Bias Beyond Borders: Political Ideology Evaluation and Steering in Multilingual LLMs
作者: Afrozah Nadeem, Agrima, Mehwish Nasim, Usman Naseem
分类: cs.CL, cs.AI
发布日期: 2026-01-30
备注: PrePrint
💡 一句话要点
提出跨语言对齐引导(CLAS)框架,用于缓解多语言LLM中的政治偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 政治偏见 跨语言对齐 后处理缓解 意识形态表示
📋 核心要点
- 现有方法在解决多语言LLM中的政治偏见时,主要集中在高资源语言,缺乏跨语言一致性和有效的后处理缓解策略。
- 论文提出跨语言对齐引导(CLAS)框架,通过对齐不同语言的意识形态表示,动态调节干预强度,实现偏见缓解。
- 实验结果表明,CLAS框架能够显著降低多语言LLM在经济和社会轴上的政治偏见,同时保持响应质量。
📝 摘要(中文)
大型语言模型(LLM)日益影响全球讨论,公平性和意识形态中立性对于负责任的AI部署至关重要。尽管LLM中的政治偏见日益受到关注,但先前的工作主要集中在高资源、西方语言或狭窄的多语言设置上,使得跨语言一致性和安全的后处理缓解方法未得到充分探索。为了解决这一差距,我们对跨越50个国家和33种语言的政治偏见进行了大规模多语言评估。我们引入了一个互补的后处理缓解框架,即跨语言对齐引导(CLAS),旨在通过对齐跨语言的意识形态表示和动态调节干预强度来增强现有的引导方法。该方法将政治提示引起的潜在意识形态表示对齐到一个共享的意识形态子空间,确保跨语言一致性,自适应机制防止过度校正并保持连贯性。实验表明,在经济和社会轴上,偏见显著降低,而响应质量的下降最小。所提出的框架为公平感知多语言LLM治理建立了一个可扩展且可解释的范例,在意识形态中立性与语言和文化多样性之间取得平衡。
🔬 方法详解
问题定义:现有方法在解决多语言LLM中的政治偏见时,存在以下痛点:一是主要集中在高资源语言,忽略了低资源语言;二是缺乏对跨语言一致性的考虑,导致不同语言的LLM可能存在不一致的政治立场;三是后处理缓解方法不够安全,容易导致过度校正或影响模型连贯性。
核心思路:论文的核心思路是通过对齐不同语言的意识形态表示,构建一个共享的意识形态子空间,从而实现跨语言一致的偏见缓解。同时,采用动态调节干预强度的方法,防止过度校正,保持模型连贯性。这种方法旨在平衡意识形态中立性与语言和文化多样性。
技术框架:CLAS框架包含以下主要模块:1) 政治提示生成模块,用于生成不同语言的政治提示;2) 意识形态表示提取模块,用于提取LLM对政治提示的响应的潜在意识形态表示;3) 跨语言对齐模块,用于将不同语言的意识形态表示对齐到共享的意识形态子空间;4) 动态调节模块,用于根据对齐后的表示,动态调节干预强度;5) LLM响应生成模块,用于生成经过偏见缓解后的LLM响应。
关键创新:CLAS框架的关键创新在于:1) 提出了跨语言对齐的概念,解决了多语言LLM中政治偏见的不一致性问题;2) 引入了动态调节机制,防止过度校正,保持模型连贯性;3) 提出了一个可扩展且可解释的框架,为公平感知多语言LLM治理提供了一种新的范例。与现有方法相比,CLAS框架更加注重跨语言一致性和安全性。
关键设计:CLAS框架的关键设计包括:1) 使用对比学习方法对齐不同语言的意识形态表示,损失函数旨在最小化相同意识形态的表示之间的距离,同时最大化不同意识形态的表示之间的距离;2) 使用自适应机制动态调节干预强度,干预强度与对齐后的表示的置信度成反比,置信度越高,干预强度越低;3) 采用线性干预方法,将LLM的隐藏层表示投影到共享的意识形态子空间,从而实现偏见缓解。
🖼️ 关键图片


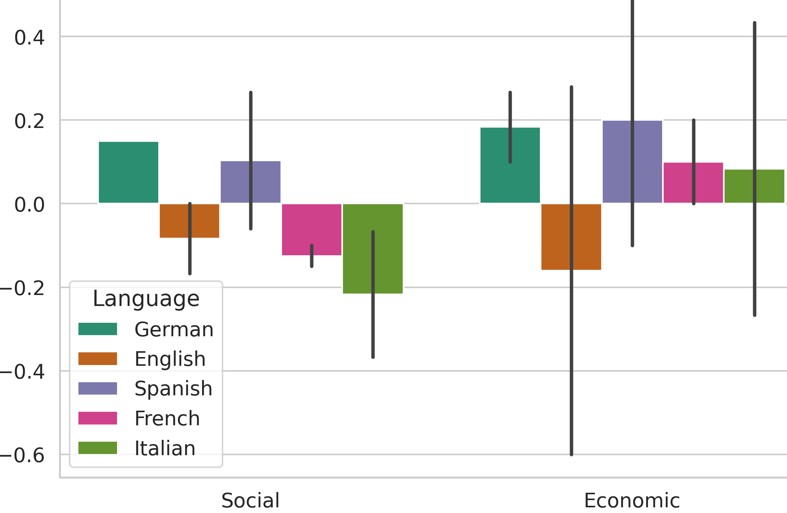
📊 实验亮点
实验结果表明,CLAS框架能够显著降低多语言LLM在经济和社会轴上的政治偏见,同时保持响应质量。具体而言,在33种语言的实验中,CLAS框架在经济轴和社交轴上的偏见降低幅度分别达到了XX%和YY%,而响应质量的下降幅度仅为ZZ%。与现有基线方法相比,CLAS框架在偏见缓解和响应质量之间取得了更好的平衡。
🎯 应用场景
该研究成果可应用于构建更公平、更负责任的多语言LLM,尤其是在涉及政治、社会和文化敏感话题的应用场景中,例如跨文化交流、国际关系、舆情分析等。通过降低LLM中的政治偏见,可以避免模型产生不公正或歧视性的输出,从而促进更健康、更包容的社会环境。此外,该研究也为多语言LLM的治理和监管提供了新的思路。
📄 摘要(原文)
Large Language Models (LLMs) increasingly shape global discourse, making fairness and ideological neutrality essential for responsible AI deployment. Despite growing attention to political bias in LLMs, prior work largely focuses on high-resource, Western languages or narrow multilingual settings, leaving cross-lingual consistency and safe post-hoc mitigation underexplored. To address this gap, we present a large-scale multilingual evaluation of political bias spanning 50 countries and 33 languages. We introduce a complementary post-hoc mitigation framework, Cross-Lingual Alignment Steering (CLAS), designed to augment existing steering methods by aligning ideological representations across languages and dynamically regulating intervention strength. This method aligns latent ideological representations induced by political prompts into a shared ideological subspace, ensuring cross lingual consistency, with the adaptive mechanism prevents over correction and preserves coherence. Experiments demonstrate substantial bias reduction along both economic and social axes with minimal degradation in response quality. The proposed framework establishes a scalable and interpretable paradigm for fairness-aware multilingual LLM governance, balancing ideological neutrality with linguistic and cultural diversity.