DIFFA-2: A Practical Diffusion Large Language Model for General Audio Understanding
作者: Jiaming Zhou, Xuxin Cheng, Shiwan Zhao, Yuhang Jia, Cao Liu, Ke Zeng, Xunliang Cai, Yong Qin
分类: cs.SD, cs.CL
发布日期: 2026-01-30
🔗 代码/项目: GITHUB
💡 一句话要点
DIFFA-2:一种实用的扩散大语言模型,用于通用音频理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频理解 扩散模型 大语言模型 语音编码 双适配器 四阶段训练 有监督微调
📋 核心要点
- 自回归音频大语言模型扩展成本高,推理效率受限,难以满足实际应用需求。
- DIFFA-2采用扩散模型作为主干,结合双适配器和四阶段训练,提升音频理解能力。
- 实验表明,DIFFA-2在实际训练预算下,性能与强大的自回归模型相当,验证了扩散模型的潜力。
📝 摘要(中文)
本文介绍了DIFFA-2,一种用于通用音频理解的实用型基于扩散的大语言模型(LALM)。现有的自回归(AR)LALM,如Qwen-2.5-Omni,在音频理解和交互方面表现出色,但其扩展在数据和计算上成本高昂,且严格的顺序解码限制了推理效率。扩散大语言模型(dLLM)最近被证明能有效利用有限的训练数据。先前关于DIFFA的工作表明,在匹配的设置下,用扩散模型替代AR主干可以显著提高音频理解能力,但其规模较小,缺乏大规模的指令调优、偏好对齐或实用的解码方案。DIFFA-2升级了语音编码器,采用了双语义和声学适配器,并使用一个四阶段课程进行训练,该课程结合了语义和声学对齐、大规模监督微调和方差减少的偏好优化,且仅使用完全开源的语料库。在MMSU、MMAU和MMAR上的实验表明,DIFFA-2始终优于DIFFA,并在实际训练预算下与强大的AR LALM 具有竞争力,这表明基于扩散的建模是大规模音频理解的可行主干。
🔬 方法详解
问题定义:现有自回归(AR)音频大语言模型(LALM)在扩展时面临数据和计算成本高昂的问题,并且其固有的顺序解码方式限制了推理效率,难以满足实际应用的需求。因此,需要一种更高效、更经济的音频理解模型。
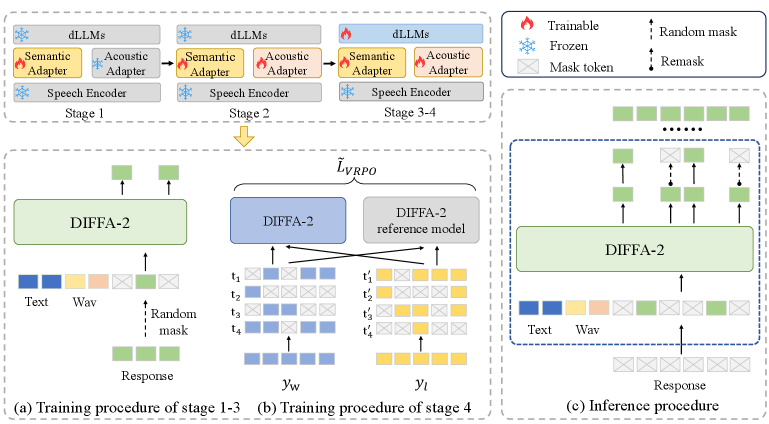
核心思路:DIFFA-2的核心思路是利用扩散模型(Diffusion Model)替代传统的自回归模型作为LALM的主干。扩散模型具有生成能力强、训练数据需求相对较低的优点。通过将音频理解任务转化为扩散模型的生成过程,可以更有效地利用有限的训练数据,并有望提高推理效率。此外,引入双适配器(Dual Adapters)来更好地融合语义和声学信息。
技术框架:DIFFA-2的整体框架包括以下几个主要模块:1) 语音编码器:用于将原始音频信号转换为高维特征表示。2) 双适配器:包括语义适配器和声学适配器,分别用于提取和融合音频的语义和声学信息。3) 扩散模型:作为LALM的主干,负责将音频特征转换为文本表示。4) 四阶段训练课程:包括语义和声学对齐、大规模监督微调和方差减少的偏好优化。
关键创新:DIFFA-2的关键创新在于:1) 采用扩散模型作为LALM的主干,这与传统的自回归模型不同,有望提高训练效率和推理速度。2) 引入双适配器,可以更有效地融合音频的语义和声学信息,从而提高音频理解的准确性。3) 设计了一个四阶段训练课程,可以逐步优化模型的性能,使其在各种音频理解任务中表现出色。
关键设计:DIFFA-2的关键设计包括:1) 语音编码器的选择和优化,以提取高质量的音频特征。2) 语义适配器和声学适配器的结构设计,以有效地提取和融合语义和声学信息。3) 扩散模型的参数设置和训练策略,以保证生成文本的质量和多样性。4) 四阶段训练课程的具体实现,包括每个阶段的目标函数、训练数据和优化算法。
🖼️ 关键图片
📊 实验亮点
DIFFA-2在MMSU、MMAU和MMAR等音频理解数据集上进行了实验,结果表明DIFFA-2始终优于DIFFA,并在实际训练预算下与强大的AR LALM 具有竞争力。这些结果表明,基于扩散的建模是大规模音频理解的可行主干,为未来的研究提供了新的方向。
🎯 应用场景
DIFFA-2在语音助手、智能客服、音频内容分析等领域具有广泛的应用前景。它可以用于识别语音指令、理解音频内容、生成音频描述等。该研究的实际价值在于提供了一种更高效、更经济的音频理解解决方案,有望推动音频智能技术的发展。未来,DIFFA-2可以进一步扩展到多语言音频理解、音频生成等领域。
📄 摘要(原文)
Autoregressive (AR) large audio language models (LALMs) such as Qwen-2.5-Omni have achieved strong performance on audio understanding and interaction, but scaling them remains costly in data and computation, and strictly sequential decoding limits inference efficiency. Diffusion large language models (dLLMs) have recently been shown to make effective use of limited training data, and prior work on DIFFA indicates that replacing an AR backbone with a diffusion counterpart can substantially improve audio understanding under matched settings, albeit at a proof-of-concept scale without large-scale instruction tuning, preference alignment, or practical decoding schemes. We introduce DIFFA-2, a practical diffusion-based LALM for general audio understanding. DIFFA-2 upgrades the speech encoder, employs dual semantic and acoustic adapters, and is trained with a four-stage curriculum that combines semantic and acoustic alignment, large-scale supervised fine-tuning, and variance-reduced preference optimization, using only fully open-source corpora. Experiments on MMSU, MMAU, and MMAR show that DIFFA-2 consistently improves over DIFFA and is competitive to strong AR LALMs under practical training budgets, supporting diffusion-based modeling is a viable backbone for large-scale audio understanding. Our code is available at https://github.com/NKU-HLT/DIFFA.git.