Argument Rarity-based Originality Assessment for AI-Assisted Writing
作者: Keito Inoshita, Michiaki Omura, Tsukasa Yamanaka, Go Maeda, Kentaro Tsuji
分类: cs.CL
发布日期: 2026-02-02
💡 一句话要点
提出基于论证稀有度的原创性评估框架AROA,用于评估AI辅助写作中学生文章的原创性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 原创性评估 AI辅助写作 论证稀有度 大型语言模型 密度估计
📋 核心要点
- 传统写作评估侧重于质量,忽略了原创性在培养批判性思维中的重要作用,无法有效评估AI辅助写作。
- AROA框架将原创性定义为在参考语料库中的稀有程度,并从结构、论点、证据和认知深度四个方面进行量化评估。
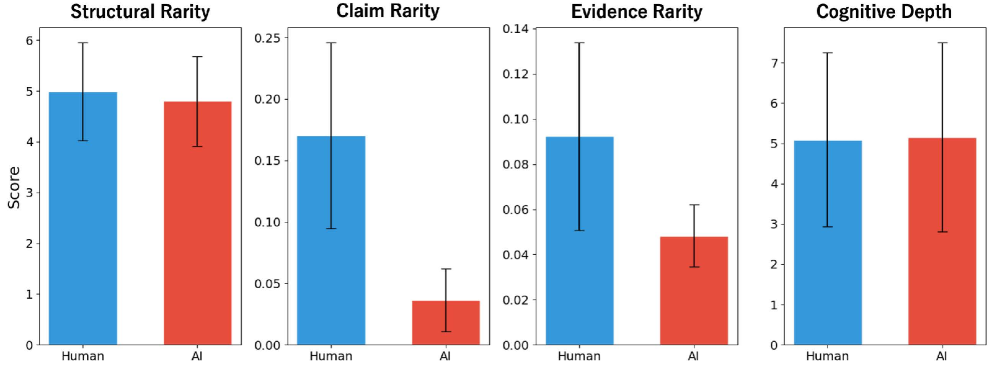
- 实验表明,高质量文章与论点稀有性呈负相关,AI生成文章在论点原创性方面明显低于人类文章。
📝 摘要(中文)
随着大型语言模型(LLMs)能够轻松生成高质量文本,传统的以质量为中心的写作评估正失去其意义。如果教育的根本目标是培养批判性思维和原创观点,那么评估也必须将其范式从质量转向原创性。本研究提出了基于论证稀有度的原创性评估(AROA)框架,用于自动评估学生文章中论证的原创性。AROA将原创性定义为参考语料库中的稀有性,并通过四个互补的组成部分对其进行评估:结构稀有性、论点稀有性、证据稀有性和认知深度。该框架使用密度估计来量化每个组成部分的稀有性,并将其与质量调整机制相结合,从而将质量和原创性视为独立的评估轴。使用人类文章和AI生成的文章进行的实验表明,质量和论点稀有性之间存在很强的负相关关系,这表明高质量的文本往往依赖于典型的论点模式,从而导致质量-原创性之间的权衡。此外,虽然AI文章在结构复杂性方面达到了与人类文章相当的水平,但它们的论点稀有性远低于人类,这表明LLM可以重现论证的形式,但在内容的原创性方面存在局限性。
🔬 方法详解
问题定义:论文旨在解决如何自动评估AI辅助写作中学生文章的论证原创性问题。现有方法主要关注文章质量,缺乏对原创性的有效评估,无法区分人类写作和AI生成内容,并且难以衡量学生在批判性思维方面的能力。
核心思路:论文的核心思路是将文章的原创性定义为在参考语料库中的稀有程度。通过分析文章的结构、论点、证据和认知深度,量化这些组成部分在语料库中的稀有性,从而评估文章的整体原创性。这种方法将原创性与质量分开评估,避免了高质量文章必然具有原创性的假设。
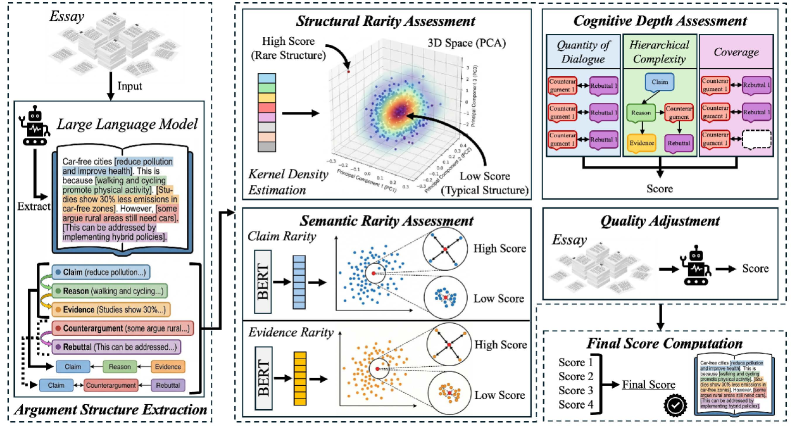
技术框架:AROA框架包含以下主要模块:1) 结构分析:提取文章的论证结构,例如论点、论据和结论。2) 论点提取:识别文章中的主要论点。3) 证据提取:提取支持论点的证据。4) 认知深度评估:评估论证的复杂性和深度。5) 稀有度量化:使用密度估计方法,计算每个组成部分在参考语料库中的稀有程度。6) 质量调整:引入质量调整机制,将质量作为独立的评估维度,避免高质量掩盖低原创性。7) 原创性评分:综合各个组成部分的稀有度,给出文章的整体原创性评分。
关键创新:AROA框架的关键创新在于:1) 将原创性定义为稀有性,并提出了一种量化的评估方法。2) 将原创性评估分解为结构、论点、证据和认知深度四个维度,从而更全面地评估文章的原创性。3) 引入质量调整机制,将质量和原创性作为独立的评估维度,避免了质量对原创性的影响。4) 提出了一种适用于AI辅助写作场景的原创性评估方法,可以有效区分人类写作和AI生成内容。
