FS-Researcher: Test-Time Scaling for Long-Horizon Research Tasks with File-System-Based Agents
作者: Chiwei Zhu, Benfeng Xu, Mingxuan Du, Shaohan Wang, Xiaorui Wang, Zhendong Mao, Yongdong Zhang
分类: cs.CL
发布日期: 2026-02-02
备注: 19 pages, 6 figures
🔗 代码/项目: GITHUB
💡 一句话要点
FS-Researcher:面向长程研究任务,基于文件系统的LLM智能体测试时扩展框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长程任务 大型语言模型 文件系统 智能体 知识库 测试时扩展 深度研究
📋 核心要点
- 现有LLM智能体在长程深度研究任务中,受限于上下文窗口大小,难以有效收集证据和撰写报告。
- FS-Researcher利用文件系统作为外部记忆和协调媒介,构建双智能体框架,实现知识库的持久化和迭代改进。
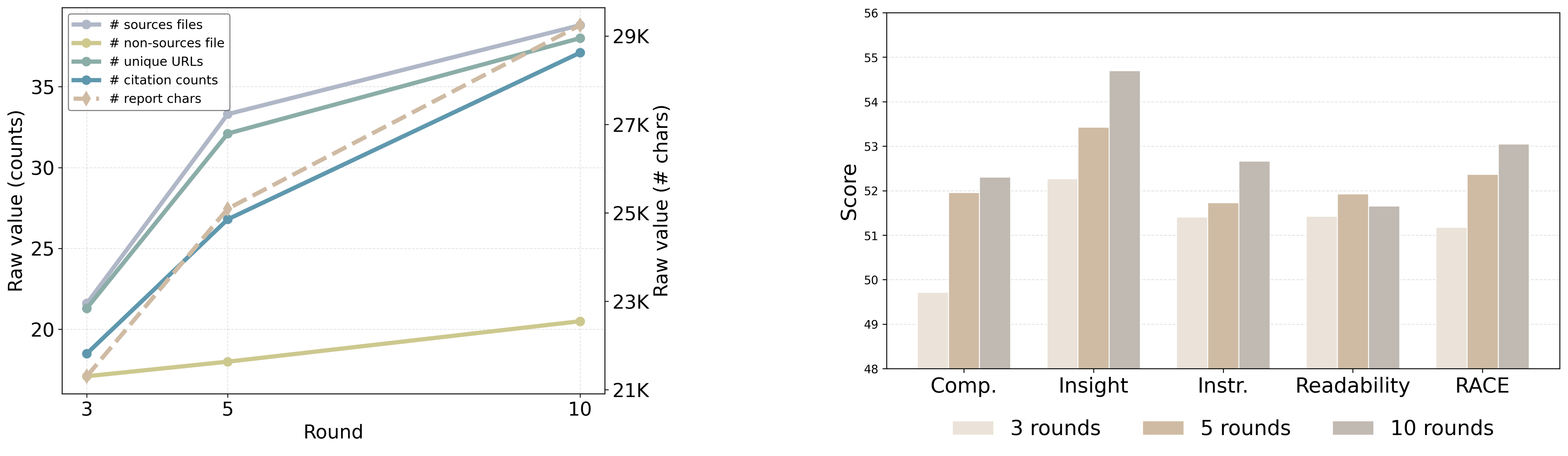
- 实验表明,FS-Researcher在报告质量上达到了SOTA,并验证了计算资源分配与报告质量的正相关性。
📝 摘要(中文)
深度研究正成为大型语言模型(LLM)智能体中一种具有代表性的长程任务。然而,深度研究中的长轨迹通常会超出模型的上下文限制,压缩了证据收集和报告撰写的token预算,从而阻碍了有效的测试时扩展。我们提出了FS-Researcher,一个基于文件系统的双智能体框架,它通过持久的工作空间将深度研究扩展到上下文窗口之外。具体来说,Context Builder智能体充当图书管理员的角色,浏览互联网,编写结构化笔记,并将原始来源归档到可以远远超出上下文长度的分层知识库中。然后,Report Writer智能体逐节撰写最终报告,将知识库视为事实来源。在这个框架中,文件系统充当持久的外部存储和跨智能体和会话的共享协调媒介,从而实现超出上下文窗口的迭代改进。在两个开放式基准测试(DeepResearch Bench和DeepConsult)上的实验表明,FS-Researcher在不同的骨干模型上实现了最先进的报告质量。进一步的分析表明,最终报告质量与分配给Context Builder的计算量之间存在正相关关系,验证了文件系统范式下有效的测试时扩展。代码和数据已匿名开源。
