A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training
作者: Zihan Qiu, Zeyu Huang, Kaiyue Wen, Peng Jin, Bo Zheng, Yuxin Zhou, Haofeng Huang, Zekun Wang, Xiao Li, Huaqing Zhang, Yang Xu, Haoran Lian, Siqi Zhang, Rui Men, Jianwei Zhang, Ivan Titov, Dayiheng Liu, Jingren Zhou, Junyang Lin
分类: cs.CL
发布日期: 2026-01-30
💡 一句话要点
揭示Transformer训练中Outlier驱动的重缩放机制,提升模型性能与量化鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 注意力机制 残差连接 异常值 重缩放 量化 大型语言模型
📋 核心要点
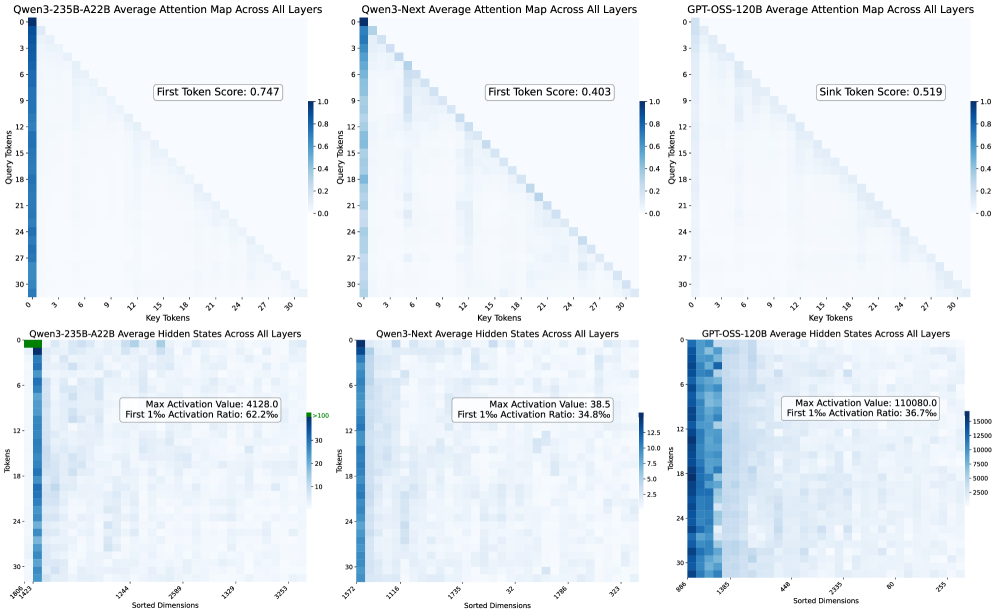
- 现有Transformer模型训练中存在注意力汇和残差汇等异常值,其作用机制尚不明确,影响模型性能。
- 论文提出“异常值驱动的重缩放”机制,认为异常值与归一化层共同作用,对非异常值进行重缩放,维持训练稳定。
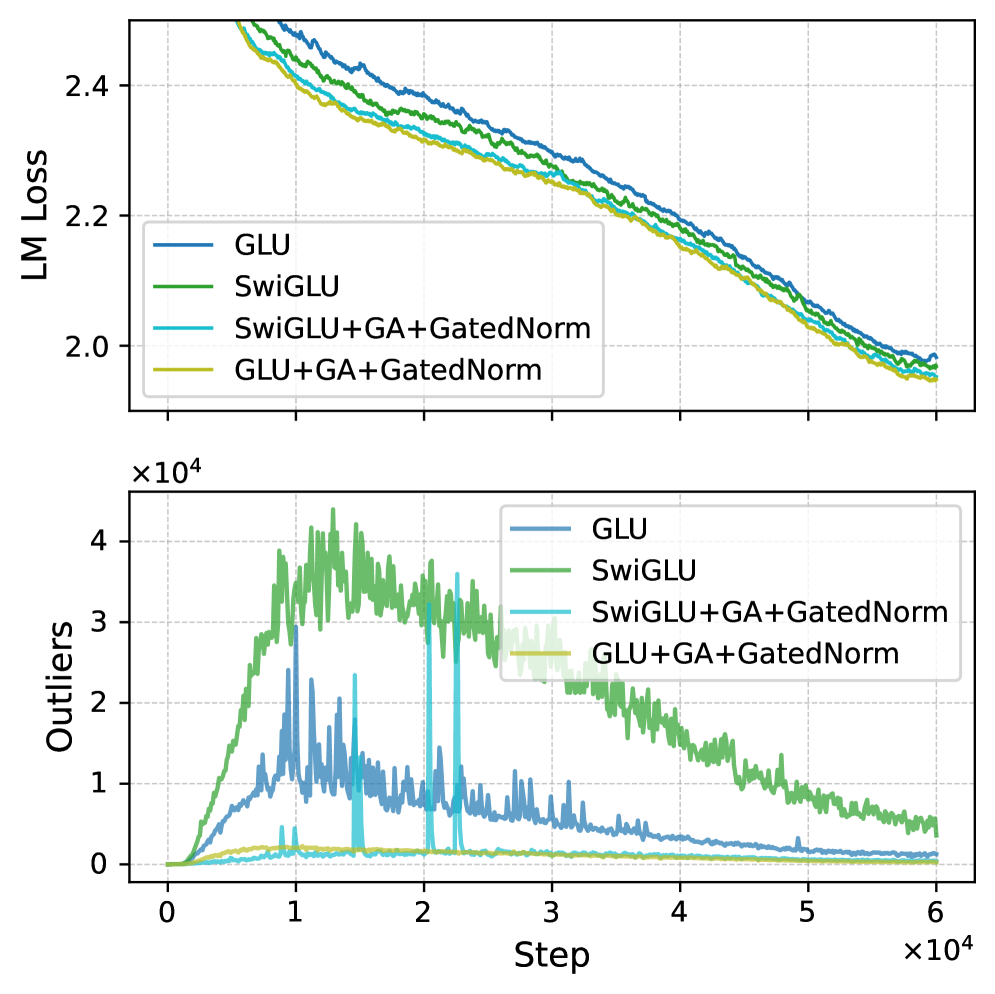
- 实验表明,通过吸收或缓解异常值,可以提升模型训练性能和量化鲁棒性,平均提升2个点,量化鲁棒性提升1.2个点。
📝 摘要(中文)
本文研究了大型语言模型中涌现的异常值的功能作用,特别是注意力汇(少数几个持续接收大量注意力logits的token)和残差汇(少数几个在大多数token中具有持续大量激活值的固定维度)。我们假设这些异常值与相应的归一化(例如,softmax注意力和RMSNorm)一起,有效地重新缩放其他非异常值组件。我们将这种现象称为“异常值驱动的重缩放”,并在不同的模型架构和训练token数量上验证了这一假设。这种观点统一了两种汇类型的起源和缓解方法。我们的主要结论和观察包括:(1)异常值与归一化共同起作用:移除归一化会消除相应的异常值,但会降低训练稳定性和性能;直接裁剪异常值同时保留归一化会导致性能下降,表明异常值驱动的重缩放有助于训练稳定性。(2)异常值更多地充当重缩放因子,而不是贡献者,因为注意力汇和残差汇的最终贡献远小于非异常值。(3)异常值可以被吸收到可学习的参数中,或者通过显式的门控重缩放来缓解,从而提高训练性能(平均增益2个点)并增强量化鲁棒性(W4A4量化下降低1.2个点)。
🔬 方法详解
问题定义:Transformer模型在训练过程中会出现注意力汇(Attention Sinks)和残差汇(Residual Sinks)等异常值现象。这些异常值指的是少数几个token持续接收大量的注意力logits,或者少数几个维度在大多数token中具有持续的大量激活值。现有方法对这些异常值的理解和处理不足,可能影响模型的训练稳定性和最终性能。论文旨在深入理解这些异常值的作用机制,并提出有效的缓解策略。
