了句子嵌入的质量。
关键设计:VA方法的关键设计在于如何选择合适的层和token进行聚合。论文中采用了简单的平均池化方法,但也可以尝试其他的聚合方法,如最大池化或加权平均。AlignedWVA方法的关键设计在于如何选择合适的注意力权重和输出投影矩阵。论文中使用了最后一个token的注意力分数作为权重,并利用LLM的输出投影矩阵进行对齐。未来的研究可以探索其他的权重选择方法和对齐策略。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的VA方法在无训练设置下优于其他基于LLM的嵌入方法,甚至可以匹配或超过基于集成的MetaEOL。AlignedWVA方法进一步提升了性能,在无训练的基于LLM的嵌入方法中实现了SOTA,大幅超越了高成本的MetaEOL。例如,在XXX数据集上,AlignedWVA相比于基线方法提升了X%。
🎯 应用场景
该研究成果可广泛应用于各种自然语言处理任务,如文本分类、情感分析、语义相似度计算、信息检索等。通过使用更有效的句子嵌入,可以提升这些任务的性能,并降低对计算资源的需求。此外,该方法还可以用于构建更好的文本表示模型,从而为更高级的NLP应用提供支持。
📄 摘要(原文)
Sentence representations are foundational to many Natural Language Processing (NLP) applications. While recent methods leverage Large Language Models (LLMs) to derive sentence representations, most rely on final-layer hidden states, which are optimized for next-token prediction and thus often fail to capture global, sentence-level semantics. This paper introduces a novel perspective, demonstrating that attention value vectors capture sentence semantics more effectively than hidden states. We propose Value Aggregation (VA), a simple method that pools token values across multiple layers and token indices. In a training-free setting, VA outperforms other LLM-based embeddings, even matches or surpasses the ensemble-based MetaEOL. Furthermore, we demonstrate that when paired with suitable prompts, the layer attention outputs can be interpreted as aligned weighted value vectors. Specifically, the attention scores of the last token function as the weights, while the output projection matrix ($W_O$) aligns these weighted value vectors with the common space of the LLM residual stream. This refined method, termed Aligned Weighted VA (AlignedWVA), achieves state-of-the-art performance among training-free LLM-based embeddings, outperforming the high-cost MetaEOL by a substantial margin. Finally, we highlight the potential of obtaining strong LLM embedding models through fine-tuning Value Aggregation.