InstructDiff: Domain-Adaptive Data Selection via Differential Entropy for Efficient LLM Fine-Tuning
作者: Junyou Su, He Zhu, Xiao Luo, Liyu Zhang, Hong-Yu Zhou, Yun Chen, Peng Li, Yang Liu, Guanhua Chen
分类: cs.CL
发布日期: 2026-01-30
💡 一句话要点
InstructDiff:通过差分熵进行领域自适应数据选择,高效微调大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 监督微调 数据选择 差分熵 领域自适应
📋 核心要点
- 现有大语言模型微调的数据选择方法缺乏领域泛化性,在不同任务上表现不稳定。
- InstructDiff通过计算基础模型和微调模型之间的差分熵,自适应地选择数据,实现跨领域优化。
- 实验表明,InstructDiff仅使用10%的数据,在数学推理和通用指令任务上分别提升了17%和52%的性能。
📝 摘要(中文)
监督微调(SFT)是调整大型语言模型的基础,然而在完整数据集上训练会产生过高的成本,且收益递减。现有的数据选择方法存在严重的领域特异性:为通用指令遵循优化的技术在推理任务上失败,反之亦然。我们观察到,测量基础模型和最小指令调优校准模型之间的熵差揭示了一种模式——差分熵最低的样本始终在各个领域产生最佳性能,但这一原则以领域自适应的方式体现:推理任务偏爱熵增(认知扩展),而通用任务偏爱熵减(认知压缩)。我们引入了InstructDiff,这是一个统一的框架,通过热身校准、双向NLL过滤和基于熵的排序,将差分熵作为领域自适应的选择标准进行操作。大量实验表明,InstructDiff在数学推理方面比完整数据训练提高了17%的相对性能,在通用指令遵循方面提高了52%,优于先前的基线,同时仅使用了10%的数据。
🔬 方法详解
问题定义:现有的大语言模型微调方法在数据选择上存在领域特异性问题。针对通用指令遵循任务优化后的数据选择策略,在推理任务上表现不佳,反之亦然。这导致需要针对不同类型的任务分别设计数据选择策略,增加了微调的复杂性和成本。
核心思路:InstructDiff的核心思路是利用差分熵作为领域自适应的数据选择标准。通过比较基础模型和经过少量指令微调后的模型在每个样本上的熵值差异,来判断该样本对于特定任务的价值。推理任务倾向于选择熵增的样本(认知扩展),而通用任务倾向于选择熵减的样本(认知压缩)。
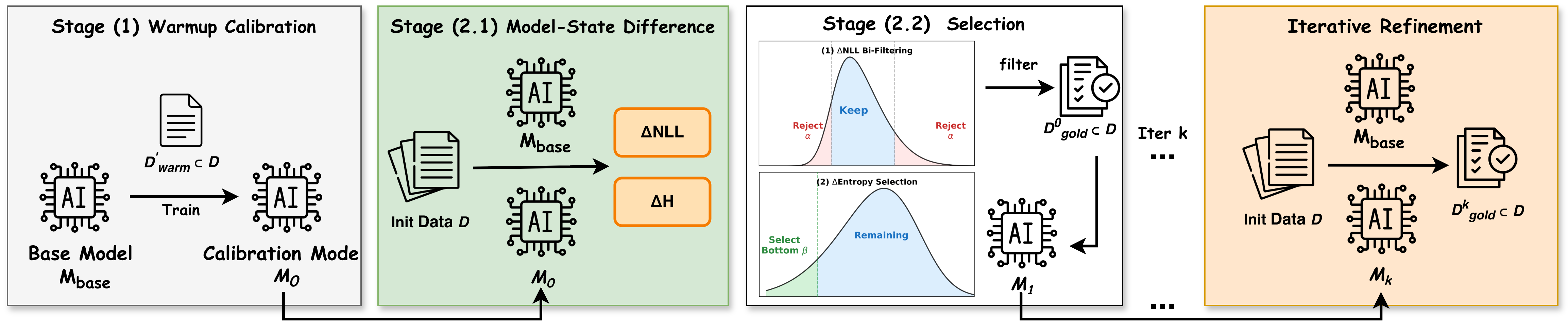
技术框架:InstructDiff包含三个主要阶段:1) 热身校准:使用少量数据对基础模型进行初步的指令微调,得到校准模型。2) 双向NLL过滤:计算基础模型和校准模型在每个样本上的负对数似然(NLL),并进行双向过滤,去除NLL过高或过低的样本。3) 基于熵的排序:计算剩余样本的差分熵,并根据差分熵的大小进行排序,选择熵值最低的样本用于最终的微调。
关键创新:InstructDiff的关键创新在于提出了差分熵作为领域自适应的数据选择标准。与以往依赖单一指标或启发式规则的数据选择方法不同,InstructDiff能够根据任务的特性自动调整数据选择策略,从而实现跨领域的优化。
关键设计:InstructDiff的关键设计包括:1) 使用少量数据进行热身校准,以获得更准确的差分熵估计。2) 采用双向NLL过滤,去除噪声数据和异常值。3) 根据任务类型选择合适的差分熵计算方式(例如,推理任务可能需要更关注熵增的样本)。具体的参数设置(如NLL过滤的阈值、选择的数据比例等)需要根据实际情况进行调整。
🖼️ 关键图片


📊 实验亮点
InstructDiff在数学推理和通用指令遵循任务上取得了显著的性能提升。在数学推理任务上,InstructDiff比完整数据训练提高了17%的相对性能;在通用指令遵循任务上,InstructDiff提高了52%的相对性能。更重要的是,InstructDiff仅使用了10%的数据,证明了其高效的数据选择能力。
🎯 应用场景
InstructDiff可应用于各种需要对大语言模型进行微调的场景,例如特定领域的文本生成、问答系统、对话机器人等。通过高效的数据选择,InstructDiff能够显著降低微调成本,提高模型性能,加速大语言模型在实际应用中的部署。
📄 摘要(原文)
Supervised fine-tuning (SFT) is fundamental to adapting large language models, yet training on complete datasets incurs prohibitive costs with diminishing returns. Existing data selection methods suffer from severe domain specificity: techniques optimized for general instruction-following fail on reasoning tasks, and vice versa. We observe that measuring entropy differences between base models and minimally instruction-tuned calibrated models reveals a pattern -- samples with the lowest differential entropy consistently yield optimal performance across domains, yet this principle manifests domain-adaptively: reasoning tasks favor entropy increase (cognitive expansion), while general tasks favor entropy decrease (cognitive compression). We introduce InstructDiff, a unified framework that operationalizes differential entropy as a domain-adaptive selection criterion through warmup calibration, bi-directional NLL filtering, and entropy-based ranking. Extensive experiments show that InstructDiff achieves 17\% relative improvement over full data training on mathematical reasoning and 52\% for general instruction-following, outperforming prior baselines while using only 10\% of the data.