关键设计:论文使用密度估计(具体方法未知)来量化各个组成部分的稀有度。质量调整机制的具体实现方式未知,但其目的是降低高质量文章在原创性评估中的优势。论文使用人工标注的论证结构数据和AI生成文章进行实验,验证了AROA框架的有效性。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,人类文章的论点稀有性明显高于AI生成文章,表明LLM在内容原创性方面存在局限性。同时,实验发现质量和论点稀有性之间存在负相关关系,即高质量文章可能依赖于更常见的论点模式。AROA框架能够有效区分人类写作和AI生成内容,为原创性评估提供了一种新的方法。
🎯 应用场景
AROA框架可应用于教育领域,用于评估学生在AI辅助写作中的原创性,促进批判性思维的培养。该框架还可以用于评估AI生成内容的原创性,防止学术不端行为。此外,该方法可以推广到其他文本生成领域,例如新闻报道和创意写作,以评估内容的创新性和独特性。
📄 摘要(原文)
As Large Language Models (LLMs) have become capable of effortlessly generating high-quality text, traditional quality-focused writing assessment is losing its significance. If the essential goal of education is to foster critical thinking and original perspectives, assessment must also shift its paradigm from quality to originality. This study proposes Argument Rarity-based Originality Assessment (AROA), a framework for automatically evaluating argumentative originality in student essays. AROA defines originality as rarity within a reference corpus and evaluates it through four complementary components: structural rarity, claim rarity, evidence rarity, and cognitive depth. The framework quantifies the rarity of each component using density estimation and integrates them with a quality adjustment mechanism, thereby treating quality and originality as independent evaluation axes. Experiments using human essays and AI-generated essays revealed a strong negative correlation between quality and claim rarity, demonstrating a quality-originality trade-off where higher-quality texts tend to rely on typical claim patterns. Furthermore, while AI essays achieved comparable levels of structural complexity to human essays, their claim rarity was substantially lower than that of humans, indicating that LLMs can reproduce the form of argumentation but have limitations in the originality of content.