LLMs Explain't: A Post-Mortem on Semantic Interpretability in Transformer Models
作者: Alhassan Abdelhalim, Janick Edinger, Sören Laue, Michaela Regneri
分类: cs.CL, cs.LG
发布日期: 2026-01-30
💡 一句话要点
探讨LLMs的语义可解释性问题及其局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 语义理解 注意力机制 特征映射 普适计算 模型调试
📋 核心要点
- 现有的LLMs可解释性方法存在局限,无法有效揭示模型的理解机制。
- 论文通过探测和特征映射的方法,旨在分析LLMs中语言抽象的形成。
- 实验结果表明,现有可解释性技术的结论并不可靠,影响其在实际应用中的有效性。
📝 摘要(中文)
大型语言模型(LLMs)因其多功能性和强大性能在普适计算中越来越受欢迎。然而,尽管它们的使用越来越普遍,其卓越性能背后的具体机制仍不清晰。本文探讨了LLMs中语言抽象的形成,尝试通过探测令牌级关系结构和特征映射来检测不同模块的可解释性。结果显示,这些方法因方法论问题而失败,表明现有的可解释性技术并不能有效反映LLMs的理解能力,尤其在普适计算环境中,这一发现具有重要意义。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLMs)可解释性不足的问题,现有方法未能有效揭示模型的理解机制,导致对其性能的误解。
核心思路:通过探测令牌级关系结构和特征映射的方法,分析LLMs中语言抽象的形成,尝试揭示不同模块的可解释性。
技术框架:研究采用了两种主要方法:第一,探测令牌级关系结构以理解模型的内部表示;第二,利用特征映射技术分析嵌入的可解释性。
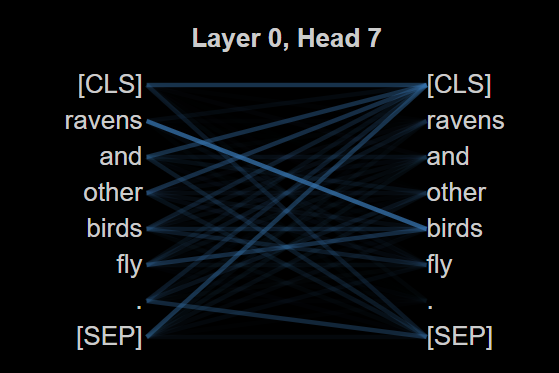
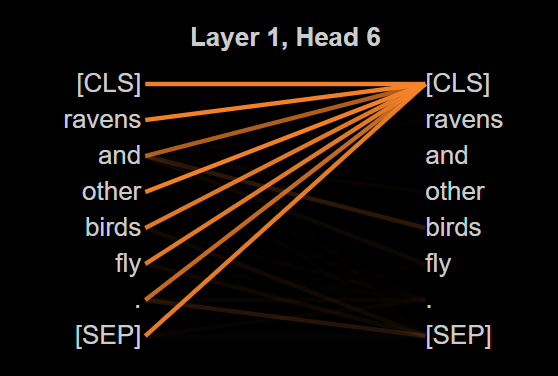
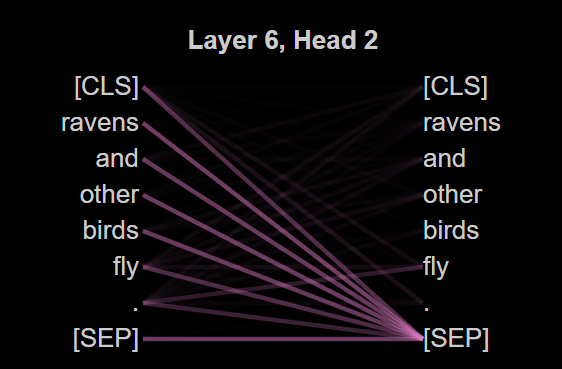
关键创新:本文的创新在于揭示了现有可解释性技术的局限性,特别是注意力机制的假设在后层表示中并不成立,挑战了传统的理解方式。
关键设计:实验中使用了标准的探测和特征映射方法,但发现高预测分数是由方法论伪影和数据集结构驱动,而非真正的语义知识。通过这些发现,强调了对可解释性技术的重新审视。
🖼️ 关键图片
📊 实验亮点
实验结果显示,注意力机制的解释在核心假设下崩溃,特征映射方法的高预测分数并未反映真实的语义知识。这些发现表明,现有的可解释性技术并不能有效支持LLMs的理解能力,提示研究者在使用这些技术时需谨慎。
🎯 应用场景
该研究的潜在应用领域包括普适计算、模型调试和压缩等。通过揭示现有可解释性方法的局限性,研究为未来开发更有效的可解释性技术提供了重要的理论基础,可能会影响LLMs在实际应用中的信任度和可靠性。
📄 摘要(原文)
Large Language Models (LLMs) are becoming increasingly popular in pervasive computing due to their versatility and strong performance. However, despite their ubiquitous use, the exact mechanisms underlying their outstanding performance remain unclear. Different methods for LLM explainability exist, and many are, as a method, not fully understood themselves. We started with the question of how linguistic abstraction emerges in LLMs, aiming to detect it across different LLM modules (attention heads and input embeddings). For this, we used methods well-established in the literature: (1) probing for token-level relational structures, and (2) feature-mapping using embeddings as carriers of human-interpretable properties. Both attempts failed for different methodological reasons: Attention-based explanations collapsed once we tested the core assumption that later-layer representations still correspond to tokens. Property-inference methods applied to embeddings also failed because their high predictive scores were driven by methodological artifacts and dataset structure rather than meaningful semantic knowledge. These failures matter because both techniques are widely treated as evidence for what LLMs supposedly understand, yet our results show such conclusions are unwarranted. These limitations are particularly relevant in pervasive and distributed computing settings where LLMs are deployed as system components and interpretability methods are relied upon for debugging, compression, and explaining models.