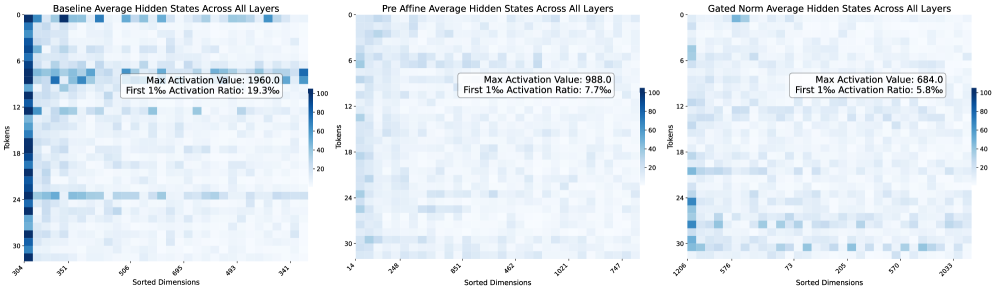
核心思路:论文的核心思路是提出“异常值驱动的重缩放”机制。作者认为,这些异常值并非简单的噪声,而是与模型中的归一化层(如Softmax和RMSNorm)共同作用,对其他非异常值成分进行重缩放。这种重缩放有助于维持训练的稳定性和模型的表达能力。通过理解这种机制,可以更好地设计模型结构和训练策略,从而提升模型性能。
技术框架:论文的研究框架主要包括以下几个方面:1) 观察和分析Transformer模型中注意力汇和残差汇的现象;2) 提出“异常值驱动的重缩放”假设,并通过实验验证该假设;3) 研究不同的缓解异常值的方法,包括将异常值吸收到可学习参数中,以及使用显式的门控重缩放;4) 在不同的模型架构和数据集上进行实验,评估这些方法的有效性。
关键创新:论文最重要的技术创新点在于提出了“异常值驱动的重缩放”机制。与以往将异常值视为噪声或需要消除的干扰因素不同,论文认为异常值在Transformer模型的训练中扮演着重要的角色,它们与归一化层共同作用,对非异常值进行重缩放,从而维持训练的稳定性和模型的表达能力。这种新的视角为理解和处理Transformer模型中的异常值提供了新的思路。
关键设计:论文的关键设计包括:1) 通过实验验证异常值与归一化层之间的相互作用,例如,移除归一化层会导致异常值消失,但会降低训练的稳定性和性能;2) 设计不同的缓解异常值的方法,包括将异常值吸收到可学习参数中,以及使用显式的门控重缩放;3) 使用W4A4量化来评估模型的量化鲁棒性,并验证缓解异常值的方法可以提高模型的量化鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,异常值与归一化共同起作用,移除归一化会消除异常值但降低性能。通过吸收或缓解异常值,可以提升模型训练性能(平均增益2个点)并增强量化鲁棒性(W4A4量化下降低1.2个点)。这些结果验证了“异常值驱动的重缩放”机制的有效性。
🎯 应用场景
该研究成果可应用于各种基于Transformer的大型语言模型,例如机器翻译、文本生成、对话系统等。通过理解和缓解异常值,可以提高模型的训练效率、稳定性和最终性能,并增强模型的量化鲁棒性,降低部署成本。该研究对于优化模型结构和训练策略具有重要的指导意义。
📄 摘要(原文)
We investigate the functional role of emergent outliers in large language models, specifically attention sinks (a few tokens that consistently receive large attention logits) and residual sinks (a few fixed dimensions with persistently large activations across most tokens). We hypothesize that these outliers, in conjunction with the corresponding normalizations (\textit{e.g.}, softmax attention and RMSNorm), effectively rescale other non-outlier components. We term this phenomenon \textit{outlier-driven rescaling} and validate this hypothesis across different model architectures and training token counts. This view unifies the origin and mitigation of both sink types. Our main conclusions and observations include: (1) Outliers function jointly with normalization: removing normalization eliminates the corresponding outliers but degrades training stability and performance; directly clipping outliers while retaining normalization leads to degradation, indicating that outlier-driven rescaling contributes to training stability. (2) Outliers serve more as rescale factors rather than contributors, as the final contributions of attention and residual sinks are significantly smaller than those of non-outliers. (3) Outliers can be absorbed into learnable parameters or mitigated via explicit gated rescaling, leading to improved training performance (average gain of 2 points) and enhanced quantization robustness (1.2 points degradation under W4A4 quantization).