🔬 方法详解
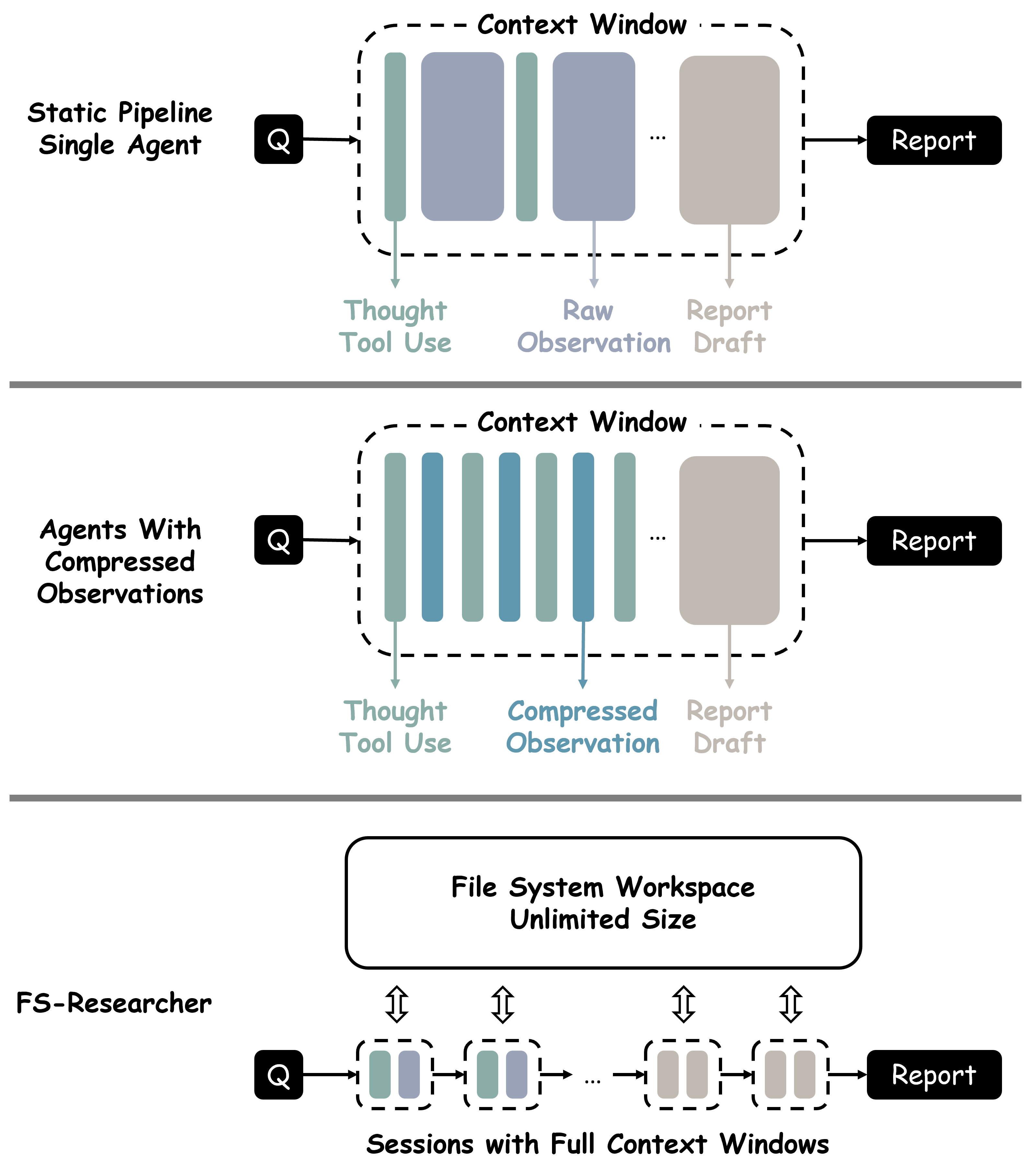
问题定义:现有基于LLM的智能体在执行长程深度研究任务时,面临着上下文窗口的限制。这意味着随着研究的深入,模型能够记住的信息量受到限制,导致无法有效地收集和利用证据,最终影响报告的质量。现有方法难以在测试时扩展,无法充分利用更多的计算资源来提升性能。
核心思路:FS-Researcher的核心思路是利用文件系统作为LLM智能体的外部记忆,突破上下文窗口的限制。通过将收集到的信息和生成的知识存储在文件系统中,智能体可以随时访问和更新这些信息,从而实现长程记忆和迭代改进。此外,采用双智能体架构,将任务分解为证据收集和报告撰写两个阶段,分别由不同的智能体负责,从而提高效率和质量。
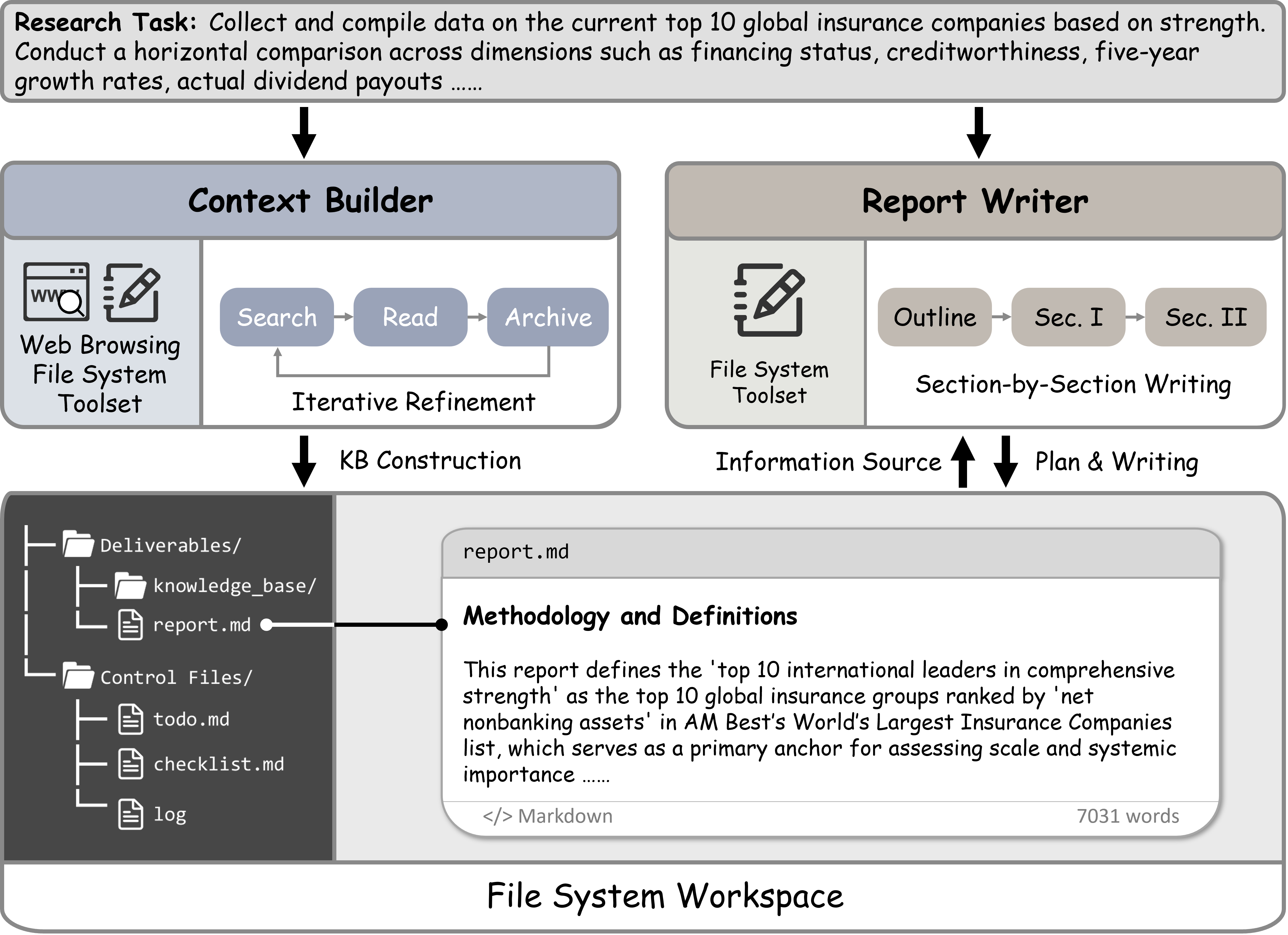
技术框架:FS-Researcher包含两个主要智能体:Context Builder和Report Writer。Context Builder负责浏览互联网,收集相关信息,并将信息整理成结构化的笔记,存储到文件系统中。Report Writer负责根据文件系统中的知识,撰写最终的报告。文件系统充当了两个智能体之间的共享媒介,以及智能体的外部记忆。整个流程是迭代的,Report Writer可以根据需要向Context Builder请求更多信息,Context Builder可以根据Report Writer的反馈更新知识库。
关键创新:FS-Researcher的关键创新在于利用文件系统作为LLM智能体的外部记忆,突破了上下文窗口的限制,实现了长程记忆和迭代改进。此外,双智能体架构的设计,将任务分解为证据收集和报告撰写两个阶段,提高了效率和质量。这种基于文件系统的架构,使得智能体可以方便地访问和更新知识,从而更好地适应长程任务。
关键设计:Context Builder使用结构化的笔记格式,例如Markdown,来存储收集到的信息。文件系统采用分层结构,方便智能体查找和管理知识。Report Writer采用逐节撰写的方式,逐步构建最终的报告。在实验中,研究人员探索了不同的骨干模型和计算资源分配策略,以评估FS-Researcher的性能。
🖼️ 关键图片
📊 实验亮点
在DeepResearch Bench和DeepConsult两个基准测试中,FS-Researcher在不同的骨干模型上均取得了SOTA的报告质量。实验结果表明,分配给Context Builder的计算资源越多,最终报告的质量越高,验证了文件系统范式下有效的测试时扩展。例如,在DeepResearch Bench上,FS-Researcher相比于基线方法,报告质量提升了显著幅度(具体数值未知)。
🎯 应用场景
FS-Researcher可应用于自动化研究报告生成、智能咨询、知识库构建等领域。它能够帮助研究人员更高效地进行文献综述、数据分析和报告撰写。该框架的模块化设计也使其易于扩展到其他长程任务,例如软件开发、产品设计等。未来,FS-Researcher有望成为LLM智能体在复杂任务中实现自主学习和决策的重要工具。
📄 摘要(原文)
Deep research is emerging as a representative long-horizon task for large language model (LLM) agents. However, long trajectories in deep research often exceed model context limits, compressing token budgets for both evidence collection and report writing, and preventing effective test-time scaling. We introduce FS-Researcher, a file-system-based, dual-agent framework that scales deep research beyond the context window via a persistent workspace. Specifically, a Context Builder agent acts as a librarian which browses the internet, writes structured notes, and archives raw sources into a hierarchical knowledge base that can grow far beyond context length. A Report Writer agent then composes the final report section by section, treating the knowledge base as the source of facts. In this framework, the file system serves as a durable external memory and a shared coordination medium across agents and sessions, enabling iterative refinement beyond the context window. Experiments on two open-ended benchmarks (DeepResearch Bench and DeepConsult) show that FS-Researcher achieves state-of-the-art report quality across different backbone models. Further analyses demonstrate a positive correlation between final report quality and the computation allocated to the Context Builder, validating effective test-time scaling under the file-system paradigm. The code and data are anonymously open-sourced at https://github.com/Ignoramus0817/FS-Researcher.